【强化学习中的PPO算法】:原理、实现和应用详解
发布时间: 2024-08-22 00:37:28 阅读量: 63 订阅数: 22 
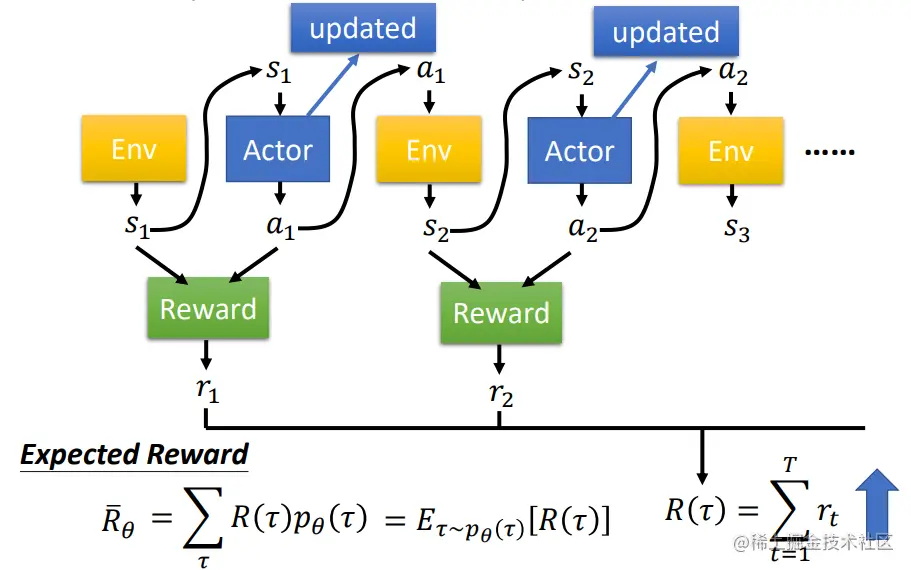
# 1. 强化学习中的PPO算法概述
强化学习是一种机器学习方法,它允许代理通过与环境交互来学习最佳行动策略。近端策略优化(PPO)算法是一种流行的强化学习算法,它通过优化代理策略的近端目标来训练代理。与其他强化学习算法相比,PPO算法具有稳定性高、收敛速度快、样本效率高等优点。
PPO算法的核心思想是使用近端策略优化方法。它通过最小化代理当前策略和目标策略之间的差异来更新策略。目标策略是根据代理过去经验计算出的,而当前策略是代理在当前状态下采取行动的策略。通过最小化这两个策略之间的差异,PPO算法可以确保代理的策略在学习过程中不会发生剧烈变化,从而提高算法的稳定性。
# 2. PPO算法的理论基础
### 2.1 强化学习的基本概念
强化学习是一种机器学习范式,其中代理通过与环境交互来学习最佳行为策略。代理根据其在环境中采取的行动获得奖励或惩罚,并根据这些反馈调整其行为。
强化学习的三个关键要素包括:
- **代理:**执行动作并与环境交互的实体。
- **环境:**代理所在的世界,提供状态和奖励。
- **奖励函数:**衡量代理行为的函数,提供正向或负向反馈。
### 2.2 策略梯度定理
策略梯度定理是强化学习中一个重要的理论概念,它提供了计算策略梯度的公式,即策略对目标函数的梯度。策略梯度用于指导代理更新其行为策略,以最大化奖励。
策略梯度定理的公式如下:
```
∇_θ J(θ) = E[∇_θ log π(a|s) Q(s, a)]
```
其中:
- θ:策略参数
- J(θ):目标函数(通常为期望奖励)
- π(a|s):策略,给定状态 s 时采取动作 a 的概率
- Q(s, a):动作-价值函数,表示在状态 s 下采取动作 a 的期望未来奖励
### 2.3 PPO算法的原理和优势
近端策略优化(PPO)算法是一种策略梯度算法,它通过限制策略更新的步长来提高策略梯度方法的稳定性。PPO算法通过以下步骤实现:
1. **收集数据:**代理与环境交互,收集状态-动作-奖励三元组。
2. **计算优势函数:**优势函数衡量每个动作的价值,高于策略在该状态下采取的平均动作。
3. **更新策略:**使用策略梯度定理更新策略参数,但限制更新步长,以防止策略发生剧烈变化。
4. **剪辑:**对策略更新进行剪辑,以确保更新步长不超过预定义的阈值。
PPO算法的优势包括:
- **稳定性:**通过限制策略更新步长,PPO算法提高了策略梯度方法的稳定性。
- **效率:**PPO算法通过使用优势函数来指导策略更新,提高了训练效率。
- **并行性:**PPO算法可以并行化,从而提高训练速度。
# 3.1 算法流程和伪代码
PPO算法的流程主要包括以下几个步骤:
1. **收集经验数据:**在环境中执行策略π,收集状态-动作-奖励序列{(s_t, a_t, r_t)}。
2. **计算优势函数:**使用优势函数A(s, a)评估每个状态-动作对的优势,表示该动作比策略π在该状态下采取其他动作的期望收益高的程度。
3. **更新策略:**使用策略梯度定理更新策略参数,使优势函数较高的动作的概率增加,而优势函数较低的动作的概率降低。
4. **更新价值函数:**使用价值函数V(s)估计每个状态的期望回报,并使用均方误差(MSE)最小化更新价值函数。
PPO算法的伪代码如下:
```python
初始化策略参数θ
初始化价值函数参数φ
for episode in num_episodes:
收集经验数据{(s_t, a_t, r_t)}
计算优势函数A(s, a)
更新策略参数θ
更新价值函数参数φ
```
### 3.2 PPO算法的超参数设置
PPO算法的超参数包括:
* **步长大小:**控制策略参数更新的幅度。
* **剪辑范围:**限制策略更新的范围,防止策略发生剧烈变化。
* **优势函数类型:**用于计算优势函数的函数类型,如GAE(广义优势估计)。
* **价值函数学习率:**控制价值函数更新的速率。
* **批次大小:**用于更新策略和价值函数的经验数据的批次大小。
超参数的设置需要根据具体的任务和环境进行调整。一般来说,较小的步长大小和剪辑范围可以提高算法的稳定性,但可能会降低收敛速度。较大的优势函数学习率可以加快价值函数的更新,但可能会导致价值函数估计不准确。
### 3.3 PPO算法的代码实现
PPO算法的代码实现可以参考以下代码块:
```python
import numpy as np
import tensorflow as tf
class PPO:
def __init__(self, env, actor_lr, critic_lr, gamma, lam):
self.env = env
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.gamma = gamma
self.lam = lam
# 构建策略网络
self.actor = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(env.action_space.n, activation='softmax')
])
# 构建价值网络
self.critic = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1)
])
# 优化器
self.actor_optimizer = tf.keras.optimizers.Adam(learning_rate=actor_lr)
self.critic_optimizer = tf.keras.optimizers.Adam(learning_rate=critic_lr)
def collect_experience(self, num_episodes):
# 收集经验数据
experiences = []
for episode in range(num_episodes):
state = env.reset()
done = False
while not done:
# 根据策略选择动作
action = self.actor(state)
# 执行动作并获取奖励和下一个状态
next_state, reward, done, _ = env.step(action)
# 保存经验数据
experiences.append((state, action, reward, next_state, done))
state = next_state
return experiences
def compute_advantage(self, experiences, lam):
# 计算优势函数
advantages = []
for experience in experiences:
state, action, reward, next_state, done = experience
# 计算价值函数
v = self.critic(state)
v_next = self.critic(next_state)
# 计算优势函数
advantage = reward + self.gamma * (1 - done) * v_next - v
advantages.append(advantage)
return advantages
def update_policy(self, experiences, advantages):
# 更新策略参数
for experience, advantage in zip(experiences, advantages):
state, action, reward, next_state, done = experience
# 计算策略梯度
with tf.GradientTape() as tape:
log_prob = tf.math.log(self.actor(state)[action])
policy_gradient = log_prob * advantage
# 更新策略参数
grads = tape.gradient(policy_gradient, self.actor.trainable_variables)
self.actor_optimizer.apply_gradients(zip(grads, self.actor.trainable_variables))
def update_value_function(self, experiences, advantages):
# 更新价值函数参数
for experience, advantage in zip(experiences, advantages):
state, action, reward, next_state, done = experience
# 计算价值函数目标值
target = reward + self.gamma * (1 - done) * self.critic(next_state)
# 计算价值函数损失
loss = tf.keras.losses.MSE(target, self.critic(state))
# 更新价值函数参数
grads = tf.GradientTape().gradient(loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(zip(grads, self.critic.trainable_variables))
def train(self, num_episodes, batch_size):
# 训练PPO算法
for episode in range(num_episodes):
# 收集经验数据
experiences = self.collect_experience(batch_size)
# 计算优势函数
advantages = self.compute_advantage(experiences, self.lam)
# 更新策略参数
self.update_policy(experiences, advantages)
# 更新价值函数参数
self.update_value_function(experiences, advantages)
```
# 4. PPO算法的应用
### 4.1 连续控制任务
PPO算法在连续控制任务中表现出色,因为它可以有效地处理动作空间连续的情况。以下是一些典型的连续控制任务:
#### 4.1.1 倒立摆控制
倒立摆控制是一个经典的连续控制任务,目标是通过控制摆杆的力矩,使倒立摆保持平衡。PPO算法可以有效地学习到控制摆杆的策略,使倒立摆在受到扰动时也能保持平衡。
```python
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Normal
# 定义策略网络
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.tanh(self.fc3(x))
return x
# 定义价值网络
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.linear(self.fc3(x))
return x
# 定义PPO算法
class PPO:
def __init__(self, actor, critic, env, lr=0.0003, gamma=0.99, lam=0.95, clip_param=0.2, epoch=10):
self.actor = actor
self.critic = critic
self.env = env
self.lr = lr
self.gamma = gamma
self.lam = lam
self.clip_param = clip_param
self.epoch = epoch
self.optimizer_actor = optim.Adam(self.actor.parameters(), lr=self.lr)
self.optimizer_critic = optim.Adam(self.critic.parameters(), lr=self.lr)
def train(self):
# 采样数据
states, actions, rewards, dones = [], [], [], []
for _ in range(self.epoch):
state = self.env.reset()
done = False
while not done:
action = self.actor(state).detach().numpy()
next_state, reward, done, _ = self.env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
dones.append(done)
state = next_state
# 计算优势函数
advantages = []
for i in range(len(rewards)):
advantage = 0
for j in range(i, len(rewards)):
advantage += (self.gamma ** (j - i)) * rewards[j] * (1 - dones[j])
advantage -= (self.gamma ** (j - i)) * self.critic(states[j]).detach().numpy()
advantages.append(advantage)
# 标准化优势函数
advantages = (advantages - np.mean(advantages)) / (np.std(advantages) + 1e-8)
# 更新策略网络
for _ in range(self.epoch):
for i in range(len(states)):
old_log_prob = self.actor(states[i]).log_prob(actions[i]).detach().numpy()
new_log_prob = self.actor(states[i]).log_prob(actions[i]).numpy()
ratio = np.exp(new_log_prob - old_log_prob)
surrogate1 = ratio * advantages[i]
surrogate2 = torch.clamp(ratio, 1 - self.clip_param, 1 + self.clip_param) * advantages[i]
actor_loss = -torch.min(surrogate1, surrogate2).mean()
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step()
# 更新价值网络
for _ in range(self.epoch):
for i in range(len(states)):
value = self.critic(states[i]).detach().numpy()
td_error = rewards[i] + self.gamma * value * (1 - dones[i]) - value
critic_loss = td_error ** 2
self.optimizer_critic.zero_grad()
critic_loss.backward()
self.optimizer_critic.step()
# 训练PPO算法
env = gym.make('InvertedPendulum-v2')
actor = Actor(env.observation_space.shape[0], env.action_space.shape[0])
critic = Critic(env.observation_space.shape[0])
ppo = PPO(actor, critic, env)
ppo.train()
```
#### 4.1.2 机器人运动控制
机器人运动控制也是一个典型的连续控制任务,目标是通过控制机器人的关节角度,使机器人执行特定的动作。PPO算法可以有效地学习到控制机器人的策略,使机器人能够完成复杂的运动任务。
### 4.2 离散控制任务
PPO算法也可以应用于离散控制任务,但需要对策略网络进行一定的修改。以下是一些典型的离散控制任务:
#### 4.2.1 游戏AI
游戏AI是离散控制任务的一个典型应用,目标是通过控制游戏角色的动作,使游戏角色完成特定的游戏目标。PPO算法可以有效地学习到控制游戏角色的策略,使游戏角色能够在游戏中取得更好的成绩。
#### 4.2.2 推荐系统
推荐系统也是一个离散控制任务,目标是通过控制推荐的内容,使用户对推荐内容的满意度最大化。PPO算法可以有效地学习到控制推荐内容的策略,使推荐系统能够为用户提供更加个性化和相关的推荐内容。
# 5.1 PPO算法的变体
### 5.1.1 APPO算法
APPO(Asynchronous Proximal Policy Optimization)算法是PPO算法的异步版本,它允许多个actor并行收集经验,从而提高了训练效率。APPO算法的原理与PPO算法基本相同,但它采用异步更新策略的方式,即每个actor独立更新自己的策略,而不再等待所有actor收集完经验后再统一更新。
### 5.1.2 SAC算法
SAC(Soft Actor-Critic)算法是PPO算法的扩展,它结合了策略梯度和值函数方法。SAC算法通过引入熵正则化项来鼓励策略探索,并使用一个目标值函数网络来稳定训练过程。与PPO算法相比,SAC算法在离散控制任务和连续控制任务上都表现出了更好的性能。
## 5.2 PPO算法的应用拓展
### 5.2.1 多智能体强化学习
PPO算法可以应用于多智能体强化学习中,其中多个智能体相互协作或竞争以实现共同目标。在多智能体强化学习中,PPO算法可以用于训练每个智能体的策略,使其能够与其他智能体协调或对抗。
### 5.2.2 强化学习中的安全约束
PPO算法可以用于强化学习中的安全约束,即在训练过程中限制智能体的行为以满足安全要求。通过在奖励函数中引入惩罚项或使用约束优化方法,PPO算法可以学习满足安全约束的策略。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了强化学习中的 PPO 算法,这是一类强大的策略梯度算法。专栏文章涵盖了 PPO 算法的原理、实现和应用,并提供了详细的示例和代码。此外,还对比了 PPO 算法与其他策略梯度算法,并探讨了其在连续和离散动作空间中的应用。专栏还提供了 PPO 算法在多智能体系统中的应用、超参数调优、常见问题故障排除和工程实践方面的指导。通过深入了解 PPO 算法,读者可以掌握其在强化学习中的强大功能,并将其应用于广泛的应用场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
概率分布计算全攻略:从离散到连续的详细数学推导

# 1. 概率分布基础概述
在统计学和概率论中,概率分布是描述随机变量取值可能性的一张蓝图。理解概率分布是进行数据分析、机器学习和风险评估等诸多领域的基本要求。本章将带您入门概率分布的基础概念。
## 1.1 随机变量及其性质
随机变量是一个可以取不同值的变量,其结果通常受概率影响。例如,掷一枚公平的六面骰子,结果就是随机变量的一个实例。随机变量通常分
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
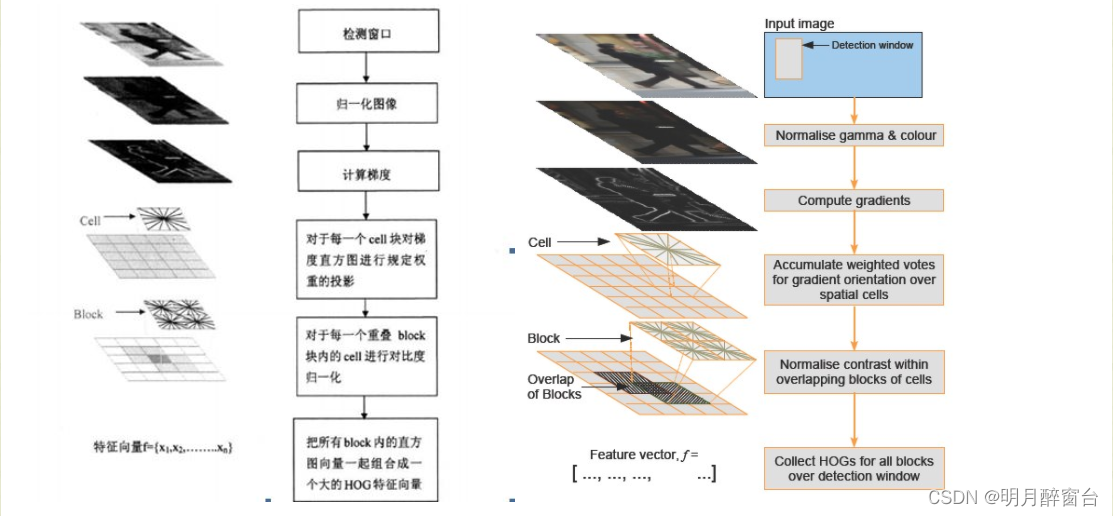
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )