无向图中连通分量的计算与并查集java的关系
发布时间: 2024-04-13 11:46:19 阅读量: 97 订阅数: 31 
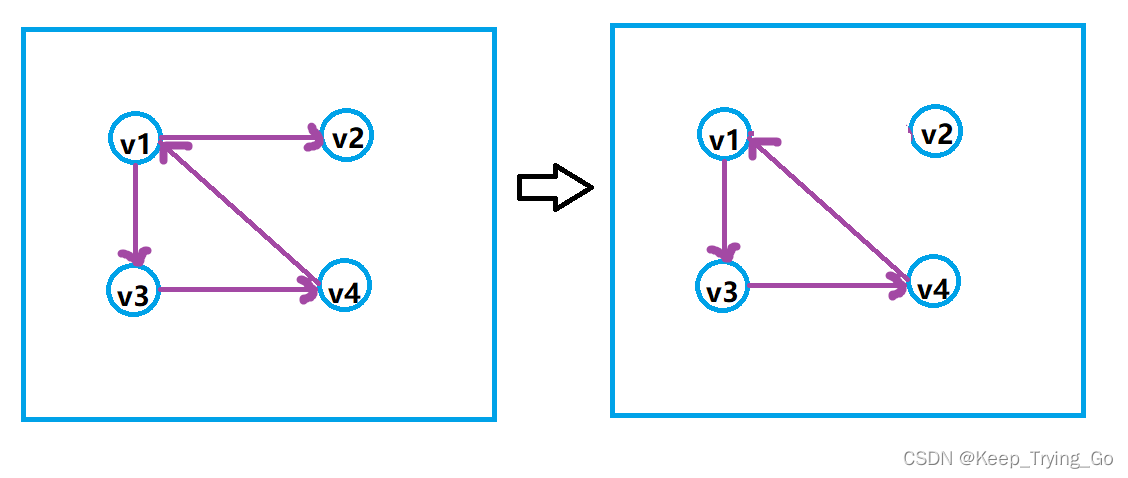
# 1. 图论中的连通性问题
1.1 无向图的基本概念
在图论中,无向图是由若干顶点和边组成的数据结构。顶点之间的边没有方向,因此表示为无序对。无向图可以使用邻接矩阵或邻接表来表示,方便进行遍历算法的实现。
图的遍历算法包括深度优先搜索(DFS)和广度优先搜索(BFS),它们可以用于查找图中的连通分量以及解决各种连通性问题。
1.2 连通图与连通分量
连通图是指图中任意两个顶点之间都存在路径的图。连通分量则是将连通图中相互连通的顶点分为一个集合,每个集合即为一个连通分量。
计算连通分量的方法包括DFS或BFS遍历整个图,并使用并查集来记录顶点之间的关系,以便在查找连通分量时进行快速检索。
# 2. 并查集数据结构
2.1 并查集简介
并查集(Disjoint Set)是一种基于树结构的数据结构,用于处理集合的合并与查询问题。在实际应用中,它通常用于解决元素分组及连通性等问题。并查集的核心操作包括查找(Find)和合并(Union)两种,通过这两种操作可以快速判断元素之间的关联关系,找出所属集合。
**2.1.1 并查集的概念**
并查集中的每个集合都被表示成树结构,其中的每个节点指向其父节点,根节点指向自身。通过路径压缩和按秩合并等优化方式,可以提高并查集的效率,降低树的深度,减少查找操作的时间复杂度。
**2.1.2 并查集的应用场景**
- 社交网络中的好友关系判断
- 电子游戏中的联盟系统
- 区域连通性分析
- 网络中的设备连接状态判断
2.2 并查集的实现
并查集主要有三种实现方式:Quick Find算法、Quick Union算法和加权Quick Union算法。
**2.2.1 Quick Find算法**
Quick Find算法是并查集最简单的实现方式,通过一个数组来维护集合的信息。根据元素所在集合的不同,将数组中对应位置的值进行不同的设置。
```python
class QuickFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, p):
return self.parent[p]
def union(self, p, q):
p_root = self.find(p)
q_root = self.find(q)
if p_root == q_root:
return
for i in range(len(self.parent)):
if self.parent[i] == p_root:
self.parent[i] = q_root
```
**2.2.2 Quick Union算法**
Quick Union算法基于树结构实现,并通过节点之间的父子关系来表示集合间的连接情况。这种实现方式在合并操作时,将一个集合的根节点指向另一个集合的根节点。
```python
class QuickUnion:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, p):
while p != self.parent[p]:
p = self.parent[p]
return p
def union(self, p, q):
p_root = self.find(p)
q_root = self.find(q)
if p_root == q_root:
return
self.parent[p_root] = q_root
```
**2.2.3 加权Quick Union算法**
加权Quick Union算法在Quick Union基础上进行了优化,通过维护每个根节点的子节点数量(权值),在合并操作时总是将节点少的树合并到节点多的树上,以降低树的深度,提高查找效率。
```python
class WeightedQuickUnion:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.size = [1] * n
def find(self, p):
while p != self.parent[p]:
p = self.parent[p]
return p
def union(self, p, q):
p_root = self.find(p)
q_root = self.find(q)
if p_root == q_root:
return
if self.size[p_root] < self.size[q_root]:
self.parent[p_root] = q_root
self.size[q_root] += self.size[p_root]
else:
self.parent[q_root] = p_root
self.size[p_root] += self.size[q_root]
```
2.3 并查集的优

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了并查集数据结构在 Java 中的应用,涵盖了其基本原理、实现方式、优化技巧、环路检测、连通性问题解决、图论算法应用、最小生成树算法实现、快速合并算法、与 Kruskal 算法的结合使用、网络连接问题、社交网络分析、不相交集合处理、大规模数据优化、路径压缩算法优缺点分析、性能问题应对、并行计算应用以及在无向图连通分量计算中的关系。专栏通过一系列详细的文章,系统地介绍了并查集在 Java 中的广泛应用,为读者提供了全面深入的理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【宠物管理系统权限管理】:基于角色的访问控制(RBAC)深度解析
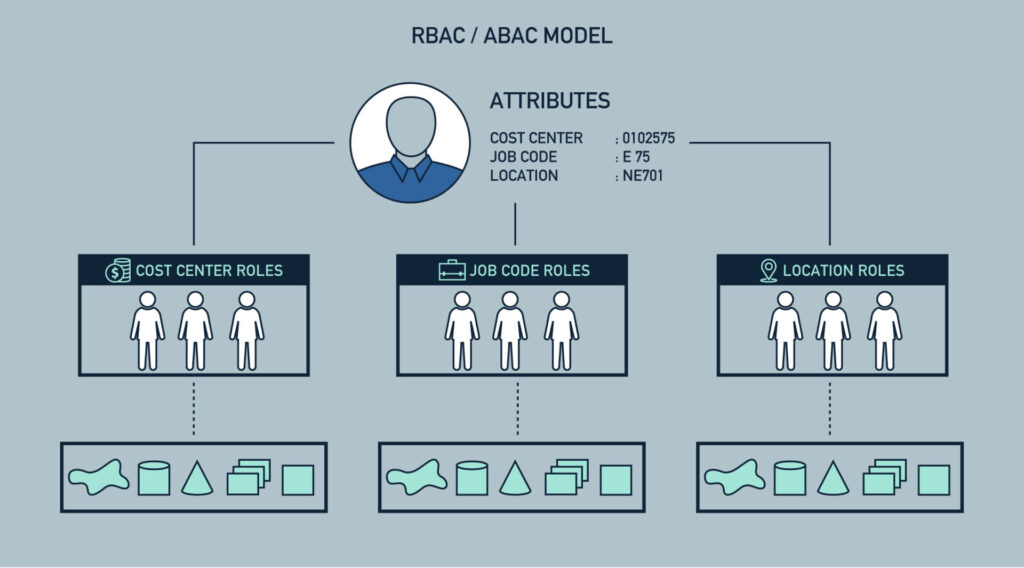
# 1. 基于角色的访问控制(RBAC)概述
在信息技术快速发展的今天,信息安全成为了企业和组织的核心关注点之一。在众多安全措施中,访问控制作为基础环节,保证了数据和系统资源的安全。基于角色的访问控制(Role-Based Access Control, RBAC)是一种广泛
【Python分布式系统精讲】:理解CAP定理和一致性协议,让你在面试中无往不利

# 1. 分布式系统的基础概念
分布式系统是由多个独立的计算机组成,这些计算机通过网络连接在一起,并共同协作完成任务。在这样的系统中,不存在中心化的控制,而是由多个节点共同工作,每个节点可能运行不同的软件和硬件资源。分布式系统的设计目标通常包括可扩展性、容错性、弹性以及高性能。
分布式系统的难点之一是各个节点之间如何协调一致地工作。
MATLAB模块库翻译性能优化:关键点与策略分析

# 1. MATLAB模块库性能优化概述
MATLAB作为强大的数学计算和仿真软件,广泛应用于工程计算、数据分析、算法开发等领域。然而,随着应用程序规模的不断增长,性能问题开始逐渐凸显。模块库的性能优化,不仅关乎代码的运行效率,也直接影响到用户的工作效率和软件的市场竞争力。本章旨在简要介绍MATLAB模块库性能优化的重要性,以及后续章节将深入探讨的优化方法和策略。
## 1.1 MATLAB模块库性能优化的重要性
随着应用需求的
【系统解耦与流量削峰技巧】:腾讯云Python SDK消息队列深度应用

# 1. 系统解耦与流量削峰的基本概念
## 1.1 系统解耦与流量削峰的必要性
在现代IT架构中,随着服务化和模块化的普及,系统间相互依赖关系越发复杂。系统解耦成为确保模块间低耦合、高内聚的关键技术。它不仅可以提升系统的可维护性,还可以增强系统的可用性和可扩展性。与
【趋势分析】:MATLAB与艾伦方差在MEMS陀螺仪噪声分析中的最新应用
# 1. MEMS陀螺仪噪声分析基础
## 1.1 噪声的定义和类型
在本章节,我们将对MEMS陀螺仪噪声进行初步探索。噪声可以被理解为任何影响测量精确度的信号变化,它是MEMS设备性能评估的核心问题之一。MEMS陀螺仪中常见的噪声类型包括白噪声、闪烁噪声和量化噪声等。理解这些噪声的来源和特点,对于提高设备性能至关重要。
【集成学习方法】:用MATLAB提高地基沉降预测的准确性

# 1. 集成学习方法概述
集成学习是一种机器学习范式,它通过构建并结合多个学习器来完成学习任务,旨在获得比单一学习器更好的预测性能。集成学习的核心在于组合策略,包括模型的多样性以及预测结果的平均或投票机制。在集成学习中,每个单独的模型被称为基学习器,而组合后的模型称为集成模型。该
MATLAB机械手仿真并行计算:加速复杂仿真的实用技巧
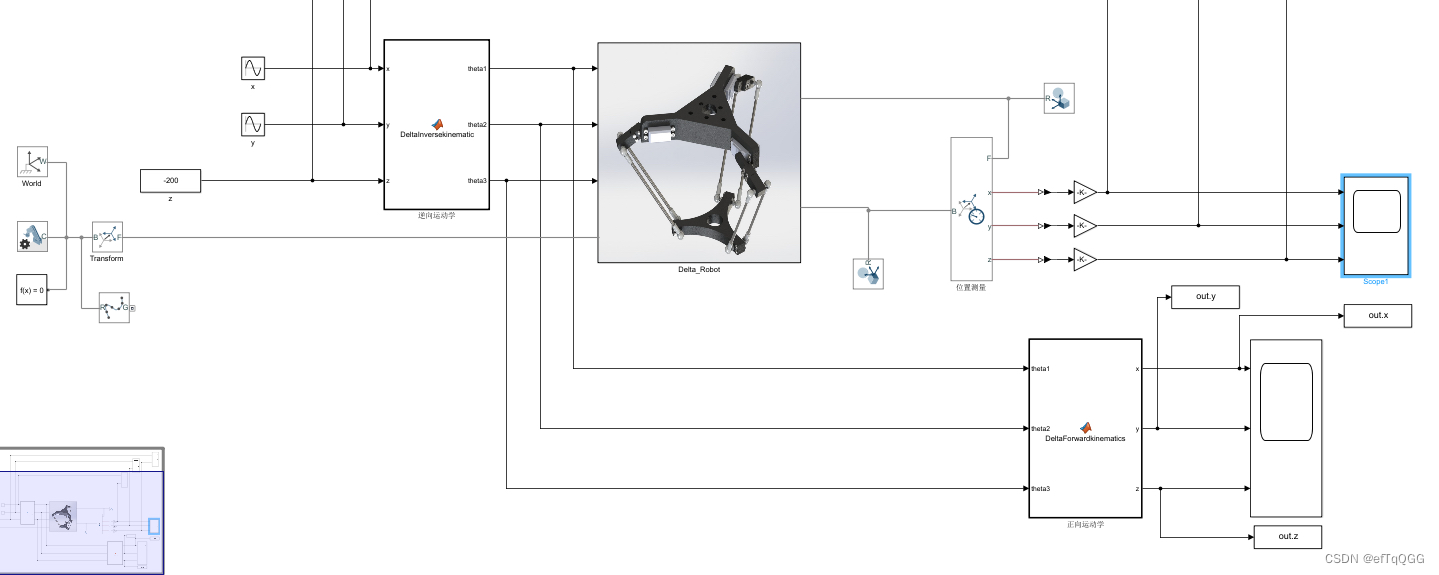
# 1. MATLAB机械手仿真基础
在这一章节中,我们将带领读者进入MATLAB机械手仿真的世界。为了使机械手仿真具有足够的实用性和可行性,我们将从基础开始,逐步深入到复杂的仿真技术中。
首先,我们将介绍机械手仿真的基本概念,包括仿真系统的构建、机械手的动力学模型以及如何使用MATLAB进行模型的参数化和控制。这将为后续章节中将要介绍的并行计算和仿真优化提供坚实的基础。
接下来,我
人工智能中的递归应用:Java搜索算法的探索之旅
# 1. 递归在搜索算法中的理论基础
在计算机科学中,递归是一种强大的编程技巧,它允许函数调用自身以解决更小的子问题,直到达到一个基本条件(也称为终止条件)。这一概念在搜索算法中尤为关键,因为它能够通过简化问题的复杂度来提供清晰的解决方案。
递归通常与分而治之策略相结合,这种策略将复杂问题分解成若干个简单的子问题,然后递归地解决每个子问题。例如,在二分查找算法中,问题空间被反复平分为两个子区间,直到找到目标值或子区间为空。
理解递归的理论基础需要深入掌握其原理与调用栈的运作机制。调用栈是程序用来追踪函数调用序列的一种数据结构,它记录了每次函数调用的返回地址。递归函数的每次调用都会在栈中创
MATLAB遗传算法探索:寻找随机性与确定性的平衡艺术
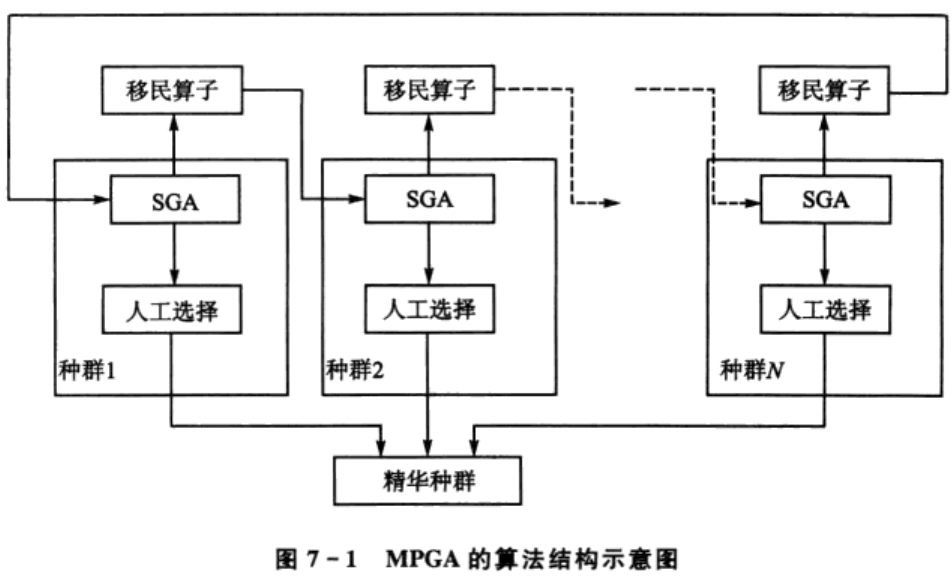
# 1. 遗传算法的基本概念与起源
遗传算法(Genetic Algorithm, GA)是一种模拟自然选择和遗传学机制的搜索优化算法。起源于20世纪60年代末至70年代初,由John Holland及其学生和同事们在研究自适应系统时首次提出,其理论基础受到生物进化论的启发。遗传算法通过编码一个潜在解决方案的“基因”,构造初始种群,并通过选择、交叉(杂交)和变异等操作模拟生物进化过程,以迭代的方式不断优化和筛选出最适应环境的
【数据不平衡环境下的应用】:CNN-BiLSTM的策略与技巧

# 1. 数据不平衡问题概述
数据不平衡是数据科学和机器学习中一个常见的问题,尤其是在分类任务中。不平衡数据集意味着不同类别在数据集中所占比例相差悬殊,这导致模型在预测时倾向于多数类,从而忽略了少数类的特征,进而降低了模型的泛化能力。
## 1.1 数据不平衡的影响
当一个类别的样本数量远多于其他类别时,分类器可能会偏向于识别多数类,而对少数类的识别
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )