【基础】Python基础语法与字符串处理技巧
发布时间: 2024-06-25 05:41:36 阅读量: 75 订阅数: 169 

Python基础知识与编程指南
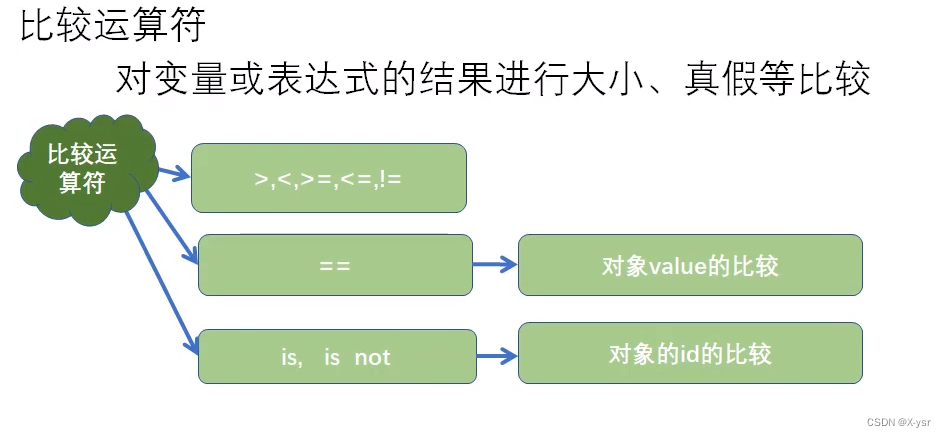
# 1. **2.1 基本数据类型**
Python 中的基本数据类型包括整数、浮点数和字符串。这些类型用于表示不同类型的数据,例如数字、小数和文本。
**2.1.1 整数**
整数表示没有小数部分的数字。它们可以用十进制、八进制或十六进制表示。例如:
```python
# 十进制整数
my_int = 10
# 八进制整数
my_int = 0o12 # 等同于 10
# 十六进制整数
my_int = 0x10 # 等同于 16
```
# 2. Python数据类型与变量
### 2.1 基本数据类型
#### 2.1.1 整数
整数是 Python 中表示整数值的数据类型。它们可以是正数、负数或零。整数可以使用以下语法表示:
```python
my_int = 10
```
#### 2.1.2 浮点数
浮点数是 Python 中表示浮点值的数据类型。它们可以是正数、负数或零,并且包含小数部分。浮点数可以使用以下语法表示:
```python
my_float = 3.14
```
#### 2.1.3 字符串
字符串是 Python 中表示文本值的数据类型。它们是由字符组成的序列,并使用单引号或双引号括起来。字符串可以使用以下语法表示:
```python
my_string = "Hello World"
```
### 2.2 变量与赋值
#### 2.2.1 变量定义
变量是 Python 中用于存储值的容器。它们使用名称来标识,并且可以通过赋值运算符(=)来赋值。变量名称必须遵循以下规则:
- 必须以字母或下划线开头
- 可以包含字母、数字和下划线
- 不能是 Python 关键字
#### 2.2.2 变量赋值
变量赋值是将值存储到变量中的过程。它使用赋值运算符(=)来完成。赋值运算符右侧的值可以是任何有效的 Python 表达式。
```python
my_int = 10
my_float = 3.14
my_string = "Hello World"
```
# 3. Python字符串处理
字符串是Python中表示文本数据的基本数据类型。它由一个有序的字符序列组成,并使用单引号 (') 或双引号 (") 括起来。字符串在Python中具有广泛的应用,从简单的文本处理到高级的正则表达式匹配。
### 3.1 字符串的基本操作
#### 3.1.1 字符串拼接
字符串拼接是将两个或多个字符串连接在一起的操作。在Python中,可以使用 + 运算符来实现字符串拼接。例如:
```python
>>> str1 = "Hello"
>>> str2 = "World"
>>> str3 = str1 + str2
>>> print(str3)
HelloWorld
```
#### 3.1.2 字符串切片
字符串切片是提取字符串中指定部分的操作。在Python中,可以使用 [start:end] 语法来进行字符串切片。其中,start 表示起始索引,end 表示结束索引(不包含)。例如:
```python
>>> str = "Hello World"
>>> print(str[0:5]) # 从索引 0 到 4(不包含)
Hello
>>> print(str[6:]) # 从索引 6 到字符串末尾
World
```
#### 3.1.3 字符串查找
字符串查找是查找字符串中特定子字符串的位置的操作。在Python中,可以使用 find() 方法来查找子字符串的第一个匹配项。如果找不到匹配项,则返回 -1。例如:
```python
>>> str = "Hello World"
>>> print(str.find("World")) # 查找 "World" 子字符串
6
>>> print(str.find("Python")) # 找不到 "Python" 子字符串
-1
```
### 3.2 字符串的高级处理
#### 3.2.1 正则表达式
正则表达式是一种强大的模式匹配语言,用于在字符串中查找复杂模式。在Python中,可以使用 re 模块来使用正则表达式。例如:
```python
import re
>>> str = "Hello 123 World 456"
>>> pattern = r"\d+" # 匹配数字
>>> matches = re.findall(pattern, str)
>>> print(matches)
['123', '456']
```
#### 3.2.2 字符串格式化
字符串格式化是将变量或表达式嵌入字符串中的过程。在Python中,可以使用 % 格式化字符串或 f 字符串来进行字符串格式化。例如:
```python
>>> name = "John"
>>> age = 30
# 使用 % 格式化字符串
>>> str = "My name is %s and I am %d years old." % (name, age)
>>> print(str)
My name is John and I am 30 years old.
# 使用 f 字符串
>>> str = f"My name is {name} and I am {age} years old."
>>> print(str)
My name is John and I am 30 years old.
```
# 4. Python控制流
控制流语句用于控制程序执行的流程,根据不同的条件和循环,可以实现不同的程序逻辑。Python中常用的控制流语句包括条件语句和循环语句。
### 4.1 条件语句
条件语句用于根据给定的条件执行不同的代码块。Python中常用的条件语句包括if语句、elif语句和else语句。
#### 4.1.1 if语句
if语句用于判断一个条件是否为真,如果为真则执行其后的代码块。语法格式如下:
```python
if condition:
# 条件为真的代码块
```
其中,condition为要判断的条件,可以是任何布尔表达式。如果condition为真,则执行其后的代码块,否则跳过该代码块。
#### 4.1.2 elif语句
elif语句用于判断多个条件中的一个是否为真,如果为真则执行其后的代码块。语法格式如下:
```python
if condition1:
# 条件1为真的代码块
elif condition2:
# 条件2为真的代码块
elif conditionN:
# 条件N为真的代码块
```
其中,condition1、condition2、...、conditionN为要判断的条件。如果condition1为真,则执行其后的代码块,否则继续判断condition2,以此类推。如果所有条件都不为真,则跳过所有代码块。
#### 4.1.3 else语句
else语句用于当所有if和elif条件都不满足时执行的代码块。语法格式如下:
```python
if condition1:
# 条件1为真的代码块
elif condition2:
# 条件2为真的代码块
elif conditionN:
# 条件N为真的代码块
else:
# 所有条件都不满足的代码块
```
其中,else语句块中的代码将在所有if和elif条件都不满足时执行。
### 4.2 循环语句
循环语句用于重复执行一段代码块,直到满足某个条件为止。Python中常用的循环语句包括for循环和while循环。
#### 4.2.1 for循环
for循环用于遍历一个序列(如列表、元组、字符串等)中的每个元素,并依次执行代码块。语法格式如下:
```python
for item in sequence:
# 循环体
```
其中,sequence为要遍历的序列,item为序列中的每个元素。循环体中的代码将对序列中的每个元素执行一次。
#### 4.2.2 while循环
while循环用于只要满足某个条件就一直执行代码块。语法格式如下:
```python
while condition:
# 循环体
```
其中,condition为要判断的条件。如果condition为真,则执行循环体,否则跳出循环。
**代码示例:**
```python
# 条件语句示例
if x > 0:
print("x是正数")
elif x < 0:
print("x是负数")
else:
print("x是0")
# 循环语句示例
# for循环
for i in range(10):
print(i)
# while循环
while x > 0:
x -= 1
print(x)
```
**逻辑分析:**
* 条件语句中,如果x大于0,则打印"x是正数",否则判断x是否小于0,如果小于0,则打印"x是负数",否则打印"x是0"。
* for循环中,遍历范围为0到9的数字,依次打印每个数字。
* while循环中,只要x大于0,就一直执行循环体,每次将x减1,并打印x的值,直到x小于0时跳出循环。
# 5.1 函数定义与调用
### 5.1.1 函数定义
在 Python 中,使用 `def` 关键字定义函数。函数定义的语法如下:
```python
def function_name(parameters):
"""函数文档字符串"""
# 函数体
```
* **`function_name`:**函数名称,必须是有效的 Python 标识符。
* **`parameters`:**函数的参数列表,可以为空。
* **`函数文档字符串`:**可选的文档字符串,用于描述函数的功能和用法。
* **`函数体`:**函数的代码块,包含要执行的操作。
### 5.1.2 函数调用
要调用函数,只需使用函数名称并传递必要的参数。函数调用的语法如下:
```python
function_name(arguments)
```
* **`function_name`:**要调用的函数的名称。
* **`arguments`:**要传递给函数的参数列表,可以为空。
**示例:**
定义一个计算两个数字和的函数:
```python
def add_numbers(a, b):
"""计算两个数字的和"""
return a + b
```
调用函数并打印结果:
```python
result = add_numbers(5, 10)
print(result) # 输出:15
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了全面的 Python 自然语言处理 (NLP) 知识,涵盖从基础到进阶的各个方面。专栏中包含一系列文章,深入探讨 NLP 的各个主题,包括:
* 基础知识:NLP 概述、Python 基础语法、文本数据结构、文本预处理、分词库、特征提取、分类算法、情感分析、相似度计算、数据集获取、命名实体识别、文本生成、语言模型、文本聚类、摘要和关键词提取、信息抽取、机器翻译。
* 进阶内容:多语言处理、NLP 工具库、高级文本表示学习、深度学习优化策略、高级文本生成、高级命名实体识别、高级文本相似度计算、情感分析调优、高级文本聚类、高级文本摘要、信息抽取高级应用、机器翻译模型优化、多语言处理挑战、GPT-3 原理和应用、BERT 与 GPT-2 对比、多模态文本生成、文本生成优化策略、文本生成应用案例分析、多语言机器翻译趋势。
* 实战演练:文本情感分析、文本分类、命名实体识别、文本相似度计算、文本摘要生成、信息抽取、机器翻译、文本数据清洗、特征提取、分类模型实现、情感分析实现、命名实体识别实现、文本相似度计算实现、文本聚类算法实现、文本摘要生成实现、信息抽取实现、机器翻译模型实现、文本生成模型实现、文本生成与对话系统实现、文本生成与图像处理结合实现、文本生成与语音合成实现、文本生成与知识图谱实现。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
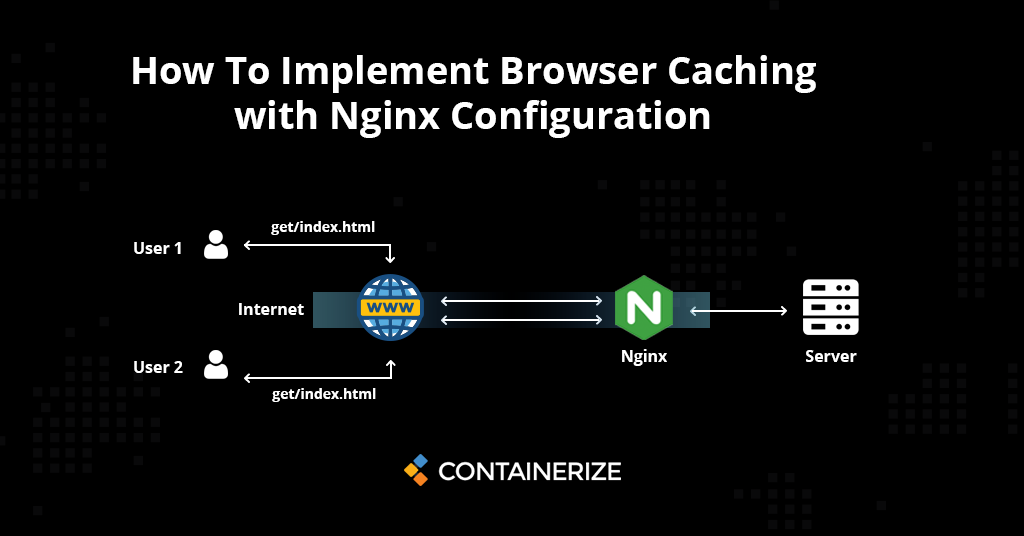
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )