【进阶】多语言处理技术介绍与挑战分析
发布时间: 2024-06-25 06:28:38 阅读量: 105 订阅数: 145 

多语言实现处理

# 1. 多语言处理概述**
多语言处理(NLP)是一门计算机科学领域,它研究如何让计算机理解、解释和生成人类语言。NLP 的目标是让计算机能够像人类一样处理语言,从而实现人机交互、信息检索和机器翻译等应用。
NLP 的核心技术包括机器翻译、自然语言理解和自然语言生成。机器翻译将一种语言的文本翻译成另一种语言,自然语言理解让计算机理解文本的含义,而自然语言生成让计算机生成人类可读的文本。
# 2. 多语言处理技术
多语言处理技术旨在处理自然语言的跨语言差异,实现不同语言之间的沟通和理解。本节将介绍多语言处理的三大核心技术:机器翻译、自然语言理解和自然语言生成。
### 2.1 机器翻译
机器翻译(MT)是将一种语言的文本自动翻译成另一种语言的过程。它广泛应用于跨语言交流、信息检索和国际化等领域。
#### 2.1.1 统计机器翻译
统计机器翻译(SMT)是一种基于统计模型的机器翻译技术。它利用大量平行语料库(即同时包含源语言和目标语言文本的对齐语料)来学习语言之间的转换概率。
**代码块:**
```python
import nltk
from nltk.translate.bleu_score import sentence_bleu
# 定义源语言句子和目标语言句子
src_sentence = "The cat sat on the mat."
tgt_sentence = "Die Katze saß auf der Matte."
# 使用 NLTK 的 BLEU 评分计算翻译质量
bleu_score = sentence_bleu([tgt_sentence], src_sentence)
print("BLEU 评分:", bleu_score)
```
**逻辑分析:**
此代码使用 NLTK 库计算 BLEU 评分,这是一个评估机器翻译质量的常用指标。BLEU 评分基于 n-gram 精度,n-gram 是连续 n 个单词的序列。该代码将目标语言句子与源语言句子进行比较,并计算 n-gram 精度。
**参数说明:**
* `sentence_bleu` 函数:计算 BLEU 评分。
* `[tgt_sentence]`:目标语言句子列表。
* `src_sentence`:源语言句子。
#### 2.1.2 神经机器翻译
神经机器翻译(NMT)是一种基于神经网络的机器翻译技术。它使用编码器-解码器架构,其中编码器将源语言句子编码成一个向量表示,解码器再将该向量表示解码成目标语言句子。
**代码块:**
```python
import tensorflow as tf
# 定义编码器和解码器模型
encoder = tf.keras.models.Sequential(...)
decoder = tf.keras.models.Sequential(...)
# 训练模型
encoder_input = ...
decoder_input = ...
decoder_output = ...
model = tf.keras.Model(encoder_input, decoder_output)
model.compile(...)
model.fit(...)
```
**逻辑分析:**
此代码使用 TensorFlow 定义了一个神经机器翻译模型。编码器将源语言句子编码成一个向量表示,然后解码器将该向量表示解码成目标语言句子。该模型通过使用大量平行语料库进行训练。
**参数说明:**
* `encoder`:编码器模型。
* `decoder`:解码器模型。
* `encoder_input`:编码器输入数据。
* `decoder_input`:解码器输入数据。
* `decoder_output`:解码器输出数据。
### 2.2 自然语言理解
自然语言理解(NLU)是计算机理解自然语言文本含义的过程。它涉及一系列任务,包括句法分析、语义分析和话语分析。
#### 2.2.1 句法分析
句法分析是指确定句子中单词之间的语法关系。它有助于识别句子中的主语、谓语、宾语等成分。
**代码块:**
```python
import spacy
# 创建一个 spaCy NLP 模型
nlp = spacy.load("en_core_web_sm")
# 对句子进行句法分析
doc = nlp("The cat sat on the mat.")
# 打印句法树
print(doc.sents[0].root.subtree)
```
**逻辑分析:**
此代码使用 spaCy 库对句子进行句法分析。spaCy 是一个开源的 NLP 库,它提供了各种语言处理功能。该代码将句子解析成一个句法树,其中包含句子中单词之间的语法关系。
**参数说明:**
* `nlp`:spaCy NLP 模型。
* `doc`:经过分析的文档对象。
* `doc.sents[0].root.subtree`:句法树。
###

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了全面的 Python 自然语言处理 (NLP) 知识,涵盖从基础到进阶的各个方面。专栏中包含一系列文章,深入探讨 NLP 的各个主题,包括:
* 基础知识:NLP 概述、Python 基础语法、文本数据结构、文本预处理、分词库、特征提取、分类算法、情感分析、相似度计算、数据集获取、命名实体识别、文本生成、语言模型、文本聚类、摘要和关键词提取、信息抽取、机器翻译。
* 进阶内容:多语言处理、NLP 工具库、高级文本表示学习、深度学习优化策略、高级文本生成、高级命名实体识别、高级文本相似度计算、情感分析调优、高级文本聚类、高级文本摘要、信息抽取高级应用、机器翻译模型优化、多语言处理挑战、GPT-3 原理和应用、BERT 与 GPT-2 对比、多模态文本生成、文本生成优化策略、文本生成应用案例分析、多语言机器翻译趋势。
* 实战演练:文本情感分析、文本分类、命名实体识别、文本相似度计算、文本摘要生成、信息抽取、机器翻译、文本数据清洗、特征提取、分类模型实现、情感分析实现、命名实体识别实现、文本相似度计算实现、文本聚类算法实现、文本摘要生成实现、信息抽取实现、机器翻译模型实现、文本生成模型实现、文本生成与对话系统实现、文本生成与图像处理结合实现、文本生成与语音合成实现、文本生成与知识图谱实现。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
打造数据驱动决策:Proton-WMS报表自定义与分析教程
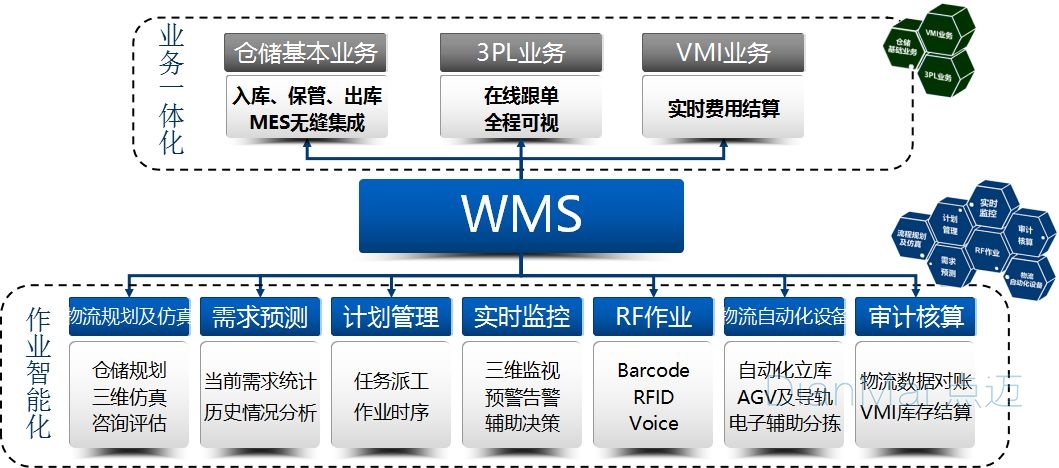
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
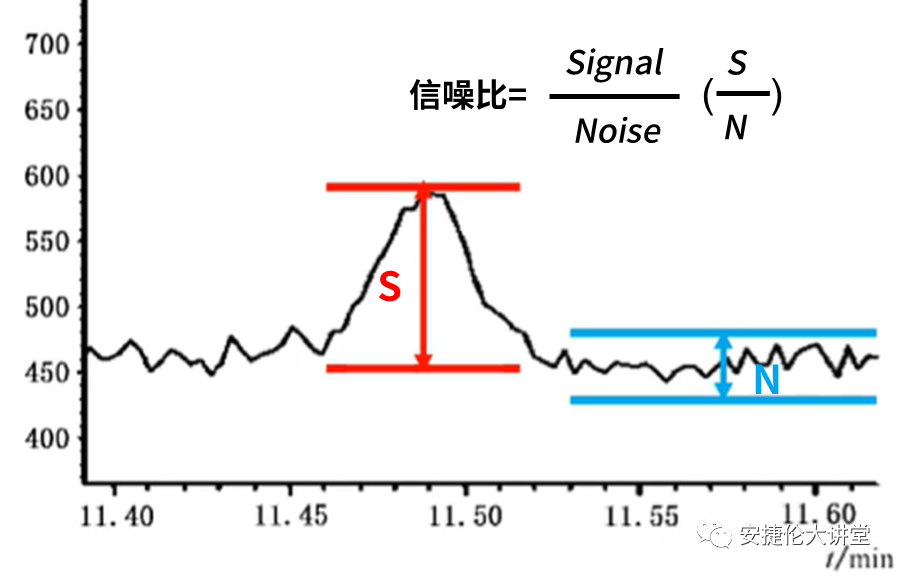
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )