Python并发算法优化:掌握GIL,释放多核CPU的全部潜力
发布时间: 2024-09-01 02:31:23 阅读量: 157 订阅数: 78 
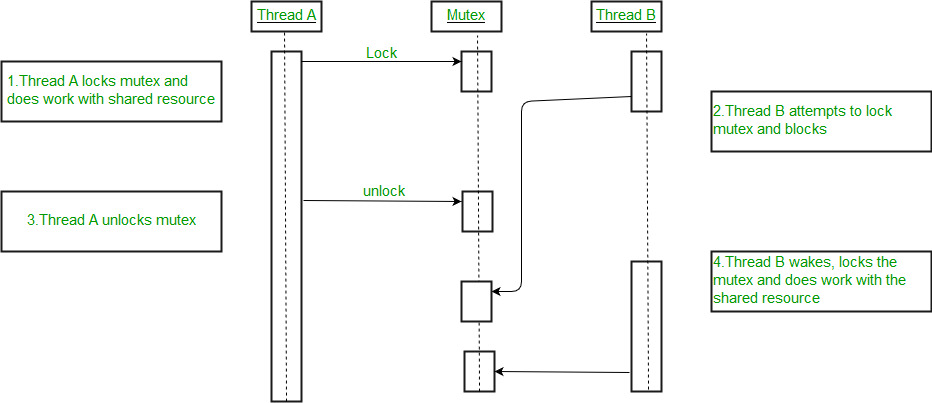
# 1. Python并发编程概述
Python是一种高级编程语言,以其简洁的语法和强大的库支持闻名。随着技术的发展,应用对性能的要求不断提高,因此并发编程在Python中的重要性日益增加。并发编程允许同时运行多个任务,提高程序的效率和响应能力。不过,Python的并发编程模式与其他语言有所不同,尤其是在面对全局解释器锁(GIL)时。理解并发编程的基本概念和原理,对于编写高效、可扩展的Python应用程序至关重要。本章将介绍并发编程的基础知识,并概述Python中并发编程的特殊性,为接下来的章节内容奠定基础。接下来的章节将详细探讨GIL的影响、多线程与多进程编程的理论与实践,以及优化并发算法的策略。
# 2. 理解Python的全局解释器锁(GIL)
## 2.1 GIL的定义和作用
### 2.1.1 解释器锁的基本概念
全局解释器锁(GIL)是Python虚拟机中的一个线程锁,在标准的CPython解释器中实现了线程间的互斥访问,保证了在任何时刻只有一个线程可以执行Python字节码。由于GIL的存在,尽管多线程可以被创建和使用,但在多核处理器上执行多线程程序时,并不会获得预期的并行处理能力。
GIL的出现主要是由于CPython解释器在设计时为了简化内存管理和提高解释器的执行速度而采取的一种权宜之计。Python中对象的内存管理并不线程安全,为了防止多个线程同时操作内存,GIL作为保护机制,确保了在任何时候只有一个线程可以访问Python对象。
### 2.1.2 GIL如何影响多线程编程
在多线程编程模型中,开发者通常会期望程序能够利用多核处理器的计算资源,实现真正的并行处理,从而提升程序的运行效率。然而,在CPython中,由于GIL的存在,即使是在多核处理器上运行,也只有一部分线程能够并行执行,其他线程则需要等待GIL的释放。
这种限制使得多线程在CPU密集型任务中并不会带来性能提升,甚至有可能因为线程上下文切换带来额外的开销。在实际应用中,如果需要处理大量计算密集型任务,通常会采用多进程的方式,以绕开GIL的限制,从而达到并行计算的效果。
## 2.2 GIL的内部机制
### 2.2.1 解释器锁的实现原理
GIL实际上是CPython内部的一个互斥锁,它位于Python虚拟机中,用以控制对Python字节码的执行。当线程获得GIL时,就可以执行Python的字节码,而其他线程则必须等待该线程释放GIL后才能获得执行机会。这种机制保证了在任何时刻,只有一组线程指令在执行。
GIL锁的实现依赖于操作系统的底层锁机制。在CPython的实现中,GIL的获取和释放操作是原子操作,这避免了在多线程环境下可能出现的竞态条件。
### 2.2.2 GIL在不同版本Python中的表现
随着Python语言的发展,对性能的需求日益增长,GIL的影响也引起了广泛的关注。在不同的Python版本中,GIL的表现和优化措施也有所不同。
在Python 2.x版本中,GIL对多线程程序的影响最为明显。到了Python 3.x,虽然GIL仍然存在,但由于语言的改进和库的优化,很多情况下开发者可以更容易地绕开GIL的限制。例如,一些I/O密集型的操作并不受GIL的影响,可以充分利用多线程的优势。
此外,Python的一些扩展实现,如Jython和IronPython,并没有采用GIL的机制,它们允许真正的多线程并行执行,但同时也会遇到其他线程安全的问题。
## 2.3 GIL的利弊分析
### 2.3.1 GIL带来的优势和限制
GIL虽然限制了多线程在CPython中的并行执行,但它也带来了一些优势。最明显的优点是简化了Python对象的内存管理。由于GIL保证了任何时候只有一个线程能够执行Python字节码,所以避免了多线程中可能的内存竞争和共享资源的冲突问题。
然而,这种优势也是有代价的。对于CPU密集型任务,GIL成为了性能提升的瓶颈。它限制了程序利用多核处理器的能力,使得多线程并不能带来预期的加速效果。
### 2.3.2 对于并发性能的实际影响
在实际开发中,GIL对并发性能的影响主要体现在两个方面:一是对于CPU密集型任务,多线程并不能有效地利用多核处理器;二是在I/O密集型任务中,GIL的影响较小,因为线程大多数时间都处于等待I/O操作完成的状态,此时GIL会被释放。
为了绕开GIL的限制,开发者通常会采用多进程的方式,在不同进程中实现真正的并行计算。此外,Python社区也提出了许多其他解决方案,如使用Jython或IronPython,使用C扩展模块以及采用异步编程等策略。
接下来,我们将探讨如何在实践中优化Python的并发编程,以及如何避免GIL带来的限制。
# 3. Python中的多线程与多进程编程
## 3.1 多线程编程理论与实践
### 3.1.1 线程的基本操作和同步机制
多线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。Python中的线程是通过内置的`threading`模块来实现的。每个线程都拥有自己的线程ID、程序计数器、寄存器集合和栈。线程共享进程中的内存空间和其他资源。
Python中的线程操作包括创建线程、启动线程、线程间同步等。一个简单的线程创建和启动的例子如下:
```python
import threading
def print_numbers():
for i in range(5):
print(i)
# 创建线程
t = threading.Thread(target=print_numbers)
# 启动线程
t.start()
# 等待线程完成
t.join()
```
线程间同步是多线程编程中非常重要的部分,主要的同步机制有互斥锁(`threading.Lock`)、事件(`threading.Event`)、信号量(`threading.Semaphore`)和条件变量(`threading.Condition`)等。
互斥锁用于保证在任何时候只有一个线程可以访问共享资源。使用互斥锁的代码块如下:
```python
import threading
counter = 0
counter_lock = threading.Lock()
def increment_counter():
global counter
for _ in range(10000):
counter_lock.acquire() # 尝试获取锁
counter += 1
counter_lock.release() # 释放锁
# 创建多个线程
threads = [threading.Thread(target=increment_counter) for _ in range(10)]
# 启动所有线程
for t in threads:
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f'Final Counter Value: {counter}')
```
### 3.1.2 线程的优缺点及适用场景
线程的优点主要包括:
- **资源消耗小**:创建和销毁线程的代价比进程要小得多。
- **上下文切换快**:线程间的切换比进程间的切换要快。
- **通信方便**:同一进程下的线程共享内存空间,因此通信非常方便。
线程的缺点包括:
- **GIL问题**:由于Python的全局解释器锁(GIL),在多线程环境下,不能有效地利用多核CPU来提高性能。
- **同步问题**:多线程编程需要考虑同步问题,可能会出现死锁、数据竞争等问题。
- **调试困难**:多线程的并发运行可能导致程序行为难以预测,调试相对困难。
线程适用于以下场景:
- **I/O密集型任务**:线程对于I/O操作的并发处理非常有效,例如网络请求、数据库操作等。
- **轻量级任务**:对于计算密集型任务,如果任务不复杂,可以考虑使用线程来实现多任务处理。
### 3.1.3 多线程编程实践案例
下面我们来看一个多线程在实际中的应用案例。假设我们需要从网络上下载多个文件,我们可以使用线程池来实现并发下载,从而节省总的下载时间。
```python
import requests
from concurrent.futures import ThreadPoolExecutor
# 定义一个下载函数
def download_file(url):
response = requests.get(url)
filename = url.split('/')[-1]
with open(filename, 'wb') as f:
f.write(response.content)
# 定义要下载的文件列表
urls_to_download = [
'***',
'***',
# ... 更多文件
]
# 使用线程池下载文件
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_file, urls_to_download)
```
在这个案例中,`ThreadPoolExecutor`是`concurrent.futures`模块中的一个类,用于管理一个线程池。`max_workers`参数定义了线程池中的最大线程数。`map`方法可以将指定函数应用于可迭代对象的每个项目,它会自动在多个线程中分配任务,并等待所有任务完成。这是一个非常实用的高级接口,可以简化多线程编程。
## 3.2 多进程编程理论与实践
### 3.2.1 进程的创建和管理
在Python中,多进程编程是通过内置的`multiprocessing`模块来实现的。进程是由操作系统创建的,每个进程都有自己的内存空间和系统资源。`multiprocessing`模块提供了与`threading`模块类似的接口来创建和管理进程。
创建进程的代码示例如下:
```python
import multiprocessing
def print_numbers():
for i in range(5):
print(i)
# 创建进程
p = multiprocessing.Process(target=print_numbers)
# 启动进程
p.start()
# 等待进程完成
p.join()
```
与线程相比,进程间的数据是完全隔离的,因此不需要像线程那样使用互斥锁来保护共享资源。进程间的通信通常采用进程间通信(IPC)机制,如管道(pipes)、队列(queues)、共享内存(shared memory)等。
### 3.2.2 进程与线程并发效率的比较
通常情况下,进程间的并发效率要高于线程。因为进程之间独立运行,相互之间不受影响。特别是在多核CPU的情况下,多进程可以真正实现并行计算,而多线程由于受到GIL的限制,不能有效利用多核。
然而,在I/O密集型任务中,由于I/O操作的阻塞性质,线程也可以表现出较好的并发性能。而在计算密集型任务中,多进程通常表现更佳。
### 3.2.3 多进程编程实践案例
下面是一个使用多进程来处理大量数据的案例。我们使用`multiprocessing`模块来创建多个进程,每个进程负责一部分数据的处理。
```python
import multiprocessing
def process_data(data):
# 假设data是一个需要处理的大数据结构
result = some_complex_operation(data)
return result
def main():
data_list = generate_large_data_list()
num_processes = 4
with multiprocessing.Pool(processes=num_processes) as pool:
results = pool.map(process_data, data_list)
# 处理结果
if __name__ == '__main__':
main()
```
在这个例子中,我们使用了`multiprocessing.Pool`来创建一个进程池。`process_data`函数负责数据的处理逻辑。`pool.map`方法将数据列表分配给多个进程进行并行处理,并返回结果列表。
## 3.3 进程间通信(IPC)
### 3.3.1 进程间通信的方式和原理
进程间通信(IPC)是实现进程间数据交换的一系列技术。IPC的方法很多,包括管道、消息队列、共享内存、信号、信号量等。每种方法都有自己的特点和适用场景。
### 3.3.2 实际案例分析
下面我们来看一个使用共享内存进行进程间通信的案例。`multiprocessing`模块中的`Value`和`Array`类型可以用来创建共享内存数据结构。
```python
from multiprocessing import Process, Value, Array
import time
def f(n, a):
n.value = 3.1415927 # 修改共享变量
for i in range(len(a)):
a[i] = -a[i] # 修改共享数组
if __name__ == '__main__':
num = Value('d', 0.0) # 创建共享浮点数
arr = Array('i', range(10)) # 创建共享数组
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value) # 输出共享浮点数
print(arr[:]) # 输出共享数组
```
在这个例子中,我们创建了一个共享的浮点数`num`和一个共享的整数数组`arr`。子进程`p`对这两个共享数据进行了修改。当子进程结束后,主进程能够读取这些修改后的共享数据。
### 3.3.3 进程间通信的实现方式
不同的进程间通信方式有以下实现方式:
- **管道(Pipes)**:用于两个进程间的通信。常用于父子进程或者兄弟进程之间。
- **消息队列(Message Queues)**:是一种先进先出的通信机制,适用于更复杂的进程间通信。
- **共享内存(Shared Memory)**:允许多个进程访问同一内存空间。它允许不同进程共享数据,通常是最高效的IPC方法。
- **信号量(Semaphores)**:提供了一种进程间同步机制,而不是直接的数据交换。
- **套接字(Sockets)**:主要用在不同机器间的进程通信。
### 3.3.4 进程间通信的应用场景
进程间通信的场景很多,例如:
- **服务进程和客户端进程之间的通信**:当多个客户端请求服务时,服务进程通常需要与客户端进程进行通信。
- **不同子系统间的通信**:在复杂系统中,不同的子系统可能需要共享信息或状态。
- **数据处理流水线**:在数据处理流水线中,不同阶段的进程可能需要通信以确保数据正确地从一个阶段流向另一个阶段。
### 3.3.5 进程间通信的挑战和最佳实践
进程间通信的挑战主要包括:
- **同步问题**:确保数据的一致性和完整性。
- **性能问题**:IPC操作通常涉及系统调用,可能成为性能瓶颈。
- **安全性问题**:共享内存和其他IPC机制需要适当的安全措施来避免数据泄露或损坏。
最佳实践包括:
- **最小化通信**:减少IPC的次数,只在必要时才进行通信。
- **明确同步机制**:使用适当的同步机制来保护共享资源。
- **选择合适的IPC方法**:根据应用需求选择最佳的IPC方法。
### 3.3.6 实际案例分析
在实际应用中,IPC的具体实现需要考虑数据的传输效率、系统资源的使用情况以及程序的复杂度。例如,在云计算环境中,可以使用消息队列来传递服务请求,使用共享内存来共享计算结果。在桌面应用中,父子进程间的管道通信是一种常见模式。这些案例中,选择合适的IPC机制需要对应用场景有深刻的理解。
在下一章节,我们将进一步探讨如何优化Python并发算法的策略。
# 4. 优化Python并发算法的策略
## 4.1 避免GIL限制的策略
### 4.1.1 使用多进程绕开GIL的限制
Python的全局解释器锁(GIL)为多线程程序带来了一定的性能瓶颈,尤其是对于计算密集型任务。在执行CPU密集型任务时,利用多进程而非多线程可以绕开GIL的限制。进程间的内存是隔离的,因此它们之间不会互相影响,每个进程有自己的Python解释器和GIL,从而使得并发执行可以真正地利用多核CPU的优势。
```python
from multiprocessing import Process
def compute_heavy_task(data):
# 模拟CPU密集型任务
result = sum(x * 2 for x in data)
return result
if __name__ == '__main__':
data = [i for i in range(1000000)]
processes = []
for _ in range(4):
p = Process(target=compute_heavy_task, args=(data,))
p.start()
processes.append(p)
for p in processes:
p.join()
```
**代码逻辑逐行解读分析:**
1-2. 首先导入了multiprocessing模块中的Process类,该类是创建进程的主要接口。
3-7. 定义了一个函数compute_heavy_task,这个函数接收一组数据并进行一些计算密集的操作,这里简单地把每个元素乘以2然后求和,目的是模拟一个CPU密集型任务。
9-10. 程序主入口部分,首先生成了一组数据data。
12-16. 接下来创建了四个进程,每个进程都会执行compute_heavy_task函数,它们共享相同的数据。
13, 15. 启动每个进程,并将它们添加到进程列表中。
18-20. 主进程等待所有子进程结束。
使用多进程时,每个进程间内存隔离,因此需要传递数据时需要使用进程间通信(IPC),如队列、管道或共享内存等方式。
### 4.1.2 选择合适的线程/进程数
选择正确的线程或进程数量是优化并发性能的关键。过多的线程可能导致频繁的上下文切换,从而降低程序效率。对于I/O密集型任务,适当的线程数可以提高效率,因为I/O操作不涉及CPU计算,线程可以等待I/O操作时让出CPU给其他线程,充分利用CPU资源。
在Python中,可以使用`concurrent.futures`模块中的`ThreadPoolExecutor`或`ProcessPoolExecutor`来创建线程池或进程池。以下是一个使用线程池的例子:
```python
from concurrent.futures import ThreadPoolExecutor, as_completed
def io_heavy_task(data):
# 模拟I/O密集型任务
# 这里可以是网络请求、磁盘I/O等操作
pass # 省略具体实现
def main():
data = [i for i in range(100)]
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_task = {executor.submit(io_heavy_task, x): x for x in data}
for future in as_completed(future_to_task):
data = future.result()
if __name__ == '__main__':
main()
```
**代码逻辑逐行解读分析:**
1. 从concurrent.futures模块中导入ThreadPoolExecutor和as_completed,前者用于创建线程池,后者用于处理完成的任务。
3-5. 定义了一个函数io_heavy_task,模拟一个I/O密集型任务。
8-14. 在主函数中,首先创建了100个数据项,然后创建一个最大工作线程数为10的线程池。
9-11. 使用executor.submit提交任务到线程池,并用字典记录每个future对象和对应的数据。
13. 使用as_completed方法来获取完成的任务结果。
对于线程数目的选择,一个通用的经验是使用系统的核心数加一,这样可以确保CPU资源得到充分利用,同时还能处理一些I/O操作。但是,实际选择还应考虑具体任务的特性和系统环境。
## 4.2 并发编程中的数据结构选择
### 4.2.1 并发安全的数据结构
在并发编程中,数据结构的选择直接影响到程序的效率和稳定性。选择不当可能导致数据竞争和不一致,甚至引起程序崩溃。Python标准库提供了线程安全的队列`Queue`,可以用于线程间的数据传递,避免直接使用线程间共享的数据结构。
```python
from queue import Queue
q = Queue()
def producer():
for i in range(5):
q.put(i)
print(f"Produced {i}")
def consumer():
while True:
item = q.get()
print(f"Consumed {item}")
q.task_done()
if __name__ == '__main__':
import threading
p = threading.Thread(target=producer)
c = threading.Thread(target=consumer)
p.start()
c.start()
p.join()
c.join()
```
**代码逻辑逐行解读分析:**
1. 导入queue模块中的Queue类。
3. 创建一个Queue实例,它是一个线程安全的队列。
5-9. 定义一个producer函数,它向队列中添加项目。
11-15. 定义一个consumer函数,它从队列中取出并处理项目。
17-23. 在主函数中,创建一个生产者和一个消费者线程,启动它们,并等待线程结束。
`Queue`是线程安全的,因为其内部实现了必要的锁机制,确保在多线程环境下数据的一致性。对于进程间的数据结构,Python提供`multiprocessing`模块中的`Manager`类,它允许创建可被多个进程共享的对象,如列表、字典等。
### 4.2.2 内存管理和优化技巧
在并发编程中,内存管理至关重要,不当的管理可能会导致内存泄漏和资源竞争。使用上下文管理器(context manager)和垃圾回收(garbage collection)是管理内存的常用方法。
Python的垃圾回收是基于引用计数的。当对象的引用计数降到0时,Python会自动回收该对象所占用的内存。为了避免内存泄漏,可以使用weakref模块创建弱引用。
```python
import weakref
class MyObject:
def __del__(self):
print("MyObject is being deleted")
obj = MyObject()
weak_obj = weakref.ref(obj)
print("weakref points to:", weak_obj())
del obj
print("weakref points to:", weak_obj())
```
**代码逻辑逐行解读分析:**
1-2. 导入了weakref模块和一个自定义的类MyObject。
4-8. MyObject有一个析构函数`__del__`,当对象被删除时会打印消息。
10. 创建MyObject的一个实例obj。
11. 创建obj的一个弱引用weak_obj。
13. 打印当前weak_obj指向的对象。
15. 删除obj变量,这意味着其引用计数减少了。
17. 打印当前weak_obj指向的对象,此时因为MyObject实例已被删除,所以可能指向None。
使用弱引用可以避免增加对象的引用计数,使得对象在没有其他强引用的情况下能够被垃圾回收器回收。这在管理缓存或其他全局资源时非常有用。
## 4.3 利用第三方库提升并发效率
### 4.3.1 分析常用并发库的优势
在Python的并发编程中,除了标准库提供的功能外,还存在一些第三方库能够提供额外的性能和功能性优势。在选择第三方库时,需要了解每个库的具体用途,例如并发控制、I/O处理、网络通信等。
一些流行的第三方并发库包括`gevent`、`asyncio`和`pytorch`等。例如`gevent`库实现了协程,可以用来高效地处理大量的轻量级并发任务,尤其适合I/O密集型应用。
```python
import gevent
import gevent.monkey
from gevent import socket
gevent.monkey.patch_all() # 将标准库函数转换为异步版本
def server_task(url):
s = socket.socket()
s.connect((url, 80))
s.send(b"GET / HTTP/1.0\r\nHost: ***\r\n\r\n")
response = s.recv(4096)
print(response)
s.close()
urls = ['***', '***', '***']
threads = [gevent.spawn(server_task, url) for url in urls]
gevent.joinall(threads)
```
**代码逻辑逐行解读分析:**
1-2. 导入gevent库和socket模块。
3. 导入gevent.monkey并调用patch_all方法,这使得标准库函数能够与gevent协作,实现异步执行。
4. 导入gevent下的socket模块。
6-13. 定义server_task函数,它使用socket发送HTTP请求并接收响应。
15-18. 创建一个URL列表,并为每个URL创建一个gevent线程。
19. 使用gevent.joinall等待所有gevent线程完成。
通过使用gevent,原本串行的网络请求被改写成并发执行,大大提升了程序的执行效率。
### 4.3.2 实际案例分析
`asyncio`是Python标准库的一部分,用于编写单线程的并发代码,通过事件循环实现异步操作。`asyncio`的事件循环支持`Future`对象,允许编写协同程序(coroutines)来处理并发任务。
```python
import asyncio
async def get_data():
return await asyncio.sleep(1, result='done')
async def main():
data1 = await get_data()
print(f"Got {data1} from get_data()")
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
**代码逻辑逐行解读分析:**
1-2. 导入了asyncio库,并定义了一个协同程序get_data。
3. get_data函数中使用await语句来异步执行`asyncio.sleep`,模拟I/O操作。
5-7. 定义了主函数main,它等待get_data的执行结果。
9. 获取当前的事件循环实例。
10. 使用事件循环的run_until_complete方法来执行main协同程序。
实际案例中,通过使用asyncio可以有效提高I/O密集型任务的执行效率,尤其是在需要处理大量并发连接的情况下。
在选择和使用这些第三方库时,重要的是要了解每个库背后的设计哲学和应用场景。例如,`asyncio`适用于需要处理大量I/O操作的场景,而`gevent`则适合于需要快速响应和轻量级任务的Web服务器。根据实际需要合理选择和使用这些并发编程库,能够大幅提升程序的性能和效率。
# 5. 并发算法优化实战
## 5.1 实际问题分析与并发解决方案
在优化并发算法之前,需要识别出程序中的并发瓶颈。这通常涉及到分析程序的I/O操作、计算密集型任务、锁竞争等。例如,如果一个程序在处理大量网络请求时出现延迟,那么问题可能在于I/O阻塞。针对这种情况,我们可以引入异步I/O或者事件驱动模型来解决。
### 识别并发瓶颈
为了识别并发瓶颈,我们需要使用性能分析工具,比如Python的cProfile或者line_profiler。这些工具可以帮助我们找出程序中的热点函数(即运行时间最长的函数),以及哪些部分在等待I/O或锁。
```python
import cProfile
def some_function():
# 假设这是一个热点函数
for i in range(100000):
pass
cProfile.run('some_function()')
```
通过分析输出,我们可以确定程序中的性能瓶颈,并针对这些问题设计并发算法。
### 设计并发算法的思路和方法
设计并发算法时,我们可以采用以下方法:
- **任务分割**:将大任务分解成小任务,每个小任务可以在单独的线程或进程中执行。
- **负载平衡**:确保所有线程或进程的负载均衡,避免某些线程或进程空闲而其他线程或进程过载。
- **数据一致性**:如果算法需要操作共享资源,确保设计中包含了适当的同步机制。
## 5.2 并发算法性能测试与评估
性能测试是优化并发算法不可或缺的一步。它不仅帮助我们理解当前算法的性能,还能为之后的优化提供基线。
### 性能测试工具和方法
性能测试可以使用`time`命令或`timeit`模块来测量代码的执行时间。对于并发程序,我们可能还需要使用专门的并发性能测试框架,如`concurrent.futures`模块中的`ThreadPoolExecutor`和`ProcessPoolExecutor`。
```python
import concurrent.futures
import time
def task(n):
# 假设这是一个耗时的操作
for i in range(n):
pass
def test_concurrency():
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(task, [100000] * 4))
end_time = time.time()
print(f"Total time taken: {end_time - start_time} seconds")
test_concurrency()
```
### 结果分析与优化方向
分析性能测试结果时,应关注以下指标:
- 吞吐量:单位时间内完成的任务数量。
- 响应时间:从任务提交到任务完成所需的时间。
- CPU和内存使用情况。
如果测试结果不理想,可能需要调整并发级别,减少锁竞争,或者使用更加高效的数据结构。
## 5.3 高级优化技术
高级优化技术可以帮助我们在更深层次上提升并发程序的性能。
### C扩展和JIT编译器的使用
为了绕开Python的GIL,可以使用C扩展或者通过像PyPy这样的JIT编译器来提高性能。这些方法允许更直接地控制底层资源和执行环境。
```python
# C扩展示例
import ctypes
ext = ctypes.CDLL("./my_extension.so")
ext.my_c_function()
```
### 异步编程模型和微线程的应用
异步编程模型,如`asyncio`,可以在单线程中处理I/O密集型任务,提高程序的响应性和吞吐量。微线程(也称为协程)是一种轻量级线程,可以在有限的资源下实现多任务的并发执行。
```python
import asyncio
async def main():
# 异步任务
await asyncio.sleep(1)
print("Done")
asyncio.run(main())
```
通过使用这些技术,我们能够提升并发算法的性能,使得程序更加高效和稳定。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 并发算法的优化技巧,涵盖了从基本概念到高级技术的广泛主题。它提供了关于 Python 并发编程的全面指南,指导读者解锁性能提升和故障排除的秘籍。专栏深入分析了 GIL,揭示了多核 CPU 的全部潜力,并提供了构建高效 Python 并发应用的专家级最佳实践。此外,它还探讨了多线程和多进程编程的陷阱,以及如何实现线程安全和性能优化。专栏深入解析了异步 IO,介绍了 Python asyncio 的高效使用技巧。它还提供了并发控制进阶指南,精通线程安全和锁机制,并探讨了 Python 并发与分布式系统设计中的架构优化和实战技巧。最后,专栏还提供了 Python 并发性能测试全攻略,从基准测试到性能分析,以及 Python 并发算法性能提升的五大技巧。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Optimization of Multi-threaded Drawing in QT: Avoiding Color Rendering Blockage
### 1. Understanding the Basics of Multithreaded Drawing in Qt
#### 1.1 Overview of Multithreaded Drawing in Qt
Multithreaded drawing in Qt refers to the process of performing drawing operations in separate threads to improve drawing performance and responsiveness. By leveraging the advantages of m
Multilayer Perceptron (MLP) in Time Series Forecasting: Unveiling Trends, Predicting the Future, and New Insights from Data Mining
# 1. Fundamentals of Time Series Forecasting
Time series forecasting is the process of predicting future values of a time series data, which appears as a sequence of observations ordered over time. It is widely used in many fields such as financial forecasting, weather prediction, and medical diagn
Introduction and Advanced: Teaching Resources for Monte Carlo Simulation in MATLAB
# Introduction and Advancement: Teaching Resources for Monte Carlo Simulation in MATLAB
## 1. Introduction to Monte Carlo Simulation
Monte Carlo simulation is a numerical simulation technique based on probability and randomness used to solve complex or intractable problems. It generates a large nu
Quickly Solve OpenCV Problems: A Detailed Guide to OpenCV Debugging Techniques, from Log Analysis to Breakpoint Debugging
# 1. Overview of OpenCV Issue Debugging
OpenCV issue debugging is an essential part of the software development process, aiding in the identification and resolution of errors and problems within the code. This chapter will outline common methods for OpenCV debugging, including log analysis, breakpo
Truth Tables and Logic Gates: The Basic Components of Logic Circuits, Understanding the Mysteries of Digital Circuits (In-Depth Analysis)
# Truth Tables and Logic Gates: The Basic Components of Logic Circuits, Deciphering the Mysteries of Digital Circuits (In-depth Analysis)
## 1. Basic Concepts of Truth Tables and Logic Gates
A truth table is a tabular representation that describes the relationship between the inputs and outputs of
Optimizing Traffic Flow and Logistics Networks: Applications of MATLAB Linear Programming in Transportation
# Optimizing Traffic and Logistics Networks: The Application of MATLAB Linear Programming in Transportation
## 1. Overview of Transportation Optimization
Transportation optimization aims to enhance traffic efficiency, reduce congestion, and improve overall traffic conditions by optimizing decision
Selection and Optimization of Anomaly Detection Models: 4 Tips to Ensure Your Model Is Smarter
# 1. Overview of Anomaly Detection Models
## 1.1 Introduction to Anomaly Detection
Anomaly detection is a significant part of data science that primarily aims to identify anomalies—data points that deviate from expected patterns or behaviors—from vast amounts of data. These anomalies might represen
Advanced Techniques: Managing Multiple Projects and Differentiating with VSCode
# 1.1 Creating and Managing Workspaces
In VSCode, a workspace is a container for multiple projects. It provides a centralized location for managing multiple projects and allows you to customize settings and extensions.
To create a workspace, open VSCode and click "File" > "Open Folder". Browse to
【Advanced】Breaking Through Blocks and Restrictions Using Proxy Servers: Setting Up a Private Proxy Server to Solve IP Blocking Issues
# [Advanced] Breaking Through Blocks and Restrictions Using Proxy Servers: Setting Up Private Proxy Servers to Solve IP Blocking Issues
## 1. The Principle and Types of Proxy Servers
A proxy server is an intermediary server that sits between the client and the target server, responsible for forwar
YOLOv8 Practical Case: Intelligent Robot Visual Navigation and Obstacle Avoidance
# Section 1: Overview and Principles of YOLOv8
YOLOv8 is the latest version of the You Only Look Once (YOLO) object detection algorithm, ***pared to previous versions of YOLO, YOLOv8 has seen significant improvements in accuracy and speed.
YOLOv8 employs a new network architecture known as Cross-S
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )