Keil5 Code Analysis and Performance Optimization Practical Guide
发布时间: 2024-09-15 13:52:27 阅读量: 25 订阅数: 39 
# Keil5 Code Analysis and Performance Optimization Practical Guide
## 1. Fundamentals of Keil5 Code Analysis**
Keil5 is a popular integrated development environment (IDE) for embedded systems, which offers powerful code profiling features to help developers gain in-depth insights into the code structure, execution flow, and performance bottlenecks. With code profiling, developers can identify defects in the code, optimize algorithms and data structures, thus enhancing code quality and performance.
The code profiling capabilities of Keil5 include:
***Code Coverage Analysis:** Measures the execution coverage of the code and identifies unexecuted code paths.
***Performance Bottleneck Identification:** Identifies functions and code sections that consume excessive time within the code, pinpointing performance bottlenecks.
***Code Defect Detection:** Uses static code analysis tools to detect code defects, such as uninitialized variables, null pointer references, and memory leaks.
## 2. Keil5 Code Optimization Techniques
In embedded system development, code optimization is crucial as it can enhance code execution efficiency, reduce memory usage, and increase system stability. Keil5 provides a wealth of optimization tools and techniques to assist developers in optimizing their code. This chapter will delve into detailed Keil5 code optimization techniques, including code structure optimization, algorithm optimization, and memory optimization.
### 2.1 Code Structure Optimization
Code structure optimization primarily aims at improving through refactoring and modularization.
#### 2.1.1 Function Splitting and Modularization
Breaking down large functions into smaller, manageable functions enhances code readability and maintainability. Moreover, modularization organizes code into independent modules, facilitating reuse and maintenance.
**Code Example:**
```c
// Original code
void main() {
// Large function contains all the code
}
// Optimized code
void init() {
// Initialization code
}
void process() {
// Processing code
}
void main() {
init();
process();
}
```
**Logical Analysis:**
The optimized code splits the large function into two smaller functions, `init()` and `process()`, each responsible for specific tasks. This enhances the readability and maintainability of the code.
**Parameter Description:**
None
#### 2.1.2 Code Refactoring and Optimization
Code refactoring refers to adjusting the code structure to make it easier to understand and maintain. Refactoring techniques include:
***Inline Functions:** Inline small functions at their call sites to reduce the overhead of function calls.
***Constant Folding:** Fold constant expressions known at compile-time into constants, reducing computation overhead.
***Loop Unrolling:** Unroll loops into a sequence of statements to improve code execution efficiency.
**Code Example:**
```c
// Original code
int sum(int n) {
int result = 0;
for (int i = 0; i < n; i++) {
result += i;
}
return result;
}
// Optimized code
int sum(int n) {
return (n * (n + 1)) / 2;
}
```
**Logical Analysis:**
The optimized code replaces the loop with a mathematical expression to calculate the sum. This improves code execution efficiency as it eliminates the need for loop iterations.
**Parameter Description:**
* `n`: The integer for which the sum is to be calculated.
### 2.2 Algorithm Optimization
Algorithm optimization improves code execution efficiency by selecting and refining algorithms.
#### 2.2.1 Data Structure Selection and Optimization
Choosing the right data structure is vital for algorithm efficiency. For instance, storing ordered data in an array is more efficient than using a linked list. Furthermore, optimizing data structures (e.g., using hash tables for fast lookups) can improve performance.
**Code Example:**
```c
// Original code
struct Node {
int data;
struct Node *next;
};
struct Node *head = NULL;
void add(int data) {
struct Node *new_node = (struct Node *)malloc(sizeof(struct Node));
new_node->data = data;
new_node->next = head;
head = new_node;
}
// Optimized code
#include <stdlib.h>
int *arr = NULL;
int size = 0;
void add(int data) {
arr = (int *)realloc(arr, (size + 1) * sizeof(int));
arr[size++] = data;
}
```
**Logical Analysis:**
The original code uses a linked list to store data, while the optimized code uses an array. Arrays are more efficient for lookup and insertion operations because of their contiguous memory layout.
**Parameter Description:**
* `data`: The data to be added.
#### 2.2.2 Algorithm Complexity Analysis and Improvement
Algorithm complexity analysis can help determine the efficiency of an algorithm. By analyzing the time and space complexity of an algorithm, bottlenecks can be identified and measures can be taken to improve them.
**Code Example:**
```c
// Original code
int find(int *arr, int n, int target) {
for (int i = 0; i < n; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
// Optimized code
int find(int *arr, int n, int target) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
low = mid + 1;
} else {
high = mid -
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
机器学习调试实战:分析并优化模型性能的偏差与方差
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
激活函数在深度学习中的应用:欠拟合克星
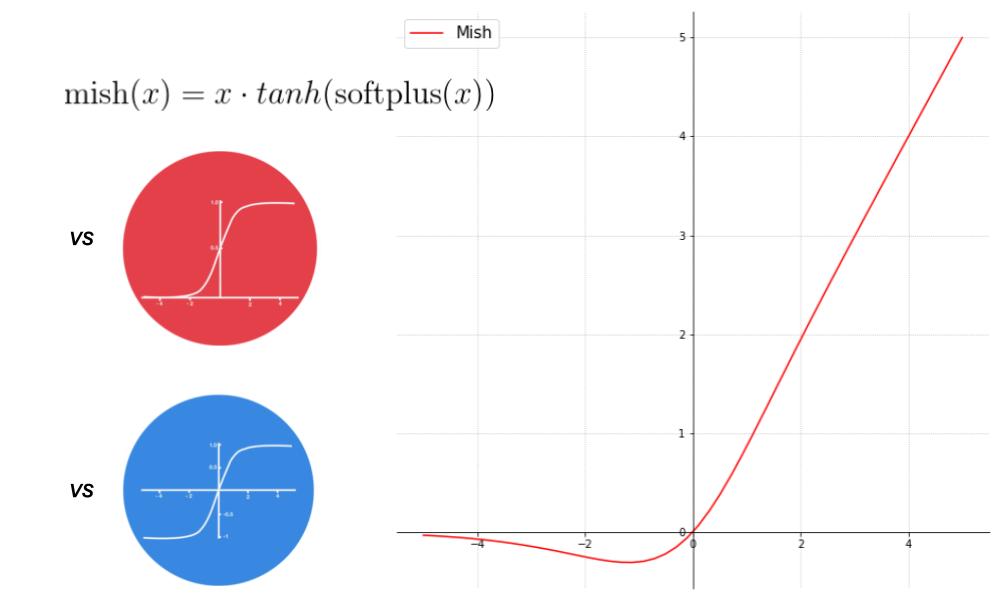
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
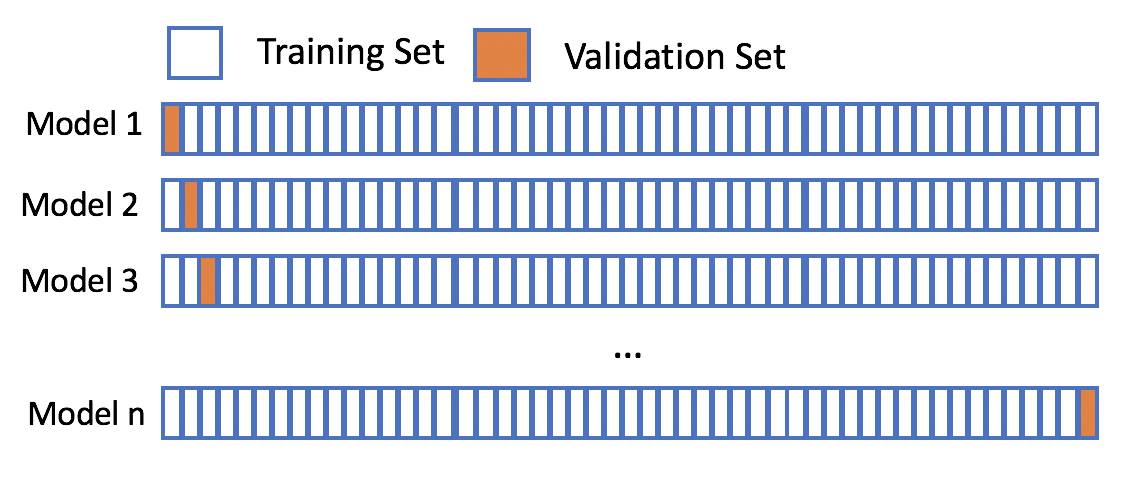
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )