MATLAB Genetic Algorithm Selection Guide: Matching Requirements, Optimizing Efficiency
发布时间: 2024-09-15 04:52:01 阅读量: 22 订阅数: 27 
# 1. Genetic Algorithm Overview
A Genetic Algorithm (GA) is an optimization algorithm inspired by biological evolution, which simulates the process of natural selection to solve complex optimization problems. GA operates through the following steps:
1. **Initialize Population:** Randomly generate a set of candidate solutions, known as a population.
2. **Evaluate Fitness:** Calculate the fitness of each solution, measuring the extent to which it addresses the target problem.
3. **Selection:** Select the fittest solutions for reproduction based on their fitness.
4. **Crossover:** Combine two or more selected solutions to create new solutions.
5. **Mutation:** Randomly modify new solutions to introduce diversity.
6. **Repeat:** Repeat steps 2-5 until reaching a predetermined stopping condition (e.g., maximum number of generations or fitness convergence).
# 2. Parameter Selection for Genetic Algorithms
The performance of a Genetic Algorithm largely depends on the settings of its parameters. These parameters control various aspects of the algorithm, from population size to crossover and mutation probabilities. In this chapter, we will explore the most important parameters in Genetic Algorithms and discuss how to choose their optimal values.
### 2.1 Population Size and Generations
**Population Size** refers to the number of individuals in the population. The larger the population size, the greater the search space, increasing the likelihood of finding the optimal solution. However, a larger population size also increases the computational cost.
**Generations** refer to the number of iterations the algorithm runs. More generations allow the algorithm more time to evolve the population and find better solutions. But too many generations may lead to the algorithm getting stuck in local optima.
**Parameter Selection:**
***Population Size:** Typically between 50 and 1000. Larger population sizes can be used for more complex problems.
***Generations:** Typically between 100 and 1000. Fewer generations can be used for simpler problems.
### 2.2 Crossover and Mutation Probabilities
**Crossover** is an operation in genetic algorithms that generates new individuals by exchanging the genes of two parent individuals to create offspring. The crossover probability controls how frequently crossover occurs.
**Mutation** is another operation in genetic algorithms that generates new individuals by randomly altering the genes of an individual to create offspring. The mutation probability controls how frequently mutations occur.
**Parameter Selection:**
***Crossover Probability:** Typically between 0.5 and 1.0. Higher crossover probabilities create more diversity but may disrupt useful gene combinations.
***Mutation Probability:** Typically between 0.01 and 0.1. Higher mutation probabilities increase the chance of exploring the search space but may disrupt useful genes.
### 2.3 Selection Strategies
**Selection Strategy** determines which individuals are selected as the parents of the next generation. There are many different selection strategies, each with its own advantages and disadvantages.
**Common Selection Strategies:**
***Roulette Wheel Selection:** Individuals are selected based on their fitness values, with higher fitness individuals having a greater chance of being selected.
***Tournament Selection:** A small subset of individuals is randomly selected from the population, and the individual with the highest fitness value in this subset is chosen.
***Elitism Selection:** The best individuals from the population are always carried over to the next generation.
**Parameter Selection:**
***Selection Strategy:** Depends on the specific nature of the problem. Roulette wheel selection is suitable for problems with a larger population size, while tournament selection is suitable for problems with a smaller population size. Elitism is often used to prevent the population from losing useful genes.
**Code Example:**
```python
import random
def roulette_wheel_selection(population):
"""
Perform roulette wheel selection based on fitness values.
Parameters:
population: The population, where each element represents an individual.
Returns:
The selected individual.
"""
# Calculate total fitness
total_fitness = sum(individual.fitness for individual in population)
# Generate a random number between 0 and total fitness
random_value = random.uniform(0, total_fitness)
# Accumulate individual fitness values until the random value is exceeded
for individual in population:
random_value -= individual.fitness
if random_value <= 0:
return individual
# If no individual is found, return the last individual
return population[-1]
```
# 3. Genetic Algorithm Implementation
### 3.1 MATLAB Genetic Algorithm Toolbox
The MATLAB Genetic Algorithm Toolbox is a collection of tools specifically designed for genetic algorithms. It provides a variety of features, including:
- **Population Creation and Management:** `gapopulation`, `gareplace`
- **Crossover and Mutation Operations:** `crossover`, `mutation`
- **Selection Strategies:** `selection`
- **Fitness Functions:** `fitnessfcn`
- **Algorithm Control:** `gaoptimset`
**Example Code:**
```matlab
% Create a population
population = gapopulation(100, 10);
% Set crossover and mutation probabilities
options = g
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
自然语言处理中的独热编码:应用技巧与优化方法
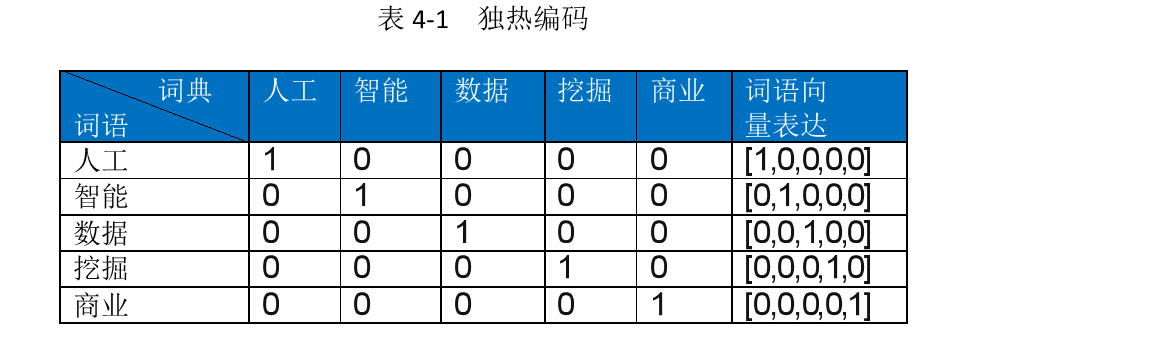
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
测试集在回归测试中的应用:防止回归错误
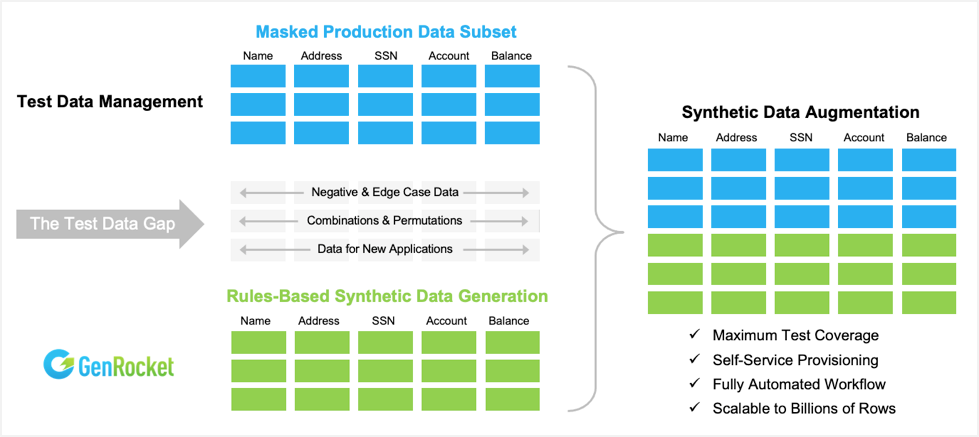
# 1. 回归测试的重要性与测试集概念
在软件开发领域,回归测试(Regression Testing)是确保软件质量的必要手段,它通过重复执行已经验证过的测试用例,以确定新的代码修改没有引入新的缺陷。测试集(Test Suite)则是指一组用于执行回归测试的测试用例和相关测试数据的集合。
## 1.1 回归测试的重要性
回归测试在软件开发生命周期中扮演着至关重要的角色,尤其是在维护阶段。随
探索性数据分析:训练集构建中的可视化工具和技巧
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )