Analyzing Common Issues with MATLAB Genetic Algorithms: Overcoming Obstacles on the Path to Optimization
发布时间: 2024-09-15 04:42:43 阅读量: 27 订阅数: 35 

Cleaning and Analyzing Real-World Sensor Data Webinar Files:Demo Files from Cleaning and analysis real-world sensor data with MATLAB Webinar-matlab开发
# 1. Overview of MATLAB Genetic Algorithm
Genetic algorithms are optimization algorithms inspired by biological evolution, which use the principles of natural selection and genetic variation to solve complex optimization problems. In MATLAB, genetic algorithms can be implemented using the Genetic Algorithm and Direct Search Toolbox (ga).
The optimization process of a genetic algorithm includes:
- **Initialization of Population:** Randomly generate a set of candidate solutions called a population.
- **Fitness Evaluation:** Calculate the fitness of each solution, which indicates the extent to which the solution meets the optimization goals.
- **Selection:** Select the best solutions for reproduction based on their fitness.
- **Crossover:** Exchange genetic information between two selected solutions to produce new solutions.
- **Mutation:** Randomly modify certain features of new solutions to introduce diversity.
- **Iteration:** Repeat the above steps until a termination condition is met (e.g., reaching the maximum number of iterations or finding the optimal solution).
# 2. Theoretical Foundations of Genetic Algorithms
### 2.1 Basic Principles of Genetic Algorithms
Genetic algorithms (GA) are optimization algorithms inspired by natural selection and evolutionary theory. They simulate the process of biological evolution through operations such as selection, crossover, and mutation, continuously optimizing individuals in the population until an optimal or near-optimal solution is found.
The basic principles of GA are as follows:
1. **Initialization:** Generate a random population of individuals, each representing a candidate solution.
2. **Fitness Evaluation:** Calculate the fitness of each individual, which measures the quality of how well an individual solves the problem.
3. **Selection:** Select individuals with better performance in the population for the next generation based on their fitness.
4. **Crossover:** Perform crossover on two selected individuals, producing new individuals that inherit some features from their parents.
5. **Mutation:** Mutate new individuals to introduce randomness and prevent the algorithm from getting stuck in local optima.
6. **Iteration:** Repeat steps 2-5 until a termination condition is met (e.g., reaching the maximum number of iterations or no further improvement in fitness).
### 2.2 Encoding and Decoding in Genetic Algorithms
**Encoding**
In GA, individuals are usually encoded using chromosomes. A chromosome is a string of binary bits or other representations that signify individual characteristics. The choice of encoding method depends on the type of problem. For instance, for continuous optimization problems, chromosomes can be encoded as real numbers; for combinatorial optimization problems, chromosomes can be encoded as integers or permutations.
**Decoding**
Decoding is the process of converting chromosomes into actual solutions to the problem. The decoding function converts the bits or other representations in chromosomes into feasible solutions to the problem. For instance, for continuous optimization problems, the decoding function converts binary bits in chromosomes into real numbers; for combinatorial optimization problems, the decoding function converts integers or permutations in chromosomes into feasible permutations or combinations.
### 2.3 Optimization Process of Genetic Algorithms
The optimization process of GA is as follows:
1. **Fitness Calculation:** Calculate the fitness of each individual, which is usually determined by the problem's objective function.
2. **Selection:***mon selection methods include roulette wheel selection, tournament selection, and rank selection.
3. **Crossover:***mon crossover methods include single-point crossover, two-point crossover, and uniform crossover.
4. **Mutation:***mon mutation methods include bit flip mutation, swap mutation, and insertion mutation.
5. **Elite Retention:** Directly replicate the individuals with the highest fitness in the current population to the next generation to maintain the best individuals in the population.
6. **Iteration:** Repeat steps 1-5 until a termination condition is met (e.g., reaching the maximum number of iterations or no further improvement in fitness).
**Code Block:**
```matlab
% Initialize population
population = rand(populationSize, chromosomeLength);
% Evaluate fitness
f
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
霍尼韦尔SIS系统性能优化大揭秘:可靠性提升的关键步骤

# 摘要
霍尼韦尔安全仪表系统(SIS)作为保障工业过程安全的关键技术,其性能优化对于提高整体可靠性、可用性和可维护性至关重要。本文首先介绍了SIS系统的基础知识、关键组件
【Ansys电磁场分析】:掌握网格划分,提升仿真准确度的关键
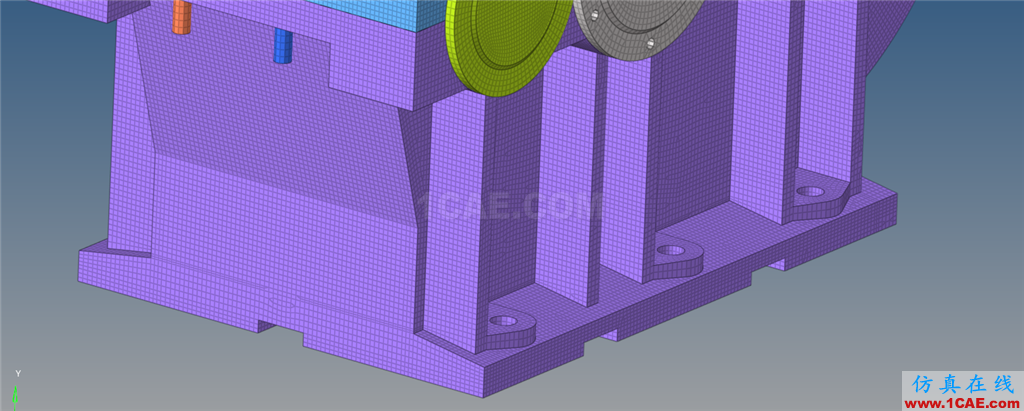
# 摘要
本文详细探讨了Ansys软件中电磁场分析的网格划分技术,从理论基础到实践技巧,再到未来发展趋势。首先,文章概述了网格划分的概念、重要性以及对电磁场分析准确度的影响。接着,深入分析了不同类型的网格、网格质量指标以及自适应技术和网格无关性研究等实践技巧。通过案例分析,展示了网格划分在平面电磁波、复杂结构和高频电磁问题中的应用与优化策略。最后,讨论了网格划分与仿真准确度的关联,并对未来自动网
故障排查的艺术:H9000系统常见问题与解决方案大全

# 摘要
H9000系统作为本研究的对象,首先对其进行了全面的概述。随后,从理论基础出发,分析了系统故障的分类、特点、系统日志的分析以及故障诊断工具与技巧。本研究深入探讨了H9000系统在实际运行中遇到的常见问题,包括启动失败、性能问题及网络故障的排查实例,并详细阐述了这些问题的解决策略。在深入系统核心的故障处理方面,重点讨论
FSCapture90.7z跨平台集成秘籍:无缝协作的高效方案
# 摘要
本文旨在详细介绍FSCapture90.7z软件的功能、安装配置以及其跨平台集成策略。首先,文中对FSCapture90.7z的基本概念、系统要求和安装步骤进行了阐述,接着探讨了配置优化和文件管理的高级技巧。在此基础上,文章深入分析了FSCapture90.
【N-CMAPSS数据集深度解析】:实现大规模数据集高效存储与分析的策略
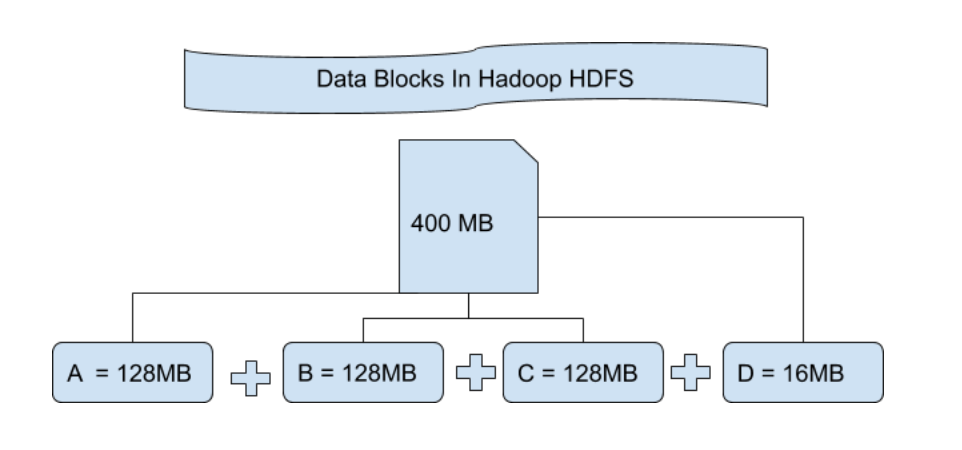
# 摘要
N-CMAPSS数据集作为一项重要资源,提供了深入了解复杂系统性能与故障预测的可能性。本文首先概述了N-CMAPSS数据集,接着详细探讨了大规模数据集的存储与分析方法,涵盖了存储技术、分析策略及深度学习应用。本文深入研究了数据集存储的基础、分布式存储系统、存储系统的性能优化、数据预处理、高效数据分析算法以及可视化工具的使用。通过案例分析,本文展示了N
【Spartan7_XC7S15硬件设计精讲】:精通关键组件与系统稳定性
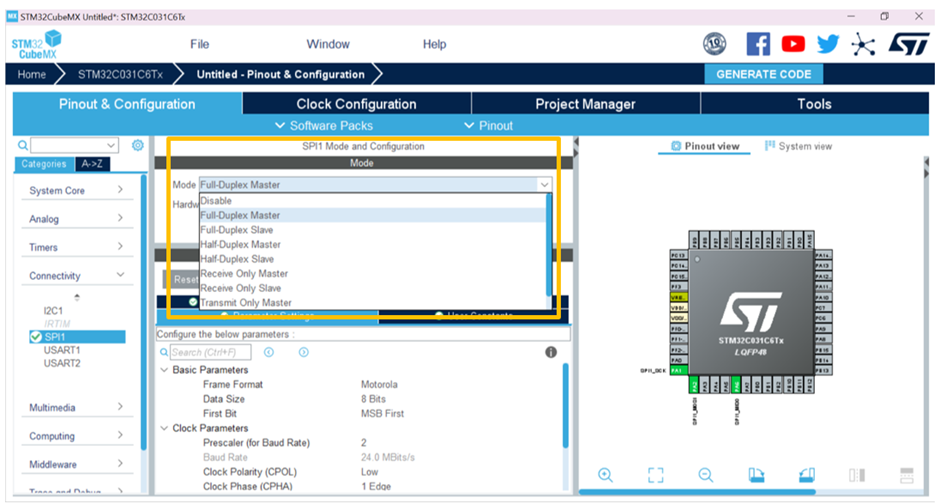
# 摘要
本文对Xilinx Spartan7_XC7S15系列FPGA硬件进行了全面的分析与探讨。首先概述了硬件的基础架构、关键组件和设计基础,包括FPGA核心架构、输入/输出接口标准以及电源与散热设计。随后,本文深入探讨了系统稳定性优化的策略,强调了系统级时序分析、硬件故障诊断预防以及温度和环境因素对系统稳定性的影响。此外,通过案例分析,展示了S
MAX7000芯片时序分析:5个关键实践确保设计成功

# 摘要
本文系统地介绍了MAX7000芯片的基础知识、时序参数及其实现和优化。首先概述了MAX7000芯片的基本特性及其在时序基础方面的重要性。接着,深入探讨了时序参数的理论概念,如Setup时间和Hold时间,时钟周期与频率,并分析了静态和动态时序分析方法以及工艺角对时序参数
Acme财务状况深度分析:稳健增长背后的5大经济逻辑

# 摘要
本论文对Acme公司进行了全面的财务分析,涵盖了公司的概况、收入增长、盈利能力、资产与负债结构以及现金流和投资效率。通过对Acme主营业务的演变、市
机器人集成实战:SINUMERIK 840D SL自动化工作流程高效指南
# 摘要
本文旨在全面介绍SINUMERIK 840D SL自动化系统,从理论基础与系统架构出发,详述其硬件组件和软件架构,探讨自动化工作流程的理论以及在实际操作中的实现和集成。文中深入分析了SINUMERIK 840D SL的程序设计要点,包括NC程序的编写和调试、宏程序及循环功能的利用,以及机器人通信集成的机制。同时,通过集成实践与案例分析,展示自动化设备集成的过程和关键成功因素。此外,本文还提出了维护与故障诊断的策略,并对自动化技术的未来趋势与技术创新进行了展望。
# 关键字
SINUMERIK 840D SL;自动化系统;程序设计;设备集成;维护与故障诊断;技术革新
参考资源链接:
单片机与HT9200A交互:数据流与控制逻辑的精妙解析

# 摘要
本文旨在全面介绍单片机与HT9200A芯片之间的交互原理及实践应用。首先概述了单片机与HT9200A的基本概念和数据通信基础知识,随后深入解析了HT9200A的串行通信协议、接口电路设计以及关键引脚功能。第二部分详细探讨了HT9200A控制逻辑的实现,包括基本控制命令的发送与响应、复杂控制流程的构建,以及错误检测和异常处理机制。第三章将理论应用于实践,指导读者
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )