Ethical Considerations of Genetic Algorithms in MATLAB: Responsible Use of Optimization Technologies
发布时间: 2024-09-15 04:50:26 阅读量: 22 订阅数: 36 

Ethical issues of behavior modification research in schools
# 1. Introduction to MATLAB Genetic Algorithms
MATLAB Genetic Algorithm (GA) is a powerful optimization tool that simulates the process of natural selection to solve complex problems. GA follows these steps:
***Initialization:** Randomly generate a set of candidates called chromosomes.
***Selection:** Choose the fittest chromosomes based on their quality (i.e., the quality of the solutions).
***Crossover:** Combine two selected chromosomes to create new ones.
***Mutation:** Randomly modify new chromosomes to introduce diversity.
***Repetition:** Repeat these steps until a stopping condition is met (e.g., reaching the maximum number of iterations or finding the optimal solution).
The advantages of GA include:
***Robustness:** Capable of handling complex, nonlinear problems.
***Global Search:** Avoids getting stuck in local optima.
***Parallelization:** Performance can be enhanced through parallel processing.
# 2. Ethical Considerations of Genetic Algorithms
Genetic Algorithms (GAs) are widely used as powerful optimization tools across various domains. However, as their influence grows, so does the attention on their ethical implications. This chapter delves into the ethical considerations of GAs, including bias and discrimination, transparency and interpretability, and responsibility and accountability.
### 2.1 Bias and Discrimination
#### 2.1.1 Sources of Bias in Algorithms
GAs may produce bias due to:
- **Bias in training data:** If the training data itself is biased, GAs may learn and amplify these biases.
- **Algorithm design:** Parameters and selection strategies in GA algorithms can lead to bias, for example, excessive selection pressure may cause the algorithm to converge on local optima, ignoring potentially fairer solutions.
- **Human intervention:** The development and deployment of GA algorithms involve human decision-making, which can introduce bias, such as the selection of specific features or objective functions.
#### 2.1.2 Methods to Mitigate Bias
Mitigating bias in GA algorithms is crucial and can be achieved through:
- **Ensuring fairness in training data:** Collecting and preprocessing training data should ensure its fairness and representativeness, avoiding bias.
- **Optimizing algorithm parameters:** Adjust GA parameters through cross-validation and hyperparameter optimization to maximize fairness and generalization.
- **Introducing fairness constraints:** Incorporate fairness constraints in GA algorithms to ensure the solutions meet specific fairness standards.
- **Using fairness metrics:** Employ fairness metrics like disparate impact or fairness index to evaluate the fairness of GA algorithms.
### 2.2 Transparency and Interpretability
#### 2.2.1 Challenges to GA Transparency
GA transparency and interpretability face challenges due to:
- **Algorithm complexity:** GAs involve multiple components and parameters, making them difficult to understand and interpret.
- **Randomness:** The randomness of GA algorithms increases the difficulty of interpretability, as results may vary with each run.
- **Black-box models:** Some GAs are considered black-box models, meaning their internal workings are difficult to comprehend.
#### 2.2.2 Strategies to Improve Interpretability
Improving GA interpretability is vital and can be achieved through:
- **Visualization:** Use visualization techniques such as decision trees or scatter plots to display the running process and results of GA algorithms.
- **Simplifying algorithms:** Simplify GAs to make them easier to understand and interpret while maintaining their optimization capabilities.
- **Interpretability methods:** Use interpretability methods like SHAP or LIME to explain the decision-making process of GA algorithms.
- **Documentation:** Document the design, implementation, and evaluation process of GA algorithms in detail to improve transparency.
### 2.3 Responsibility and Accountability
#### 2.3.1 Responsibilities of GA Developers
GA developers have the following responsibilities:
- **Ensuring fairness and interpretability:** Developers should take measures to ensure GA algorithms are fair and interpretable and consider their potential ethical impacts.
- **Providing transparency and documentation:** Developers should provide transparency and documentation for their algorithms, allowing users to understand their workings and limitations.
- **Education and training:** Developers should educate and train users of their algorithms, helping them understand their ethical impacts and responsible use practices.
#### 2.3.2 Responsibilities of GA Users
GA users have the following responsibilities:
- **Understanding the ethical implications:** Users should be aware of the potential ethical implications of GA algorithms and consider their fairness and interpretability when using them.
- **Using algorithms responsibly:** Users should use GA algorithms responsibly, avoiding the creation or amplification of bias and discrimination.
- **Evaluating algorithm performance and bias:** Users should assess the performance and bias of GA algorithms and take steps to mitigate any negative impacts.
# 3. Responsible GA Practices
### 3.1 Data Collection and Preprocessing
#### 3.1.1 Ensuring Data Fairness and Representativeness
Responsible GA practices begin with ensuring that the data used for training and evaluating algorithms is fair and representative. This is critical to prevent bias and d

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网络工程师的WLC3504配置宝典:实现无线网络的极致性能
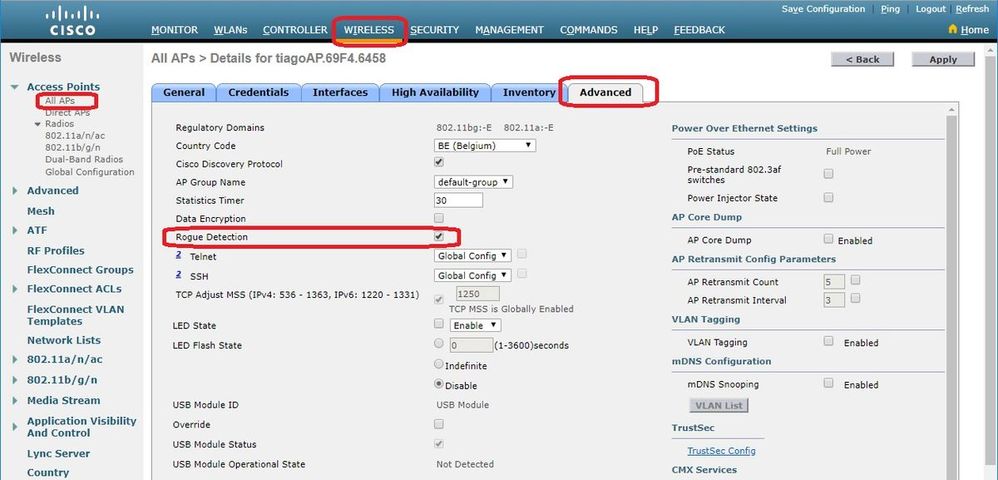
# 摘要
本文档旨在为网络工程师提供一份全面的WLC3504无线控制器配置与管理宝典。首先,介绍了WLC3504的基础理论,包括其工作原理、架构、关键功能和技术指标,以及在802.11协议中的应用。其次,详细探讨了WLC3504的配置实战技巧,涵盖基础设置、高级网络特
PCB设计最佳实践揭露:Allegro 172版中DFA Package spacing的高效应用
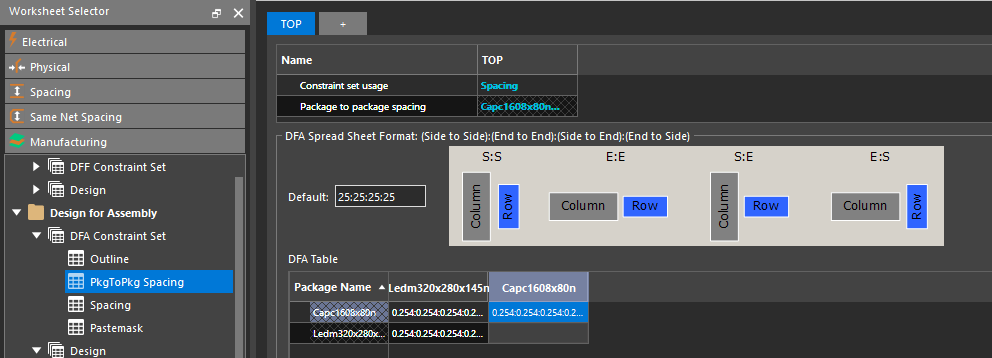
# 摘要
本文深入探讨了Allegro PCB设计中DFA Package spacing的理论与实践,强调了其在提高PCB设计性能方面的重要性。通过对DFA Package spacing参数设置的分析,本文展示了在设计前
ME系列存储数据保护全方案:备份、恢复与灾备策略揭秘

# 摘要
随着信息技术的快速发展,数据保护变得日益重要。本文全面概述了ME系列存储的数据保护重要性,并深入探讨了其数据备份策略、数据恢复流程以及灾备策略与实施。首先,文章介绍了数据备份的基础理论与ME系列存储的备份实践。随后,详细阐述了数据恢复的理论框架和具体操作步骤,以及不同场景下的恢复策略。文章进一步分析了灾备策略的理论与实践,包括构建灾备环境和灾备演练。最后,探讨
【专家指南】RTL8188EE无线网络卡的性能调优与故障排除(20年经验分享)

# 摘要
本文对RTL8188EE无线网络卡进行详尽的性能调优和故障排除分析。首先,概述了RTL8188EE无线网络卡的特点,然后深入探讨了影响性能的硬件指标、软件优化以及网络环境因素。实战技巧章节详细阐述了驱动程序升级、硬件优化、系统性能提升的具体方法。此外,本文还提供了故障排除的策略和技巧,包括故障诊断步骤、驱动相关问题处理以及硬件故障的识别与修复。最后,通过案例
光学仿真误差分析:MATLAB中的策略与技巧
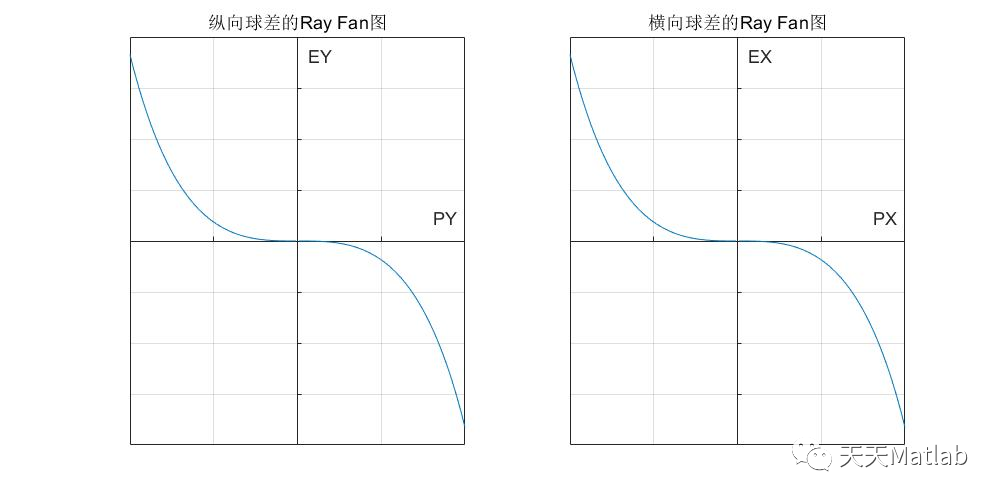
# 摘要
随着光学技术的快速发展,光学仿真正变得日益重要。本文系统地介绍了光学仿真基础,并重点阐述了在MATLAB环境下的数学模型构建、误差分析、以及仿真软件的集成应用。文章详细分析了光学系统的数学建模原理,探讨了在MATLAB中的具体实现方法,并对仿真中可能遇到的误差源进行了分类与分析。此外,本文还论述了光学仿真软件与MATLAB的集成技术,以及如何利用MATLAB解决光学仿真中遇到的
【游戏开发艺术】《弹壳特攻队》网络编程与多线程同步机制

# 摘要
本文全面探讨了游戏开发中网络编程与多线程同步机制的应用与实践,为游戏开发者提供了深入理解网络通信基础、多线程编程模型以及同步机制原理与实现的视角。通过分析《弹壳特攻队》的网络架构和多线程应用,本文强调了线程同步在游戏开发中的重要性,并探讨了同步策略对游戏体验和性能的影响。文章还展望了网络编程和多线程技术的未来趋势,包括协议创新、云游戏、分布式架构以及
【模块化思维构建高效卷积块】:策略与实施技巧详解
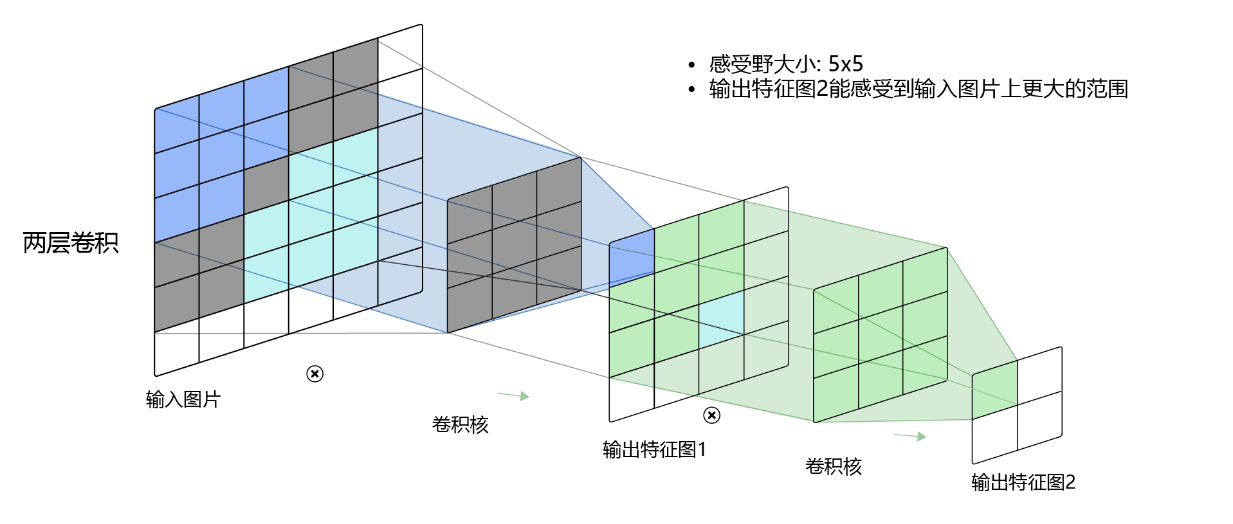
# 摘要
模块化思维在深度学习中扮演着至关重要的角色,尤其在卷积神经网络(CNN)的设计与优化中。本文首先介绍了模块化思维的基本概念及其在深度学习中的重要性。随后,详细阐述了卷积神经网络的基础知识,包括数学原理、结构组件以及卷积块的设计原则。紧接着,文章深入探讨了高效卷积块的构建策略,分析了不同的构建技巧及其优化技术。在模块化卷积块的实施方面,本文提出了集成与融合的方法,并对性能评估
【指示灯状态智能解析】:图像处理技术与算法实现

# 摘要
本文全面概述了图像处理技术及其在智能指示灯状态解析系统中的应用。首先介绍了图像处理的基础理论和关键算法,包括图像数字化、特征提取和滤波增强技术。接着,深入探讨了智能指示灯状态解析的核心算法,包括图像预处理、状态识别技术,以及实时监测与异常检测机制。文章第四章着重讲解了深度学习技术在指示灯状态解析中的应用,阐述了深度学习模型的构建、训练和优化过程,以及模型在实际系统中的部署策略。最后,通过
版本控制成功集成案例:Synergy与Subversion
# 摘要
版本控制作为软件开发的基础设施,在保障代码质量和提高开发效率方面扮演着关键角色。本文旨在通过深入分析Synergy与Subversion版本控制系统的原理、架构、特性和应用,阐明二者在企业中的实际应用价值。同时,文章还探讨了将Synergy与Subversion进行集成的策略、步骤及挑战,并通过案例研究来展示集成成功后的效
工程理解新高度:PDMS管道建模与3D可视化的融合艺术
# 摘要
PDMS管道建模与3D可视化技术的融合为工程设计、施工和维护提供了强大的支持工具。第一章介绍了PDMS管道建模的基础知识,第二章详细探讨了3D可视化技术在PDMS中的应用,包括理论基础、数学基础与算法以及用户体验设计。第三章涵盖了PDMS管道建模的高级功能实现,包括模型细化、优化和流程仿真。第四章展示了PDMS
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )