Boosting OpenCV Application Performance: Detailed Tips for Optimizing OpenCV Performance, from Code Optimization to Parallel Processing
发布时间: 2024-09-15 10:47:51 阅读量: 27 订阅数: 28 
# 1. Overview of OpenCV Performance Optimization**
OpenCV (Open Source Computer Vision Library) is a powerful computer vision library extensively used in image processing, video analysis, and machine learning fields. However, as application scenarios become more complex, performance optimization of OpenCV programs becomes crucial.
This guide will delve into all aspects of OpenCV performance optimization, including code optimization techniques, parallel processing, hardware acceleration, performance analysis, and tuning strategies. By following these best practices, developers can significantly improve the performance of OpenCV programs, meeting requirements such as real-time processing and high throughput.
# 2. OpenCV Code Optimization Techniques
### 2.1 Data Structure Optimization
#### 2.1.1 Avoiding Unnecessary Copies
**Optimization Goal:** Reduce memory allocation and copy operations for improved program efficiency.
**Optimization Methods:**
- **Using References or Pointers:** Pass references or pointers to avoid copying entire objects.
- **Using Shared Memory:** Store data in shared memory to avoid multiple copies.
- **Using Views:** Create views of data without creating copies.
**Code Example:**
```cpp
// Avoid unnecessary copying
cv::Mat image1 = cv::imread("image.jpg");
cv::Mat image2 = image1.clone(); // A copy of the image
// Using a reference to avoid copying
cv::Mat& image2 = image1; // Referencing the image
```
**Logical Analysis:**
In the first example, `image2` is a copy of `image1`, requiring new memory allocation and data copying. In the second example, `image2` references `image1`, avoiding unnecessary copying.
#### 2.1.2 Using the Right Containers
**Optimization Goal:** Select appropriate container structures to enhance data access efficiency.
**Optimization Methods:**
- **Using Vectors:** Store contiguous data elements for fast random access.
- **Using Lists:** Store non-contiguous data elements for fast insertion and deletion.
- **Using Hash Tables:** Store key-value pairs for quick lookup operations.
**Code Example:**
```cpp
// Using a vector to store contiguous data
std::vector<int> numbers = {1, 2, 3, 4, 5};
// Using a list to store non-contiguous data
std::list<std::string> names = {"John", "Mary", "Bob"};
// Using a hash table to store key-value pairs
std::unordered_map<std::string, int> ages = {{"John", 25}, {"Mary", 30}, {"Bob", 35}};
```
**Logical Analysis:**
`std::vector` is used for storing contiguous integers, `std::list` for non-contiguous strings, and `std::unordered_map` for key-value pairs. These container structures provide optimal data access efficiency.
### 2.2 Algorithm Optimization
#### 2.2.1 Choosing Efficient Algorithms
**Optimization Goal:** Select algorithms with better time and space complexity to improve program performance.
**Optimization Methods:**
- **Using Quick Sort:** Time complexity of O(n log n) and space complexity of O(log n).
- **Using Hash Table Lookups:** Time complexity of O(1) and space complexity of O(n).
- **Using Binary Search:** Time complexity of O(log n) and space complexity of O(1).
**Code Example:**
```cpp
// Using quick sort
std::vector<int> numbers = {1, 5, 2, 4, 3};
std::sort(numbers.begin(), numbers.end());
// Using hash table lookups
std::unordered_map<std::string, int> ages = {{"John", 25}, {"Mary", 30}, {"Bob", 35}};
int age = ages["John"];
// Using binary search
std::vector<int> numbers = {1, 2, 3, 4, 5};
int index = std::binary_search(numbers.begin(), numbers.end(), 3);
```
**Logical Analysis:**
`std::sort` employs the quick sort algorithm, `std::unordered_map` uses hash table lookups, and `std::binary_search` uses the binary search algorithm, providing superior time and space complexity.
#### 2.2.2 Reducing Unnecessary Computations
**Optimization Goal:** Avoid redundant calculations to improve program efficiency.
**Optimization Methods:**
- **Using Cachin

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
自然语言处理中的独热编码:应用技巧与优化方法
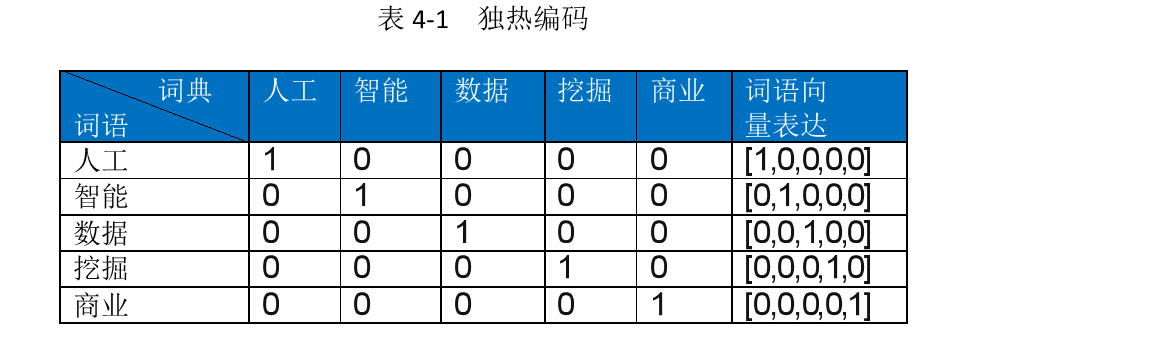
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
数据多样性:5个方法评估训练集的代表性及其对泛化的影响
# 1. 数据多样性的重要性与概念
在机器学习和数据科学领域中,数据多样性是指数据集在各种特征和属性上的广泛覆盖,这对于构建一个具有强泛化能力的模型至关重要。多样性不足的训练数据可能导致模型过拟合,从而在面对新的、未见过的数据时性能下降。本文将探讨数据多样性的重要性,并明确其核心概念,为理解后续章节中评估和优化训练集代表性的方法奠定基础。我们将首先概述为什
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )