Unveiling New Features in OpenCV 5.0: Comprehensive Upgrade of Python API and Deep Learning
发布时间: 2024-09-15 10:30:15 阅读量: 63 订阅数: 42 
# Unveiling New Features in OpenCV 5.0: Comprehensive Upgrades to Python API and Deep Learning
# 1. Introduction to OpenCV 5.0
OpenCV 5.0 is a robust library for computer vision and machine learning, released in March 2023. It offers a comprehensive toolkit for image processing, computer vision, and deep learning. OpenCV 5.0 introduces numerous new features and enhancements, including:
- **Enhanced Python API:** Significant updates to the OpenCV-Python API, featuring new modules, performance optimizations, and usability improvements.
- **Deep Learning Integration:** The OpenCV-DNN module has been enhanced and integrated with popular deep learning frameworks such as TensorFlow and PyTorch.
- **Deep Learning Model Optimization:** OpenCV 5.0 introduces model compression and acceleration techniques, as well as quantization and distillation algorithms, to optimize deep learning models.
# 2. Enhanced Python API in OpenCV 5.0
OpenCV 5.0 has made significant updates to its Python API, including the introduction of new modules and functionalities, as well as performance optimizations and usability improvements. These enhancements make OpenCV a more powerful and efficient tool for Python developers engaged in computer vision and deep learning tasks.
### 2.1 Significant Updates to the Python API
#### 2.1.1 New Modules and Functionalities in OpenCV-Python
OpenCV 5.0 introduces several new modules, including:
- **cv2.dnn.experimental:** Provides experimental support for deep learning models, including model loading, inference, and training.
- **cv2.data:** Offers access to OpenCV datasets, including images, videos, and annotations.
- **cv2.datasets:** Provides access to pre-trained models and datasets for computer vision and deep learning tasks.
Additionally, several new features have been added, such as:
- **cv2.warpAffine():** Warps images using affine transformations.
- **cv2.remap():** Remaps images using custom mappings.
- **cv2.drawContours():** Draws shapes using contours.
#### 2.1.2 Performance Optimization and Usability Improvements
OpenCV 5.0 has optimized its Python API for better performance and usability. These improvements include:
- **Multithreading Support:** OpenCV now supports multithreading, allowing tasks to be executed in parallel across multiple CPU cores.
- **Memory Management Enhancements:** OpenCV 5.0 adopts new memory management strategies to reduce memory overhead and improve performance.
- **Simplified Function Signatures:** The signatures of many functions have been simplified to enhance usability and readability.
### 2.2 Integration of Python API with Deep Learning
OpenCV 5.0 has strengthened its integration of the Python API with deep learning frameworks, particularly TensorFlow and PyTorch. These enhancements allow developers to easily combine deep learning models with OpenCV's computer vision functionalities.
#### 2.2.1 Enhanced Features of OpenCV-DNN
The OpenCV-DNN module has been enhanced to support a broader range of deep learning models and tasks. These enhancements include:
- **New Model Support:** OpenCV-DNN now supports loading and inference for various deep learning models, including classification, detection, and segmentation models.
- **Quantization Support:** OpenCV-DNN now supports model quantization to reduce model size and inference time.
- **Custom Layer Support:** Developers can now create their own custom layers and integrate them into OpenCV-DNN models.
#### 2.2.2 Integration with TensorFlow and PyTorch
OpenCV 5.0 has improved integration with TensorFlow and PyTorch. These improvements include:
- **Seamless Conversion:** OpenCV-DNN models can be easily converted to TensorFlow and PyTorch models, and vice versa.
- **Interoperability:** OpenCV-DNN and TensorFlow/PyTorch models can interoperate within the same program, allowing developers to leverage the strengths of different frameworks.
- **Optimization Support:** OpenCV-DNN offers optimizations for TensorFlow and PyTorch to improve inference performance.
# 3. Upgrades in Deep Learning with OpenCV 5.0
OpenCV 5.0 has significantly upgraded its deep learning capabilities, providing powerful new tools for developers in the fields of computer vision and medical image analysis. This chapter will delve into these enhancements, including model optimization, algorithm extensions, and integration with other deep learning frameworks.
### 3.1 Optimization of Deep Learning Models
OpenCV 5.0 introduces a variety of techniques to optimize deep learning models, enhancing their performance and efficiency.
#### 3.1.1 Model Compression and Acceleration Technologies
**Model Compression** techniques improve inference speed by reducing the size and complexity of the model. OpenCV 5.0 supports various compression techniques, including:
- **Pruning:** Removing unimportant weights and neurons.
- **Quantization:** Converting floating-point weights and activations to low-precision integers.
- **Distillation:** Training a smaller student model to mimic the behavior of a larger teacher model.
**Model Acceleration** techniques improve inference speed by optimizing the execution of the model. OpenCV 5.0 supports the following acceleration techniques:
- **Parallel Computing:** Utilizing multi-core CPUs or GPUs to execute models in parallel.
- **Operator Fusion:** Merging multiple operators into a single optimized operation.
- **Memory Optimization:** Reducing the memory footprint of the model.
#### 3.1.2 Quantization and Distillation Algorithms
**Quantization** is a technique that converts floating-point weights and activations into low-precision integers. This significantly reduces the model size and memory usage, thereby speeding up inference. OpenCV 5.0 supports various quantization algorithms, including:
- **Integer Quantization:** Converting weights and activations to 8-bit or 16-bit integers.
- **Floating-point Quantization:** Converting weights and activations to low-precision floating-point numbers.
**Distillation** is a technique for training a smaller student model to imitate the behavior of a larger teacher model. This creates more compact and faster models while maintaining accuracy similar to the teacher model. OpenCV 5.0 supports the following distillation algorithms:
- **Knowledge Distillation:** Passing soft labels from the teacher model to the student model.
- **Feature Distillation:** Passing intermediate features from the teacher model to the student model.
### 3.2 Expansion of Deep Learning Algorithms
OpenCV 5.0 extends the range of deep learning algorithms, providing new functionalities for computer vision and medical image analysis.
#### 3.2.1 New Computer Vision Algorithms
OpenCV 5.0 introduces several new computer vision algorithms, including:
- **Object Detection:** New object detection algorithms such as YOLOv5 and EfficientDet.
- **Image Segmentation:** New image segmentation algorithms such as UNet and DeepLabV3+.
- **Image Generation:** New image generation algorithms such as GANs and VAEs.
#### 3.2.2 Medical Image Analysis Algorithms
OpenCV 5.0 also extends medical image analysis algorithms, including:
- **Medical Image Segmentation:** New medical image segmentation algorithms such as U-Net and V-Net.
- **Disease Diagnosis:** Deep learning-based disease diagnosis algorithms.
- **Medical Image Registration:** Algorithms for aligning different medical images.
### 3.2.3 Integration with Other Deep Learning Frameworks
OpenCV 5.0 has strengthened integration with other deep learning frameworks, including TensorFlow and PyTorch. This enables developers to easily combine OpenCV's computer vision and image processing functionalities with deep learning models from these frameworks.
- **TensorFlow:** OpenCV 5.0 offers seamless integration with TensorFlow 2.0, allowing developers to use TensorFlow models directly within OpenCV code.
- **PyTorch:** OpenCV 5.0 provides integration with PyTorch 1.0, allowing developers to combine OpenCV functionalities with PyTorch models.
With these integrations, OpenCV 5.0 provides developers with the tools needed to build robust and efficient deep learning applications.
# 4. Practical Applications of OpenCV 5.0
### 4.1 Applications of the Python API in Computer Vision
#### 4.1.1 Image Processing and Analysis
The Python API in OpenCV 5.0 has been significantly enhanced for image processing and analysis. New modules and functionalities enable developers to easily perform complex image processing tasks.
```python
import cv2
# Read image
image = cv2.imread('image.jpg')
# Convert image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Gaussian blur
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# Edge detection
edges = cv2.Canny(blur, 100, 200)
# Display images
cv2.imshow('Original', image)
cv2.imshow('Gray', gray)
cv2.imshow('Blur', blur)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**Code Logic Analysis:**
1. `cv2.imread` reads the image and stores it in the `image` variable.
2. `cv2.cvtColor` converts the image to grayscale and stores it in the `gray` variable.
3. `cv2.GaussianBlur` applies Gaussian blur to the grayscale image to remove noise and smooth the image.
4. `cv2.Canny` applies the Canny edge detection algorithm to the blurred image to detect edges in the image.
5. `cv2.imshow` displays the original image, grayscale image, blurred image, and edge-detected image.
6. `cv2.waitKey` waits for the user to press any key.
7. `cv2.destroyAllWindows` closes all OpenCV windows.
#### 4.1.2 Object Detection and Tracking
The Python API in OpenCV 5.0 also includes enhanced features for object detection and tracking. These features enable developers to build robust computer vision applications for identifying and tracking objects in images and videos.
```python
import cv2
# Load object detection model
model = cv2.dnn.readNetFromCaffe('deploy.prototxt.txt', 'mobilenet_iter_73000.caffemodel')
# Read video
cap = cv2.VideoCapture('video.mp4')
while True:
# Read frame
ret, frame = cap.read()
if not ret:
break
# Preprocess frame
blob = cv2.dnn.blobFromImage(frame, 0.007843, (300, 300), 127.5)
# Input blob into model
model.setInput(blob)
# Perform forward propagation
detections = model.forward()
# Parse detection results
for i in np.arange(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5:
x1, y1, x2, y2 = (detections[0, 0, i, 3:7] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])).astype(int)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# Display frame
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
**Code Logic Analysis:**
1. `cv2.dnn.readNetFromCaffe` loads the object detection model.
2. `cv2.VideoCapture` opens the video capture device.
3. The `while` loop iterates through the frames in the video.
4. `cv2.dnn.blobFromImage` preprocesses the frame and creates a blob.
5. `model.setInput` inputs the blob into the model.
6. `model.forward` performs forward propagation and generates detection results.
7. `np.arange` creates an index array to iterate over the detection results.
8. `confidence` variable stores the detection confidence.
9. If the confidence is greater than 0.5, extract the bounding box coordinates.
10. `cv2.rectangle` draws a bounding box on the frame.
11. `cv2.imshow` displays the frame.
12. `cv2.waitKey` waits for the user to press any key.
13. `cap.release` releases the video capture device.
14. `cv2.destroyAllWindows` closes all OpenCV windows.
### 4.2 Applications of Deep Learning in Medical Image Analysis
#### 4.2.1 Medical Image Segmentation
The deep learning capabilities of OpenCV 5.0 enable developers to build robust medical image segmentation models. These models can automatically segment anatomical structures in medical images, aiding in disease diagnosis and treatment.
```python
import cv2
import numpy as np
# Load medical image
image = cv2.imread('medical_image.jpg')
# Create segmentation model
model = cv2.dnn.readNetFromTensorflow('model.pb')
# Preprocess image
blob = cv2.dnn.blobFromImage(image, 1.0, (512, 512), (0, 0, 0), swapRB=True, crop=False)
# Input blob into model
model.setInput(blob)
# Perform forward propagation
segmentation_mask = model.forward()
# Post-process segmentation results
segmentation_mask = np.argmax(segmentation_mask, axis=2)
# Display segmentation results
cv2.imshow('Original', image)
cv2.imshow('Segmentation Mask', segmentation_mask)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**Code Logic Analysis:**
1. `cv2.imread` loads the medical image.
2. `cv2.dnn.readNetFromTensorflow` loads the segmentation model.
3. `cv2.dnn.blobFromImage` preprocesses the image and creates a blob.
4. `model.setInput` inputs the blob into the model.
5. `model.forward` performs forward propagation and generates segmentation results.
6. `np.argmax` extracts the segmentation mask.
7. `cv2.imshow` displays the original image and segmentation mask.
8. `cv2.waitKey` waits for the user to press any key.
9. `cv2.destroyAllWindows` closes all OpenCV windows.
#### 4.2.2 Disease Diagnosis and Prediction
The deep learning capabilities of OpenCV 5.0 can also be used to develop disease diagnosis and prediction models. These models can analyze medical images and predict the risk or progression of diseases.
```python
import cv2
import numpy as np
# Load medical image dataset
dataset = cv2.ml.TrainData_loadFromCSV('dataset.csv', 0, 1, 2)
# Create classification model
model = cv2.ml.SVM_create()
# Train the model
model.train(dataset)
# Load a new image for prediction
new_image = cv2.imread('new_image.jpg')
# Preprocess the new image
new_blob = cv2.dnn.blobFromImage(new_image, 1.0, (224, 224), (0, 0, 0), swapRB=True, crop=False)
# Input the new blob into the model
model.predict(new_blob)
# Get prediction result
prediction = model.getPrediction()
# Output prediction result
if prediction == 1:
print('Predicted as diseased')
else:
print('Predicted as healthy')
```
**Code Logic Analysis:**
1. `cv2.ml.TrainData_loadFromCSV` loads the medical image dataset.
2. `cv2.ml.SVM_create` creates a Support Vector Machine (SVM) classification model.
3. `model.train` trains the model.
4. `cv2.imread` loads the new image for prediction.
5. `cv2.dnn.blobFromImage` preprocesses the new image and creates a blob.
6. `model.predict` inputs the new blob into the model and performs prediction.
7. `model.getPrediction` retrieves the prediction result.
8. Outputs the disease or health status based on the prediction result.
# 5.1 Trends of OpenCV in the Field of Artificial Intelligence
### 5.1.1 OpenCV on Edge Computing and Mobile Devices
With the rapid development of edge computing and mobile devices, OpenCV is adapting to deployments on these platforms. The optimized OpenCV library can run efficiently on resource-constrained devices, enabling the implementation of computer vision and deep learning algorithms on edge devices.
### 5.1.2 Integration of OpenCV with Other AI Technologies
OpenCV is integrating with other AI technologies, such as Natural Language Processing (NLP) and Machine Learning (ML). This integration enables developers to create more powerful and comprehensive AI applications. For example, OpenCV can be combined with NLP technology to add automatic captions to images and videos or with ML technology to create models that can extract complex information from images.
## 5.2 Contributions and Developments in the OpenCV Community
### 5***
***munity members contribute code, documentation, and tutorials to support the development of OpenCV. This helps ensure that OpenCV remains up-to-date and meets the ever-changing needs of users.
### 5.2.2 Future Roadmap of OpenCV
The OpenCV community has outlined a roadmap that details the future development direction of the project. The roadmap includes ongoing improvements to performance, usability, and new features. The community is also dedicated to exploring emerging technologies such as Augmented Reality (AR) and Virtual Reality (VR), and integrating them with OpenCV.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单设计原理

# 摘要
扇形菜单作为一种创新的界面设计,通过特定的布局和交互方式,提升了用户在不同平台上的导航效率和体验。本文系统地探讨了扇形菜单的设计原理、理论基础以及实际的设计技巧,涵盖了菜单的定义、设计理念、设计要素以及理论应用。通过分析不同应用案例,如移动应用、网页设计和桌面软件,本文展示了扇形菜单设计的实际效果,并对设计过程中的常见问题提出了改进策略。最后,文章展望了扇形菜单设计的未来趋势,包括新技术的应用和设计理念的创新。
# 关键字
扇形菜
传感器在自动化控制系统中的应用:选对一个,提升整个系统性能
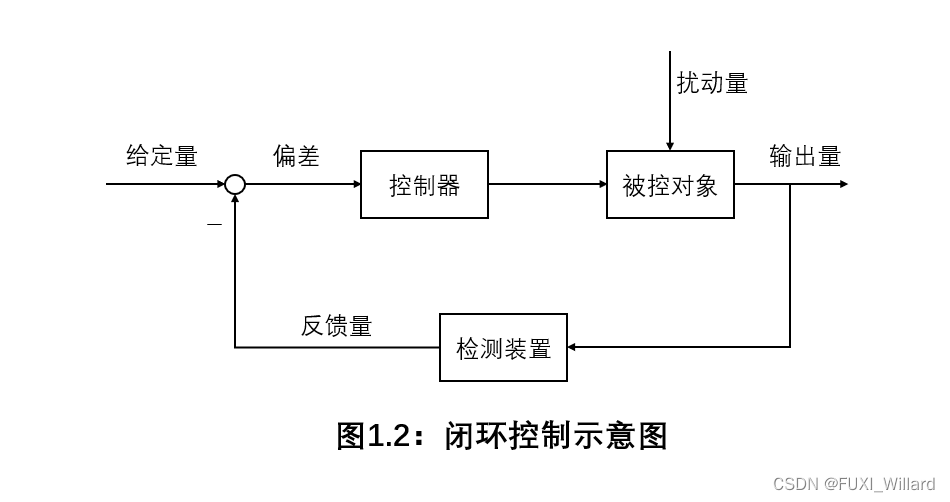
# 摘要
传感器在自动化控制系统中发挥着至关重要的作用,作为数据获取的核心部件,其选型和集成直接影响系统的性能和可靠性。本文首先介绍了传感器的基本分类、工作原理及其在自动化控制系统中的作用。随后,深入探讨了传感器的性能参数和数据接口标准,为传感器在控制系统中的正确集成提供了理论基础。在此基础上,本文进一步分析了传感器在工业生产线、环境监测和交通运输等特定场景中的应用实践,以及如何进行
CORDIC算法并行化:Xilinx FPGA数字信号处理速度倍增秘籍

# 摘要
本文综述了CORDIC算法的并行化过程及其在FPGA平台上的实现。首先介绍了CORDIC算法的理论基础和并行计算的相关知识,然后详细探讨了Xilinx FPGA平台的特点及其对CORDIC算法硬件优化的支持。在此基础上,文章具体阐述了CORDIC算法
C++ Builder调试秘技:提升开发效率的十项关键技巧
# 摘要
本文详细介绍了C++ Builder中的调试技术,涵盖了从基础知识到高级应用的广泛领域。文章首先探讨了高效调试的准备工作和过程中的技巧,如断点设置、动态调试和内存泄漏检测。随后,重点讨论了C++ Builder调试工具的高级应用,包括集成开发环境(IDE)的使用、自定义调试器及第三方工具的集成。文章还通过具体案例分析了复杂bug的调试、
MBI5253.pdf高级特性:优化技巧与实战演练的终极指南
# 摘要
MBI5253.pdf作为研究对象,本文首先概述了其高级特性,接着深入探讨了其理论基础和技术原理,包括核心技术的工作机制、优势及应用环境,文件格式与编码原理。进一步地,本文对MBI5253.pdf的三个核心高级特性进行了详细分析:高效的数据处理、增强的安全机制,以及跨平台兼容性,重点阐述了各种优化技巧和实施策略。通过实战演练案
【Delphi开发者必修课】:掌握ListView百分比进度条的10大实现技巧

# 摘要
本文详细介绍了ListView百分比进度条的实现与应用。首先概述了ListView进度条的基本概念,接着深入探讨了其理论基础和技术细节,包括控件结构、数学模型、同步更新机制以及如何通过编程实现动态更新。第三章
先锋SC-LX59家庭影院系统入门指南
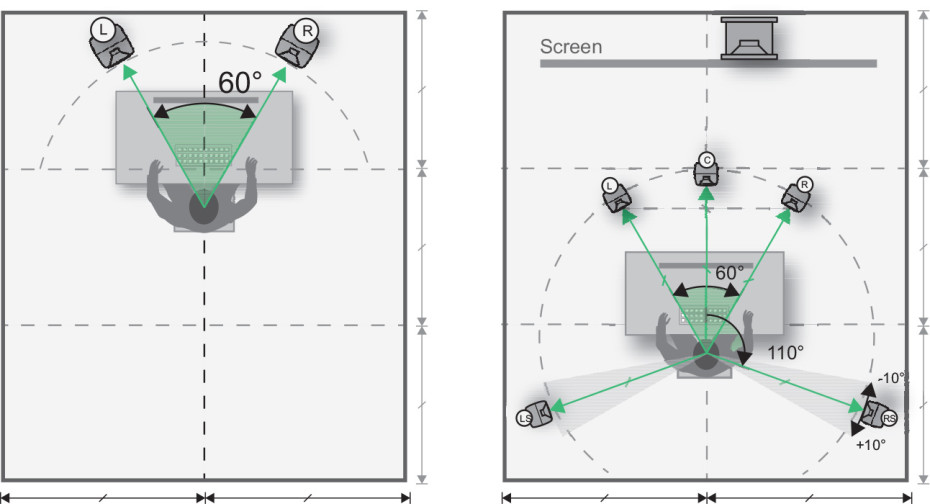
# 摘要
本文全面介绍了先锋SC-LX59家庭影院系统,从基础设置与连接到高级功能解析,再到操作、维护及升级扩展。系统概述章节为读者提供了整体架构的认识,详细阐述了家庭影院各组件的功能与兼容性,以及初始设置中的硬件连接方法。在高级功能解析部分,重点介绍了高清音频格式和解码器的区别应用,以及个
【PID控制器终极指南】:揭秘比例-积分-微分控制的10个核心要点

# 摘要
PID控制器作为工业自动化领域中不可或缺的控制工具,具有结构简单、可靠性高的特点,并广泛应用于各种控制系统。本文从PID控制器的概念、作用、历史发展讲起,详细介绍了比例(P)、积分(I)和微分(D)控制的理论基础与应用,并探讨了PID
【内存技术大揭秘】:JESD209-5B对现代计算的革命性影响
# 摘要
本文详细探讨了JESD209-5B标准的概述、内存技术的演进、其在不同领域的应用,以及实现该标准所面临的挑战和解决方案。通过分析内存技术的历史发展,本文阐述了JESD209-5B提出的背景和核心特性,包括数据传输速率的提升、能效比和成本效益的优化以及接口和封装的创新。文中还探讨了JESD209-5B在消费电子、数据中心、云计算和AI加速等领域的实
【install4j资源管理精要】:优化安装包资源占用的黄金法则

# 摘要
install4j是一款强大的多平台安装打包工具,其资源管理能力对于创建高效和兼容性良好的安装程序至关重要。本文详细解析了install4j安装包的结构,并探讨了压缩、依赖管理以及优化技术。通过对安装包结构的深入理解,本文提供了一系列资源文件优化的实践策略,包括压缩与转码、动态加载及自定义资源处理流程。同时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )