Concurrent Operations and Lock Mechanisms on Unordered Maps
发布时间: 2024-09-15 18:30:56 阅读量: 23 订阅数: 26 

深入Synchronized和java.util.concurrent.locks.Lock的区别详解
# Introduction
In programming, unlocked operations can lead to data races and unpredictable outcomes, causing program crashes or abnormal behavior. Concurrent operations refer to the situation where multiple threads or processes access shared resources at the same time, and special attention is needed when performing concurrent operations on unordered_map. Unordered_map is a hash table container provided by C++ STL, which has fast lookup and insertion performance. In concurrent programming, it is necessary to understand the basic concepts and challenges of concurrent operations, as well as the usage and precautions of locking mechanisms. This article will introduce the basic concepts of unordered_map, the basics of concurrent programming, and how to perform concurrent operations on unordered_map, helping readers better understand the tips for using unordered_map in concurrent programming.
# Basic Concepts of unordered_map
Unordered_map, or unordered hash table, is an associative container in C++ STL. Unlike map, the elements in unordered_map are stored in an unordered manner, and the fast lookup is achieved through a hash table. In unordered_map, each element is a key-value pair, and the relationship between key and value is one-to-one. Unordered_map provides fast lookup, insertion, and deletion operations, making it suitable for scenarios where fast element lookup is required.
#### Introduction to unordered_map
Unordered_map is defined in the `<unordered_map>` header file, with the syntax `std::unordered_map<key_type, value_type>`. Here, `key_type` represents the type of the key, and `value_type` represents the type of the value. Unordered_map uses a hash table to store data, allowing it to complete lookup operations in O(1) time.
#### The underlying implementation of unordered_map
The underlying implementation of unordered_map is based on the data structure of a hash table. When inserting an element, the hash value is first calculated based on the key, and then the value is stored at the corresponding position in the hash table. When looking up an element, the hash value is also calculated based on the key, and then the element at the corresponding position in the hash table is searched for. Due to the excellent design of the hash function, elements can be evenly distributed in the hash table, thus achieving fast lookup operations.
#### Characteristics of unordered_map
Unordered_map has the following characteristics:
- The time complexity of lookup, insertion, and deletion operations is O(1), which is very efficient.
- The storage of elements is unordered, and they will not be arranged in order of key size.
- Unordered_map uses a hash table to store data, which can provide high performance for large datasets.
- Compared with map, the iteration order of unordered_map is uncertain because the storage of elements is unordered.
# Basics of Concurrent Programming
#### What is Concurrent Programming
Concurrent programming refers to a programming paradigm where multiple computational tasks are performed simultaneously. In computer systems, multiple tasks are executed simultaneously through time-slicing rotation, as CPUs cannot truly process multiple tasks at the same time. The purpose of concurrent programming is to improve system utilization and performance.
Concurrent programming can

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
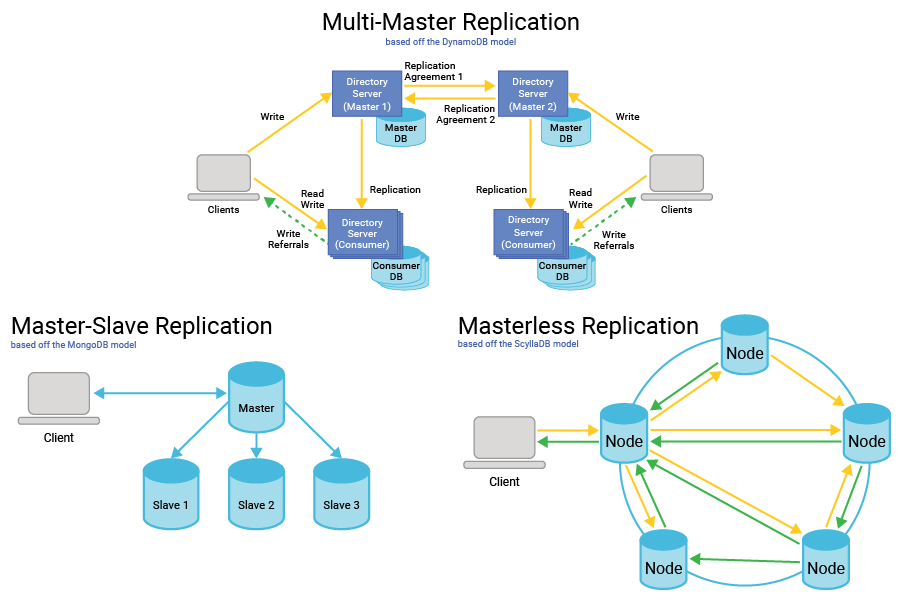
【数据一致性守护神】:ClusterEngine浪潮集群数据同步与维护攻略
# 摘要
ClusterEngine集群技术在现代分布式系统中发挥着核心作用,本文对ClusterEngine集群进行了全面概述,并详细探讨了数据同步的基础理论与实践方法,包括数据一致性、同步机制以及同步技术的选型和优化策略。此外,文章深入分析了集群的维护与管理,涵盖配置管理、故障排除以及安全性加固。在高级应用方面,探讨了数据备份与恢复、负载均衡、高可用架构
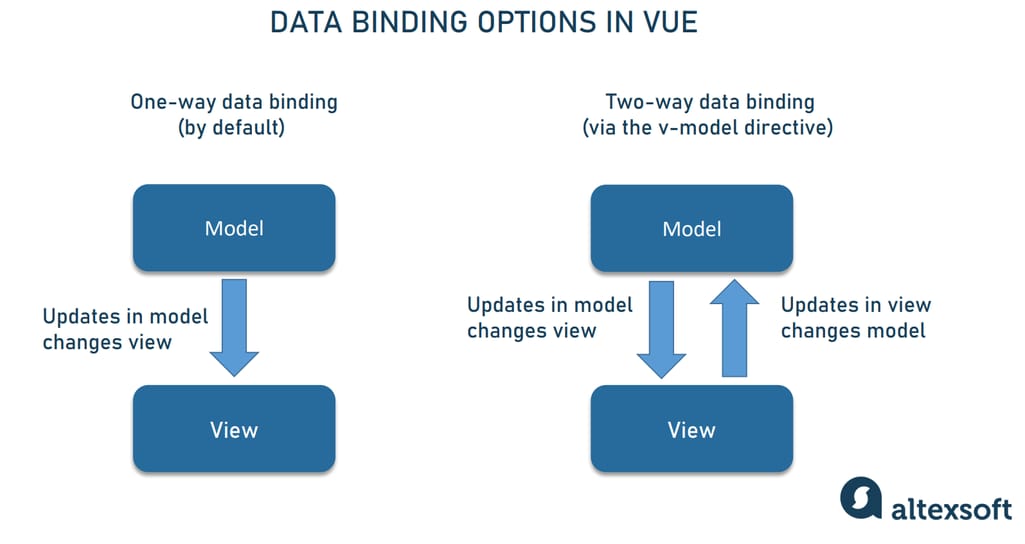
提升用户体验:Vue动态表格数据绑定与渲染技术详解
# 摘要
本文系统性地探讨了Vue框架中动态表格的设计、实现原理以及性能优化。首先,介绍Vue动态表格的基础概念和实现机制,包括数据绑定的原理与技巧,响应式原理以及双向数据绑定的实践。其次,深入分析了Vue动态表格的渲染技术,涉及渲染函数、虚拟DOM、列表和条件渲染的高级技巧,以及自定义指令的扩展应用。接着,本文着重探讨了Vue动态表格的性能优化方法和
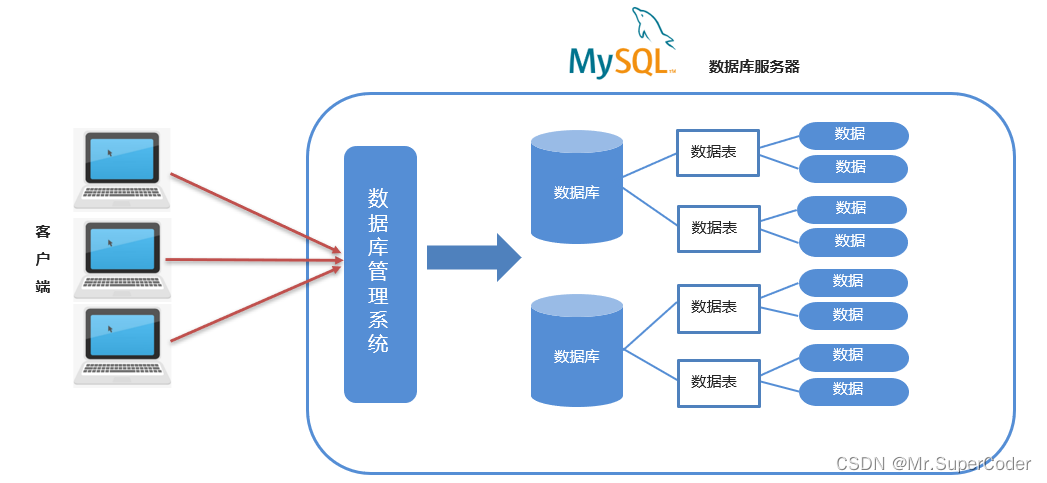
MySQL性能调优实战:20个技巧助你从索引到查询全面提升性能
# 摘要
MySQL作为广泛使用的数据库管理系统,其性能调优对保持系统稳定运行至关重要。本文综述了MySQL性能调优的各个方面,从索引优化深入探讨了基础知识点,提供了创建与维护高效索引的策略,并通过案例展示了索引优化的实际效果。查询语句调优技巧章节深入分析了性能问题,并探讨了实践中的优化方法和案例研究。系统配置与硬件优化章节讨论了服务器参数调优与硬件资源的影响,以及高可用架构对性能的提升。综合性能调优实战章节强调了优化前的准备工作、综
【光模块发射电路效率与稳定性双提升】:全面优化策略

# 摘要
本文针对光模块发射电路进行了深入研究,概述了其基本工作原理及效率提升的策略。文章首先探讨了光发射过程的物理机制和影响电路效率的因素,随后提出了一系列提升效率的方法,包括材料选择、电路设计创新和功率管理策略改进。在稳定性提升方面,分析了评价指标、关键影响因素,并探索了硬件和软件层面的技术措施。此外,
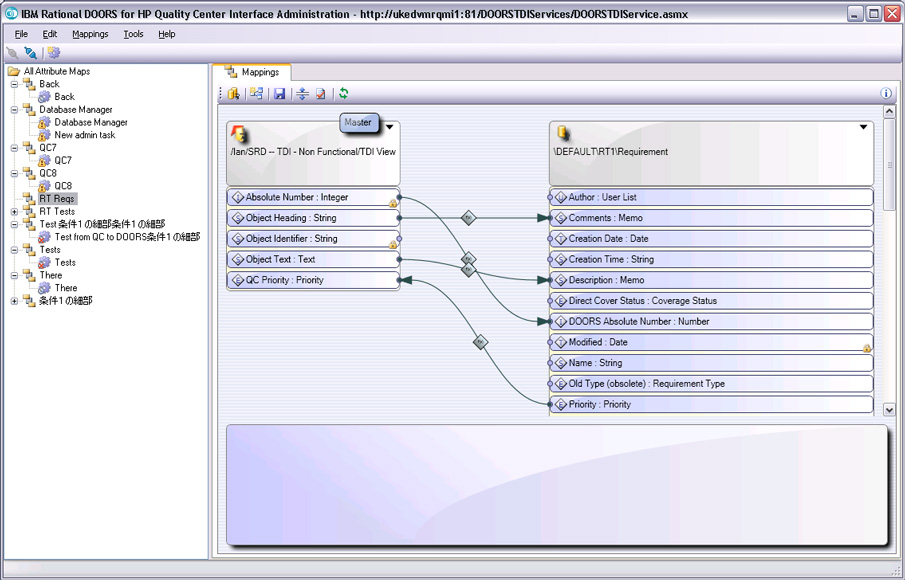
IBM Rational DOORS最佳实践秘籍:提升需求管理的10大策略
# 摘要
本文旨在全面介绍IBM Rational DOORS软件在需求管理领域中的应用及其核心价值。首先概述了需求管理的理论基础,包括关键概念、管理流程以及质量评估方法。接着,文章深入解析了DOORS工具的基本操作、高级特性和配置管理策略。实战演练章节通过具体的案例和技巧,指导读者如何在敏捷环境中管理和自动化需求过程,以及如何优化组织内部的需求管理。最后,
数据标准化的力量:提升国际贸易效率的关键步骤
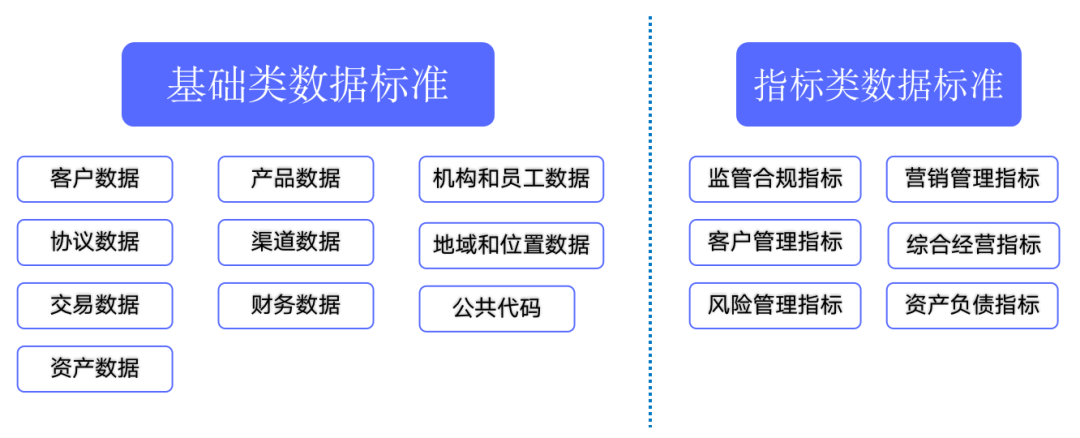
# 摘要
数据标准化是国际贸易领域提高效率和准确性的关键。本文首先介绍了数据标准化的基本概念,并阐述了其在国际贸易中的重要性,包括提升数据交换效率、促进贸易流程自动化以及增强国际市场的互联互通。随后,文章通过案例分析了国际贸易数据标准化的实践,并探讨了数据模型与结构
InnoDB故障恢复高级教程:多表空间恢复与大型数据库案例研究

# 摘要
InnoDB存储引擎在数据库管理中扮演着重要角色,其故障恢复技术对于保证数据完整性与业务连续性至关重要。本文首先概述了InnoDB存储引擎的基本架构及其故障恢复机制,接着深入分析了故障类型与诊断方法,并探讨了单表空间与多表空间的恢复技术。此外,本文还提供了实践案例分析,以及故障预防和性能调优的有效策略。通过对InnoDB故障恢复的全面审视,本文旨在为数据
系统速度提升秘诀:XJC-CF3600-F性能优化实战技巧
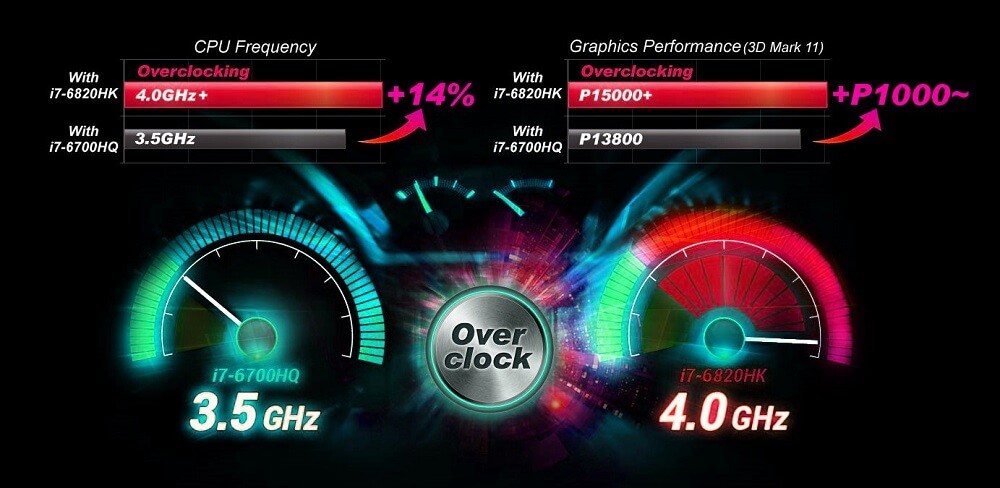
# 摘要
本文对XJC-CF3600-F性能优化进行了全面的概述,并详细探讨了硬件升级、系统配置调整、应用软件优化、负载均衡与集群技术以及持续监控与自动化优化等多个方面。通过对硬件性能瓶颈的识别、系统参数的优化调整、应用软件的性能分析与调优、集群技术的运用和性能数据的实时监控,本文旨在为读者提供一套系统性、实用性的性能优化方案。文章还涉及了自动化优化工具的使用和性能优
【SIM卡无法识别系统兼容性】:深度解析与专业解决方案
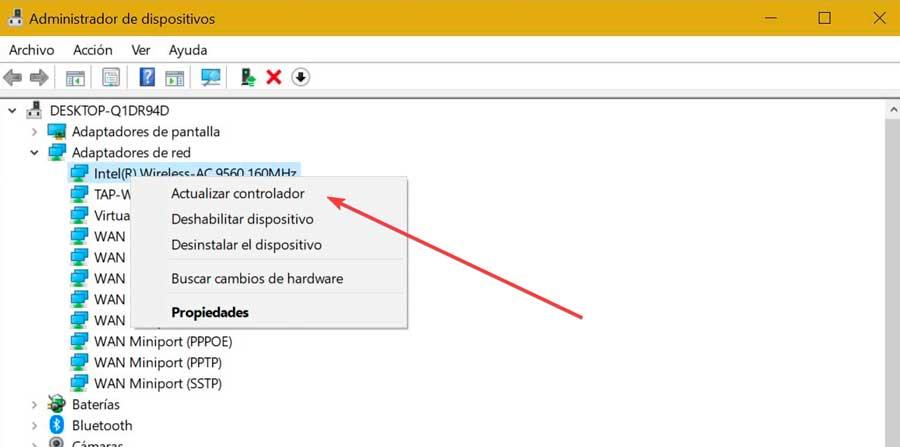
# 摘要
本文针对SIM卡无法识别的现象进行研究,分析其背景、影响及技术与系统兼容性。文章首先概述SIM卡技术,并强调系统兼容性在SIM卡识别中的作用。之后,通过理论框架对常见问题进行了剖析,进而讨论了故障诊断方法和系统日志的应用。针对兼容性问题,提供了实际的解决方案,包括软件更新、硬件维护及综合策略。最后,展望了SIM卡技术的发展前景,以及标准化和创新技
Kafka监控与告警必备:关键指标监控与故障排查的5大技巧
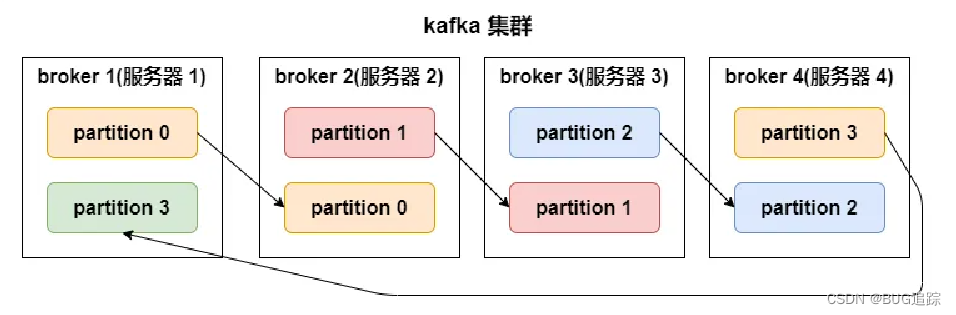
# 摘要
本文综述了Kafka监控与告警的关键要素和实用技巧,重点介绍了Kafka的关键性能指标、故障排查方法以及监控和告警系统的构建与优化。通过详细解析消息吞吐量、延迟、分区与副本状态、磁盘空间和I/O性能等关键指标,本文揭示了如何通过监控这些指标来评估Kafka集群的健康状况。同时,文中还探讨了常见的故障模式,提供了使用日志进行问题诊断的技巧,并介绍了多种故障排查工具和自动化脚本的应用。为了应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )