unordered_map and Algorithm Complexity Analysis: Search, Insertion, Deletion
发布时间: 2024-09-15 18:31:58 阅读量: 36 订阅数: 32 

C++11 unordered_map与map(插入,遍历,Find)效率对比。
# 1. Introduction
In software development, associative containers are a vital data structure used to store key-value pairs. Associative containers provide fast searching, insertion, and deletion capabilities and are one of the commonly used tools in programming. When using associative containers, it's important to understand the different types and characteristics of these containers to choose the appropriate one to solve a given problem.
During operations with associative containers, we need to consider the algorithm's complexity, including time complexity and space complexity. These complexity indicators can help us evaluate the efficiency of the algorithm and resource consumption, thereby choosing the right algorithm to enhance the performance of the program.
By studying associative containers and algorithm complexity, we can better understand the relationship between data structures and algorithms, laying a solid foundation for future programming work.
# 2. Introduction to unordered_map
#### 2.1 Overview of unordered_map
In C++'s Standard Template Library (STL), the `unordered_map` is an associative container implemented with a hash table, ***pared to `map`, `unordered_map` has an advantage in terms of average time complexity for insertion, searching, and deletion operations.
##### 2.1.1 Characteristics of unordered_map
- Unordered: Elements are stored in an unordered manner and are not sorted based on the key's value.
- Fast Search: Implemented using a hash table, the average time complexity for searching, inserting, and deleting operations is O(1).
- Support for Custom Hash Functions: Custom hash functions can be defined to improve performance based on specific requirements.
##### 2.1.2 Differences from map
- Ordering: `map` is an ordered associative container that sorts elements from the smallest to the largest key, whereas `unordered_map` does not.
- Implementation: `map` is typically implemented using a red-black tree, while `unordered_map` is based on a hash table.
#### 2.2 Using unordered_map
`unordered_map` provides a simple API for inserting, deleting, and searching for elements.
##### 2.2.1 Inserting Elements
The `insert` function can be used to insert key-value pairs into `unordered_map`. If the key already exists, insertion fails.
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> umap;
// Insert key-value pairs
umap.insert({"apple", 3});
umap["banana"] = 5;
return 0;
}
```
##### 2.2.2 Deleting Elements
The `erase` function can delete elements based on their key.
```cpp
// Delete the element with the key "apple"
umap.erase("apple");
```
##### 2.2.3 Searching for Elements
The `find` function can be used to search for a specific key.
```cpp
// Search for the element with the key "banana"
auto it = umap.find("banana");
if (it != umap.end()) {
std::cout << "Value of banana: " << it->second << std::endl;
}
```
From these operations, we can see that the usage of `unordered_map` is straightforward and efficient. It can be flexibly applied based on specific needs.
# 3. Underlying Implementation of unordered_map
- 3.1 Principles of unordered_map
- 3.1.1 Concept of Hash Tables
A hash table is a data structure that maps keys to positions in a table using a hash function, enabling fast insertions, deletions, and searches. The basic components of a hash table include an array and a hash function.
- 3.1.2 Importance of Hash Functions
The hash function is crucial for the performance of a hash table, as a good hash functi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
专家揭秘:AD域控制器升级中的ADPrep失败原因及应对策略
# 摘要
本文综合探讨了AD域控制器与ADPrep工具的相关概念、原理、常见失败原因及预防策略。首先介绍了AD域控制器与ADPrep的基本概念和工作原理,重点分析了功能级别的重要性以及ADPrep命令的执行过程。然后详细探讨了ADPrep失败的常见原因,包括系统权限、数据库架构以及网络配置问题,并提供了相应解决方案和最佳实践。接着,本文提出了一套预防ADPrep失败的策略,包括准备阶段的检查清单、执行过程中的监控技巧以
实战技巧大揭秘:如何运用zlib进行高效数据压缩
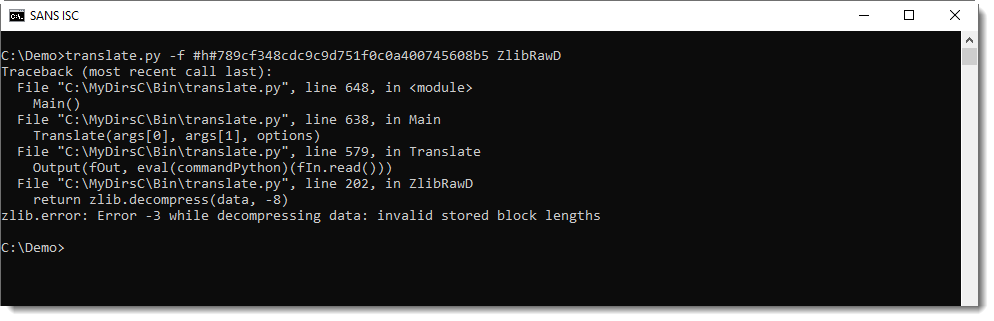
# 摘要
zlib作为一种广泛使用的压缩库,对于数据压缩和存储有着重要的作用。本文首先介绍zlib的概述和安装指南,然后深入探讨其核心压缩机制,包括数据压缩基础理论、技术实现以及内存管理和错误处理。接着,文章分析了zlib在不同平台的应用实践,强调了跨平台压缩应用构建的关键点。进一步,本文分享了实现高效数据压缩的进阶技巧,包括压缩比和速度的权衡,多线程与并行压缩技术,以及特殊数据类型的压缩处理。文章还结合具体应用案例
【打造跨平台桌面应用】:electron-builder与electron-updater使用秘籍

# 摘要
随着桌面应用开发逐渐趋向于跨平台,开发者面临诸多挑战,如统一代码基础、保持应用性能、以及简化部署流程。本文深入探讨了使用Electron框架进行跨平台桌面应用开发的各个方面,从基础原理到应
【张量分析,控制系统设计的关键】
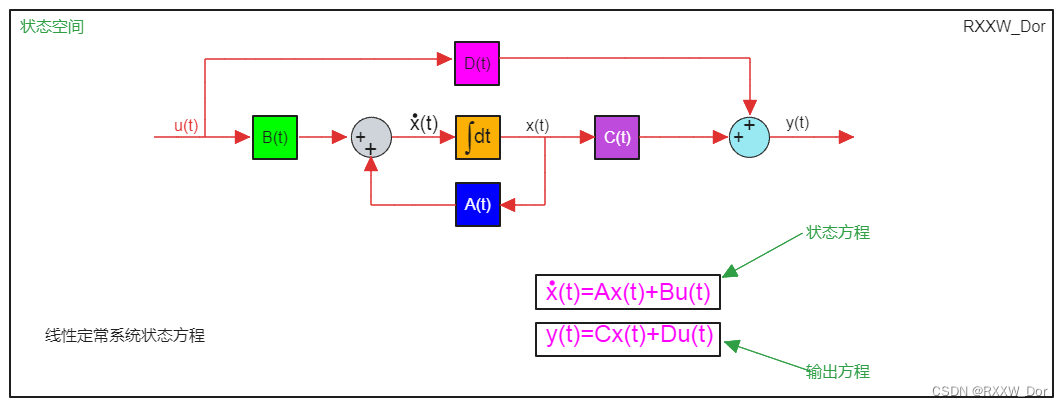
# 摘要
本文旨在探讨张量分析在控制系统设计中的理论与实践应用,涵盖了控制系统基础理论、优化方法、实践操作、先进技术和案例研究等关键方面。首先介绍了控制系统的基本概念和稳定性分析,随后深入探讨了张量的数学模型在控制理论中的作用,以及张量代数在优化控制策略中的应用。通过结合张量分析与机器学习,以及多维数据处理技术,本文揭示了张量在现代控制系统设计中的前沿应用和发展趋势。最后,本文通过具体案例分析,展示了张量分析在工业过程控制
SM2258XT固件调试技巧:开发效率提升的8大策略
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/D/U/aM2BiuQrOyBQqNgbnPBA/2012-08-20-presente-em-todos-os-eletronicos
步进电机故障诊断与解决速成:常见问题快速定位与处理

# 摘要
步进电机在自动化控制领域应用广泛,其性能的稳定性和准确性对于整个系统至关重要。本文旨在为工程师和维护人员提供一套系统性的步进电机故障诊断和维护的理论与实践方法。首先介绍了步进电机故障诊断的基础知识,随后详细探讨了常见故障类型及其原因分析,并提供快速诊断技巧。文中还涉及了故障诊断工具与设备的使用,以及电机绕组和电路故障的理论分析。此外,文章强调了预防措
【校园小商品交易系统中的数据冗余问题】:分析与解决
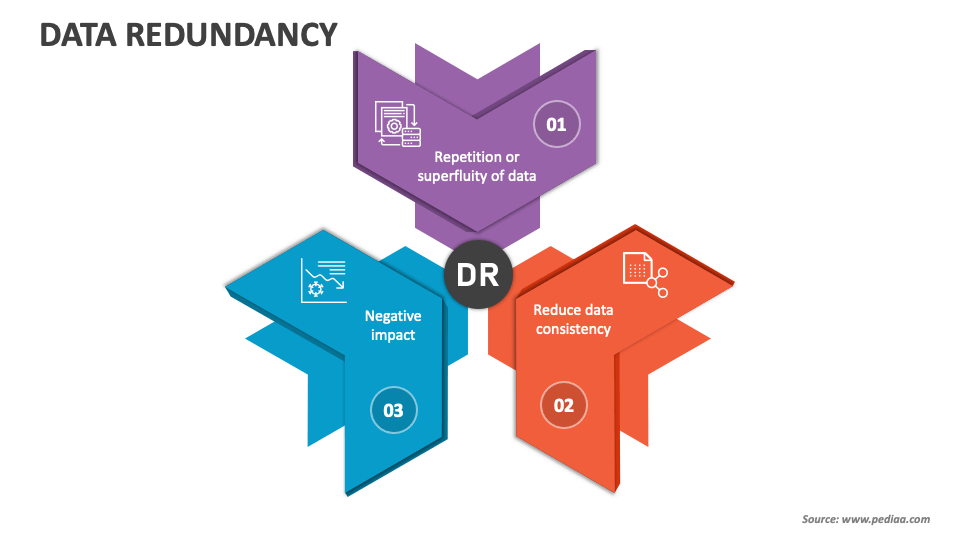
# 摘要
数据冗余问题是影响数据存储系统效率和一致性的重要因素。本文首先概述了数据冗余的概念和分类,然后分析了产生数据冗余的原因,包括设计不当、应用程序逻辑以及硬件和网络问题,并探讨了数据冗余对数据一致性、存储空间和查询效率的负面影响。通过校园小
C#事件驱动编程:新手速成秘籍,立即上手

# 摘要
事件驱动编程是一种重要的软件设计范式,它提高了程序的响应性和模块化。本文首先介绍了事件驱动编程的基础知识,深入探讨了C
SCADA系统通信协议全攻略:从Modbus到OPC UA的高效选择

# 摘要
本文对SCADA系统中广泛使用的通信协议进行综述,重点解析Modbus协议和OPC UA协议的架构、实现及应用。文中分析了Modbus的历史、数据格式、帧结构以及RTU和ASCII模式,并通过不同平台实现的比较与安全性分析,详细探讨了Modbus在电力系统和工业自动化中的应用案例。同时,OPC UA协议的基本概念、信息模型、地址空间、安全通信机制以及会话和
USACO动态规划题目详解:从基础到进阶的快速学习路径
# 摘要
动态规划是一种重要的算法思想,广泛应用于解决具有重叠子问题和最优子结构特性的问题。本论文首先介绍动态规划的理论基础,然后深入探讨经典算法的实现,如线性动态规划、背包问题以及状态压缩动态规划。在实践应用章节,本文分析了动态规划在USACO(美国计算机奥林匹克竞赛)题目中的应用,并探讨了与其他算法如图算法和二分查找的结合使用。此外,论文还提供了动态规划的优化技巧,包括空间和时间
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )