In-depth Explanation of Initialization and Assignment Methods for unordered_map
发布时间: 2024-09-15 18:16:50 阅读量: 26 订阅数: 33 
# 1. Introduction to unordered_map
The `unordered_map` is an associative container in the C++ Standard Template Library (STL) that internally uses a hash table, ensuring that the time complexity for inserting, deleting, and finding elements is O(1). It provides the ability for rapid lookups, making it more efficient than a regular `map` when searching for elements.
The `unordered_map` supports fast insertions and deletions and offers higher efficiency in finding elements because it uses a hash table internally, allowing for direct access to the position of the corresponding element via a hash function. When quick element lookup is needed without the requirement for ordered arrangement, `unordered_map` is an excellent choice.
The template declaration for `unordered_map` is `std::unordered_map<key_type, value_type>`, where `key_type` is the type of the key and `value_type` is the type of the value. Through key-value pair storage, it enables convenient and quick retrieval of values.
# 2. Initializing an unordered_map
The `unordered_map` is an associative container within the C++ STL that employs a hash table to facilitate rapid insertion, deletion, and lookup operations. Before using an `unordered_map`, it must be initialized. This chapter will introduce three methods for initializing an `unordered_map` and will demonstrate the use of each method with specific examples.
#### 2.1 Initializing an unordered_map with curly braces
Initializing an `unordered_map` with curly braces is a straightforward and convenient approach that allows for initialization by directly specifying key-value pairs. The example code is as follows:
```cpp
// Initializing an empty unordered_map
unordered_map<int, string> my_map1;
// Initializing an unordered_map with key-value pairs
unordered_map<int, string> my_map2 = {{1, "apple"}, {2, "banana"}, {3, "orange"}};
```
#### 2.2 Initializing an unordered_map with make_pair
We can also utilize the `make_pair` function to create key-value pairs, which are then inserted into the `unordered_map` for initialization. The example code is as follows:
```cpp
// Initializing an empty unordered_map
unordered_map<int, string> my_map3;
// Inserting key-value pairs for initialization
my_map3.insert(make_pair(1, "apple"));
my_map3.insert(make_pair(2, "banana"));
my_map3.insert(make_pair(3, "orange"));
```
#### 2.3 Initializing an unordered_map with the insert method
In addition to directly inserting key-value pairs with `make_pair`, we can also use the `insert` method to add elements to the `unordered_map`. The example code is as follows:
```cpp
// Initializing an empty unordered_map
unordered_map<int, string> my_map4;
// Initializing with the insert method
my_map4.insert(pair<int, string>(1, "apple"));
my_map4.insert(pair<int, string>(2, "banana"));
my_map4.insert(pair<int, string>(3, "orange"));
```
With these methods, we can flexibly initialize an `unordered_map` and choose the most suitable initialization approach based on our needs.
# 3. Insertion and Access Operations of unordered_map
#### 3.1 Inserting key-value pairs into an unordered_map
When inserting key-value pairs into an `unordered_map`, you can use the `insert` function or the subscript operator `[]`. To use the `insert` function, you need to pass a `pair` type key-value pair as a parameter. When using the subscript operator directly, if the specified key does not exist, a new key-value pair will be automatically created.
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> umap;
// Inserting key-value pairs with the insert function
umap.insert(std::make_pair("apple", 10));
// Inserting key-value pairs with the subscript operator
umap["banana"] = 20;
return 0;
}
```
#### 3.2 Modifying values in an unordered_map
To modify the value associated with an existing key in an `unordered_map`, you can directly use the subscript operator `[]` or the `insert_or_assign` function. Using the subscript operator directly, if the key does not exist, an insertion operation will be performed before modifying the value; the `insert_or_assign` function, however, can directly modify the value associated with an existing key.
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> umap = {{"apple", 10}, {"banana", 20}};
// Modifying a value
umap["banana"] = 30;
// Using insert_or_assign
umap.insert_or_assign("apple", 15);
return 0;
}
```
#### 3.3 Finding elements in an unordered_map
To find elements in an `unordered_map`, you can use the `find` function. If the specified key is found, it returns an iterator pointing to the key-value pair; if not found, it returns `end()`. Additionally, the `count` function can determine if a key exists, returning 1 if the key exists and 0 if it does not.
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> umap = {{"apple", 10}, {"banana", 20}};
// Finding an element
auto it = umap.find("apple");
if (it != umap.end()) {
std::cout << "Found: " << it->second << std::endl;
} else {
std::cout << "Not found" << std::endl;
}
// Checking if a key exists
if (umap.count("banana")) {
std::cout << "Key exists" << std::endl;
} else {
std::cout << "Key does not exist" << std::endl;
}
return 0;
}
```
# 4. Traversing and Deleting Elements in an unordered_map
The `unordered_map` offers various methods for traversing and deleting elements, let's learn how to perform these operations one by one.
#### 4.1 Traversing all elements in an unordered_map
In C++, we can use iterators or range-based for loops to traverse all elements in an `unordered_map`.
##### 4.1.1 Using iterators for traversal
By using iterators to traverse an `unordered_map`, we can access each key-value pair and perform corresponding operations. Here is an example code:
```cpp
unordered_map<string, int> myMap = {{"apple", 5}, {"banana", 3}, {"cherry", 8}};
// Using iterators for traversal
for(auto it = myMap.begin(); it != myMap.end(); ++it) {
cout << "Key: " << it->first << ", Value: " << it->second << endl;
}
```
##### 4.1.2 Using range-based for loop for traversal
The range-based for loop (range-for loop) provides a more concise way to traverse an `unordered_map`:
```cpp
for(const auto& pair : myMap) {
cout << "Key: " << pair.first << ", Value: " << pair.second << endl;
}
```
#### 4.2 Deleting elements in an unordered_map
In an `unordered_map`, we can delete individual elements or clear the entire container.
##### 4.2.1 Deleting a single element
To delete a single element, use the `erase()` method, specifying the key value to delete the targeted element. The example is as follows:
```cpp
// Deleting the element with the key "banana"
myMap.erase("banana");
```
##### 4.2.2 Clearing an unordered_map
To clear the entire `unordered_map`, use the `clear()` method:
```cpp
myMap.clear();
```
With these methods, we can conveniently traverse and delete elements from an `unordered_map`, applying them flexibly in practical development.
# 5. Summary and Extensions
The `unordered_map` is an associative container provided by the C++ STL, characterized by its fast lookup, insertion, and deletion operations. This section will compare `unordered_map` with `map`, introduce additional methods for operating with `unordered_map`, and analyze its use cases.
#### 5.1 Comparison between unordered_map and map
When choosing containers from the STL's associative containers, it is often necessary to select the appropriate type based on the specific scenario. Both `unordered_map` and `map` can store key-value pairs and perform fast lookups, but their internal implementations differ.
| Feature | unordered_map | map |
|-------------------|----------------------------------|----------------------------------|
| Internal Implementation | Hash Table | Red-Black Tree |
| Lookup Efficiency | Average O(1), Worst O(n) | O(log n) |
| Orderliness | Unordered | Ordered |
| Memory Usage | Uses More Memory Space | Uses Less Memory Space |
| Suitable Scenarios| Frequent lookups, No need for ordered output | Requires ordered traversal or output, or limited memory space |
In practical applications, if the ordering of elements is not a significant concern and fast lookups and insertions are required, `unordered_map` is the preferred choice. On the other hand, if ordered traversal or output by key size is needed, or memory space is limited, `map` is the better option.
#### 5.2 Introduction to More Operations of unordered_map
In addition to insertion, access, and deletion operations, `unordered_map` also provides some other commonly used methods, such as:
- `count(key)`: Returns the number of elements in the container with the key value as key, typically used to check if an element exists.
- `size()`: Returns the number of elements in the container.
- `bucket_count()`: Returns the number of buckets in the hash table.
- `bucket(key)`: Returns the index of the bucket containing the specific key key.
- `empty()`: Determines whether the container is empty.
Here is a simple example code:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<int, std::string> myMap = {{1, "apple"}, {2, "banana"}, {3, "orange"}};
// Checking if an element exists
if (myMap.count(2) > 0) {
std::cout << "Key 2 exists in the map." << std::endl;
}
// Printing the size of the map and the number of buckets
std::cout << "Size of the map: " << myMap.size() << std::endl;
std::cout << "Number of buckets: " << myMap.bucket_count() << std::endl;
return 0;
}
```
#### 5.3 Analysis of unordered_map Use Cases
Due to its high lookup efficiency, rapid insertion, and deletion operations, `unordered_map` has a wide range of practical use cases, such as:
- Caching systems: Used to store key-value pairs for faster data access.
- String processing: To count the occurrences of characters, and for quick lookup, replace operations.
- Data processing: For indexing data and rapid retrieval of specific elements.
In summary, `unordered_map` is suitable for scenarios requiring rapid lookups and insertions, especially for the storage and management of large volumes of data. When choosing a container type, it is essential to consider the specific requirements comprehensively before deciding on the use of `unordered_map`.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
YXL480扩展性探讨:系统升级与扩展的8大策略
# 摘要
随着信息技术的快速发展,YXL480系统面临着不断增长的性能和容量需求。本文对YXL480的扩展性进行了全面概述,并详细分析了系统升级和扩展策略,包括硬件和软件的升级路径、网络架构的优化、模块化扩展方法、容量规划以及技术债务管理。通过实践案例分析,本文揭示了系统升级与扩展过程中的关键策略与决策,挑战与解决方案,并进行了综合评估与反馈。文章最后对新兴技术
【编译原理核心算法】:掌握消除文法左递归的经典算法(编译原理中的算法秘籍)

# 摘要
编译原理中的文法左递归问题一直是理论与实践中的重要课题。本文首先介绍编译原理与文法左递归的基础知识,随后深入探讨文法左递归的理论基础,包括文法的定义、分类及其对解析的影响。接着,文章详细阐述了消除直接与间接左递归的算法原理与实践应用,并
【S7-1200_S7-1500故障诊断与维护】:最佳实践与案例研究

# 摘要
本文首先对S7-1200/1500 PLC进行了概述,介绍了其基本原理和应用基础。随后,深入探讨了故障诊断的理论基础,包括故障诊断概念、目的、常见故障类型以及诊断方法和工具。文章第三章聚焦于S7-1200/1500 PLC的维护实践,讨论了日常维护流程、硬件维护技巧以及软件维护与更新的策略。第四章通过故障案例研究与分析,阐述了实际故障处理和维护
分析劳动力市场趋势的IT工具:揭秘如何保持竞争优势

# 摘要
在不断变化的经济环境中,劳动力市场的趋势分析对企业和政策制定者来说至关重要。本文探讨了IT工具在收集、分析和报告劳动力市场数据中的应用,并分析了保持竞争优势的IT策略。文章还探讨了未来IT工具的发展方向,包括人工智能与自动化、云计算与大数据技术,以及
搜索引擎核心组成详解:如何通过数据结构优化搜索算法

# 摘要
搜索引擎是信息检索的重要工具,其工作原理涉及复杂的数据结构和算法。本文从搜索引擎的基本概念出发,逐步深入探讨了数据结构基础,包括文本预处理、索引构建、搜索算法中的关键数据结构以及数据压缩技术。随后,文章分析了搜索引擎算法实践应用,讨论了查询处理、实时搜索、个性化优化等关键环节。文章还探讨了搜索引擎高级功能的实现,如自然语言处理和多媒体搜索技术,并分析了大数据环境下搜索引
Edge存储释放秘籍:缓存与历史清理策略

# 摘要
Edge存储是边缘计算中的关键组成部分,其性能优化对于提升整体系统的响应速度和效率至关重要。本文首先介绍了Edge存储的基础概念,包括缓存的作用、优势以及管理策略,探讨了如何在实践中权衡缓存大小
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
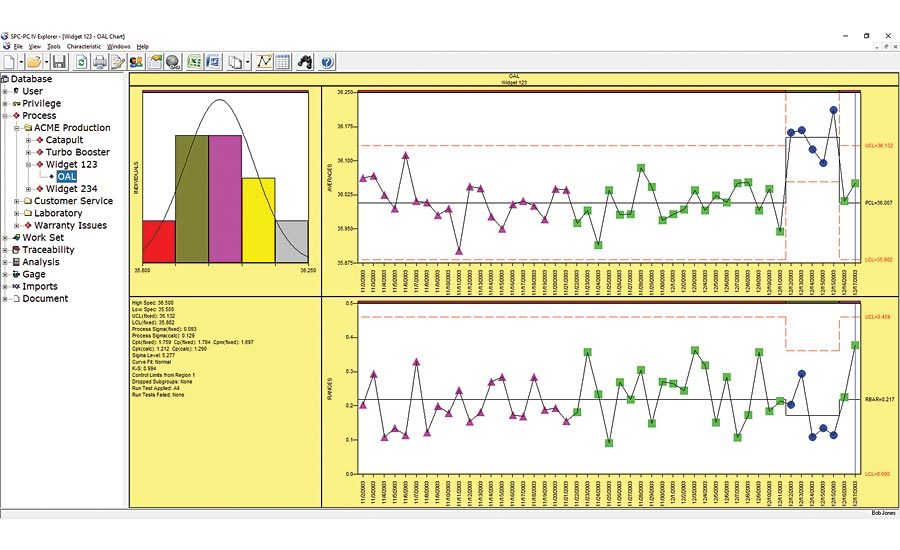
深入SPC世界:注塑成型质量保证与风险评估的终极指南
# 摘要
本文综合探讨了注塑成型技术中统计过程控制(SPC)的应用、风险管理以及质量保证实践。首先介绍了SPC的基础知识及其在注塑成型质量控制中的核心原理和工具。接着,文章详述了风险管理流程,包括风险识别、评估和控制策略,并强调了SPC在其中的应用
IT服务连续性管理策略:遵循ISO20000-1:2018的实用指南
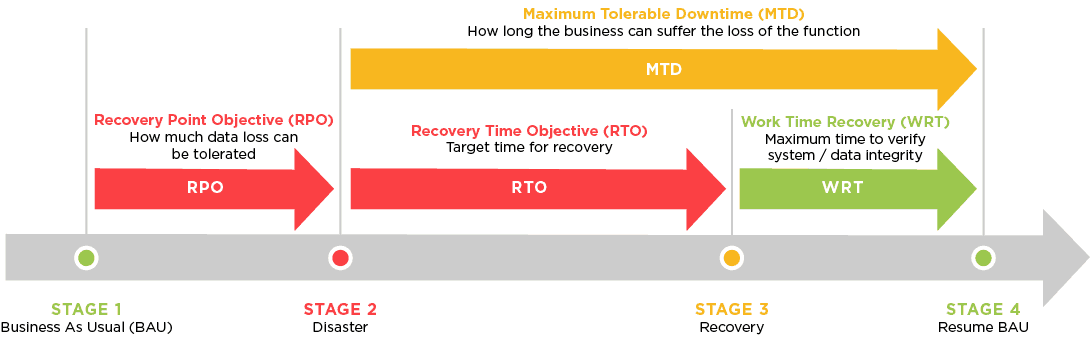
# 摘要
本文详细探讨了IT服务连续性管理,并对ISO20000-1:2018标准进行了深入解读。通过分析服务连续性管理的核心组成部分、关键概念和实施步骤,本文旨在为读者构建一个全面的管理体系。同时,文章强调了风险评估与管理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )