Exploring Custom Hash Function Methods for unordered_map
发布时间: 2024-09-15 18:22:12 阅读量: 28 订阅数: 26 
# 1. **Introduction to Hash Functions in unordered_map**
## 1.1 Basic Concepts of Hash Functions
A hash function is a type of function that converts input data into a fixed-length value. Its purpose is to quickly map data to a fixed-size value domain for efficient data retrieval and storage.
In the process of using hash functions, it is important to select an appropriate hash algorithm to ensure even data distribution and reduce the probability of conflicts.
The hash function is an essential data processing tool that plays a crucial role in the unordered_map. With the help of hash functions, the location of data in the unordered_map can be quickly determined, enhancing the efficiency of search, insertion, and deletion operations.
In subsequent sections, we will delve into the default design of hash functions in unordered_map, as well as the necessity and methods of exploring custom hash functions.
# 2. **Default Design of Hash Functions in unordered_map**
### 2.1 Default Implementation of Hash Functions in unordered_map
The unordered_map container is an associative container provided by the C++ standard library, implemented using a hash table, which allows for rapid lookup of key-value pairs. In the unordered_map, the hash function plays a critical role as it determines the storage location of elements in the hash table.
#### 2.1.1 Usage of Hash Functions in unordered_map
The unordered_map uses a hash function to convert keys into their corresponding hash values, and then decides where elements should be placed in the hash table based on these values. The C++ standard library-provided unordered_map default uses std::hash as its hash function.
#### 2.1.2 Problems Caused by Default Hash Functions
However, the default hash function may not adapt well to all types of keys. When the type of keys is a custom structure or class object, the default hash function may not provide sufficient performance.
### 2.2 Performance Analysis of the Default Hash Function in unordered_map
While the default hash function usually works well in most cases, it may cause performance degradation or increased hash collisions in specific scenarios, affecting the efficiency of access to unordered_map.
#### 2.2.1 Impact of Default Hash Functions on unordered_map Performance
The default hash function may lead to an increase in hash collisions, making the linked lists within the buckets of the hash table too long, thus impacting the efficiency of the search. In extreme cases, the time complexity for querying, insertion, and deletion operations in unordered_map can rise from O(1) to O(n).
#### 2.2.2 How to Evaluate the Performance of Hash Functions
Evaluating the performance of hash functions can be done by examining the probability of hash collisions, average query time, and load factor. Through practical testing and performance analysis, it can be determined if the current hash function meets the requirements or if a custom hash function design is necessary.
# 3. **Necessity of Customizing Hash Functions for unordered_map**
### 3.1 Why Do We Need Custom Hash Functions?
The hash function plays a crucial role in the unordered_map, and for specific data structures and business needs, custom hash functions can greatly enhance the performance of hash tables

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【集群故障不再怕】:使用ClusterEngine浪潮平台进行高效监控与诊断
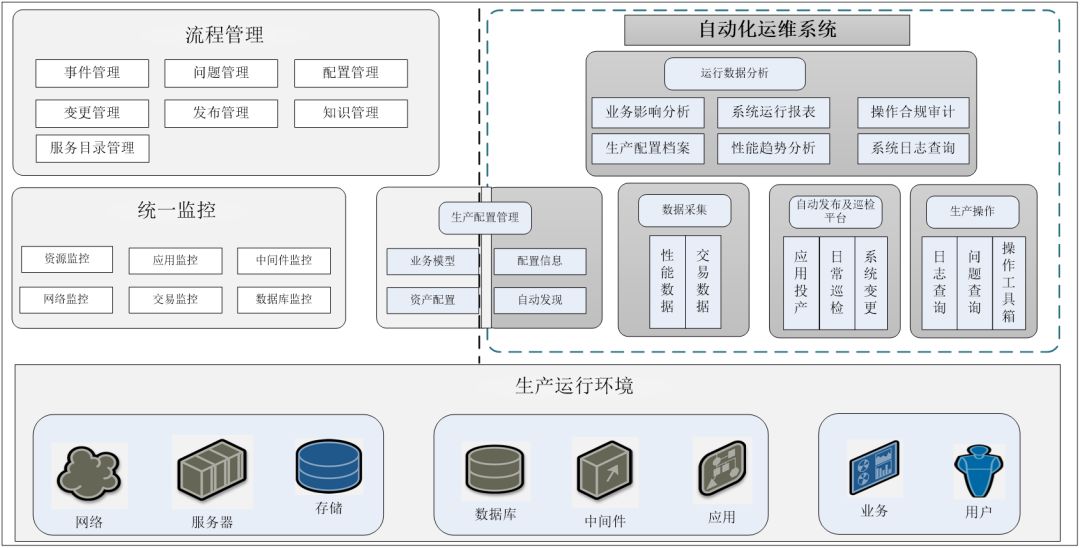
# 摘要
本文重点介绍了集群监控与诊断在现代IT运维管理中的重要性,并详细解读了ClusterEngine浪潮平台的基础架构、设计理念及其关键功能组件。文章阐述了如何安装和配置ClusterEngine,以实现集群资源的高效注册与管理,并深入探讨了用户界面设计,确保了管理的便捷性。在监控实践章节,本文通过节点监控、服务监控以及性能分析,提供了全面的资源监控实践案例。针对集群故障,本文提出了一套高效的诊断流程,并
动态表头渲染:Vue中的优雅解决方案揭秘

# 摘要
本文深入探讨了Vue框架中动态表头渲染的技术与实践。首先,文章奠定了动态表头渲染的理论基础,介绍了实现该技术的基础组件、插槽和渲染函数的高级运用。随后,通过场景实战部分,展示了如何在Vue应用中实现表头的自定义、动态更新及响应式数据变化。进阶应用章节进一步分析了性能优化、懒加载以及可
MySQL高级特性全解析:存储过程和触发器的精进之路

# 摘要
本文系统地介绍了MySQL存储过程与触发器的基础知识、高级应用和最佳实践。首先概述了存储过程与触发器的概念、定义、优势及创建语法。接着深入探讨了存储过程的参数、变量、控制结构及优化技巧,以及触发器的类型、编写、触发时机和实战应用。文章还包含了存储过程与触发器的案例分析,涵盖数据处理、业务逻辑实现和性能优化。此外,文中探讨了存储过程与触发器的故障排查
IBM Rational DOORS深度剖析:5大技巧打造高效需求管理流程
# 摘要
IBM Rational DOORS作为一种先进的需求管理工具,在软件和系统工程领域发挥着至关重要的作用。本文首先介绍了IBM Rational DOORS的基本概念和需求管理的理论基础,随后深入探讨了其核心功能在需求捕获、管理和验证方面的具体实践。文章还分享了打造高效需
InnoDB数据恢复高级技巧:表空间与数据文件的全面分析

# 摘要
本文对InnoDB存储引擎的数据恢复进行了全面的探讨,涵盖了从基本架构到恢复技术的各个方面。首先介绍了InnoDB的基本架构和逻辑结构,重点分析了数据文件和表空间的特性,事务与锁定机制的实现。随后深入分析了数据文件的内部结构,表空间文件操作以及页故障的检测和修复策略。接着详细阐述了物理恢复和逻辑恢复的技术原理和实践方法
【确保光模块性能,关键在于测试与验证】:实战技巧大公开
# 摘要
光模块作为光通信系统的核心组件,其性能直接影响整个网络的质量。本文全面介绍了光模块性能测试的基础理论、测试设备与工具的选择与校准、性能参数测试实践、故障诊断与验证技巧,以及测试案例分析和优化建议。通过对光模块测试流程的深入探讨,本文旨在提高光模块测试的准确性与效率,确保光通信系统的可靠性和稳定性。文章综合分析了多种测试方法和工具,并提供了案例分析以及应对策略,为光模块测试提供了完整的解决方案。同时
XJC-CF3600-F故障诊断速成:专家级问题排查与解决攻略
# 摘要
本文针对XJC-CF3600-F的故障诊断进行了全面概述,从理论基础到实际操作,详细探讨了其工作原理、故障分类、诊断流程,以及专用诊断软件和常规诊断工具的应用。在实践中,针对硬件故障、软件问题以及网络故障的排查方法和解决策略进行了分析。同时,文章还强调了定期维护、故障预防措施和应急预案的重要性,并通过案例研究分享了故障排查的经验。本文旨在为技术人员提供实用的故障诊断知识和维护策略,帮助他们提升故障排除能力,优化设备性能,确保系统的稳定运行。
# 关键字
故障诊断;XJC-CF3600-F;诊断流程;维护策略;硬件故障;软件问题
参考资源链接:[XJC-CF3600-F操作手册:功
【SIM卡无法识别?】:更新系统驱动快速解决

# 摘要
本文系统性地探讨了SIM卡识别问题及其解决方案,重点分析了系统驱动的基本知识和SIM卡驱动的重要作用。文章详细阐述了更新SIM卡驱动的理论基础和实践操作步骤,同时讨论了更新后驱动的调试与优化流程。此外,本文还提供了一系列预防措施和最佳维护实践,以帮助用户安全、有效地管理SIM卡驱动更新,确保设备的稳定运行和安全性。最后,本文强调了
Kafka与微服务完美结合:无缝集成的5个关键步骤
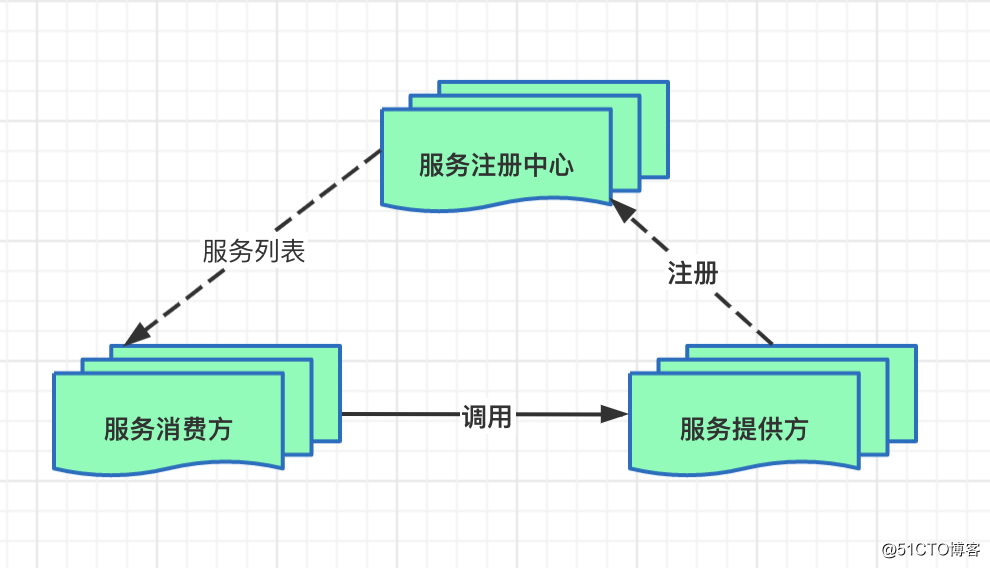
# 摘要
随着微服务架构在企业中的广泛应用,集成高效的消息队列系统如Kafka对于现代分布式系统的设计变得至关重要。本文详细探讨了Kafka与微服务的集成基础、高级特性及实践步骤,并分析了集成过程中的常见问题与解决方案,以及集成后的性能优化与监控。文章旨在为读者提供一个系统的指南,帮助他们理解和实现Kafka与微服务的深度融合,同时提供了优化策略和监控工具来提高系统的可靠性和性能。
# 关键字
Kafka;微服务架构;
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )