Analysis of Differences and Usage Scenarios Between unordered_map and map
发布时间: 2024-09-15 18:15:53 阅读量: 41 订阅数: 33 

Analysis of the Differences between English and Chinese Language Structure.pdf
# 1. Understanding the Concept of Containers in STL
STL, which stands for Standard Template Library, is a significant component of the C++ programming language. Within STL, a container is a data structure designed to hold data, capable of storing various types of data and embodying principles of object-oriented programming such as encapsulation, inheritance, and polymorphism. Containers can be categorized into different types based on their internal mechanisms and functionalities, including sequential and associative containers. The vector is a commonly used sequential container in STL with the characteristics of a dynamic array, whereas the list is a doubly linked list structure, suitable for frequent insertions and deletions. By studying the various types of containers in STL, developers can handle a wide array of data structures and algorithmic problems more efficiently, enhancing the maintainability and readability of their code.
# 2. The Principle and Usage of map
### 2.1 The Underlying Mechanism of map
#### 2.1.1 Introduction to Red-Black Trees
Before delving into the mechanics of map, let's first understand the concept of red-black trees. A red-black tree is a self-balancing binary search tree that tags each node with a color attribute, which can be either red or black. Certain rules are applied to maintain this color balance, ensuring the depth of the tree remains optimal. Consequently, operations such as insertion, deletion, and search all have a time complexity of O(log n).
#### 2.1.2 The Implementation Principle of map
The map is an associative container based on the red-black tree. It stores key-value pairs in the tree, maintaining a certain order. When inserting a new element, the map automatically adjusts the structure of the red-black tree according to the key values, ensuring the tree remains balanced. This allows the map to perform lookups, insertions, and deletions swiftly, while keeping the elements ordered.
### 2.2 Basic Operations of map
#### 2.2.1 Insertion and Deletion Operations
The map provides methods such as insert and erase for element insertion and deletion. When inserting a new element, the map places it in the appropriate position based on the key value and maintains the tree's balance; upon deletion, it readjusts the tree's structure to preserve the balance.
```cpp
#include <iostream>
#include <map>
int main() {
std::map<int, std::string> myMap;
// Insert elements
myMap.insert(std::make_pair(1, "One"));
myMap.insert(std::make_pair(2, "Two"));
// Delete an element
myMap.erase(1);
return 0;
}
```
#### 2.2.2 Search and Modification Operations
The find method of map allows for a quick search for the value corresponding to a specified key. If found, it returns an iterator to that element; otherwise, it returns an iterator pointing to the end. By modifying the value associated with a key, one can perform element modification operations.
```cpp
#include <iostream>
#include <map>
int main() {
std::map<int, std::string> myMap;
// Search for an element
auto it = myMap.find(2);
if (it != myMap.end()) {
std::cout << "Key 2 found, value: " << it->second << std::endl;
}
// Modify an element
myMap[2] = "New Value";
return 0;
}
```
#### 2.2.3 Traversal and Iteration Operations
The map provides iterators for traversing its elements. These iterators can be incremented, decremented, and used to iterate over the elements within the map.
```cpp
#include <iostream>
#include <map>
int main() {
std::map<int, std::string> myMap = {{1, "One"}, {2, "Two"}, {3, "Three"}};
// Traverse elements
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;
}
return 0;
}
```
Through these operations, we can gain a deeper understanding of the map, an associative container based on the red-black tree, grasp its underlying mechanisms, and learn how to perform insertion, deletion, searching, and traversal.
# 3. Internal Implementation and Performance Comparison of unordered_map
### 3.1 The Hash Table Principle of unordered_map
A hash table is a data structure that allows direct access to the memory storage location using a key. The unordered_map is implemented based on hash tables. When inserting and retrieving elements, the unordered_map first computes the hash value of the element using a hash function and then locates the corresponding storage position based on this hash value.
#### 3.1.1 The Role of Hash Functions
A hash function is a technique that converts input data of arbitrary length into a fixed-length output. It maps the element's key to a definite storage position, enabling quick lookups or insertions. A good hash function minimizes collisions and improves the performance of unordered_map.
#### 3.1.2 Methods for Collision Resolution
A collision occurs when different elements, after being processed by a hash function, are mapped to the same storage location. The unordered_map typically uses separate chaining to resolve collisions, which involves storing colliding elements in data structures such as linked lists at the same storage location.
#### 3.1.3 The Resizing Mechanism of Hash Tables
When the number of elements in an unordered_map reaches a certain threshold, to avoid hash collisions and enhance efficiency, the system triggers a hash table resize, which means reallocating larger storage space and recalculating the hash values for all existing elements. This process might incur some performance overhead.
### 3.2 Performance Comparison between unordered_map and map
The unordered_map is based on hash tables, while map uses red-black trees as its underlying data structure. Their performance varies for different operations, and a detailed comparison follows.
#### 3.2.1 Time Complexity Comparison
For insertion, deletion, and search operations, the average time complexity of unordered_map is O(1), whereas for map, it is O(log n). This means that in most cases, unordered_map can complete the related operations faster than map.
#### 3.2.2 Memory Usage Comparison
Due to the implementation of hash tables, the memory footprint of unordered_map is typically larger than that of map. This is because unordered_map needs to maintain the buckets and chains of the hash table, while map only needs to maintain the nodes of the red-black tree.
#### 3.2.3 Selection of Practical Scenarios
unordered_map is suitable for scenarios requiring fast lookups, insertions, and deletions of elements, especially when the order of elements is not a concern. map, on the other hand, is suitable for scenarios involving frequent lookups on ordered data or when insertions and deletions are infrequent. When choosing a container, it's necessary to consider the actual requirements and characteristics to decide which type to use.
The above section provides a detailed introduction to the internal implementation and performance comparison of unordered_map, aiming to help you better understand the characteristics and applicable scenarios of these two types of containers.
# 4. Analysis of Applicable Scenarios for map and unordered_map
### 4.1 Applicable Scenarios for map
#### 4.1.1 Requirement for Ordered Data Storage and Search
When there is a need for ordered storage and search based on element keys, using a map is a wise choice. map is implemented based on red-black trees, ensuring elements are stored in a sorted order by key and providing efficient search operations. For instance, sorting and storing student grades by student ID allows for quick lookups by ID.
#### 4.1.2 Infrequent Insertions and Deletions of Elements
Since the red-black tree structure within a map needs to maintain balance to preserve order, frequent insertion and deletion operations can lead to frequent tree restructurings, which can impact performance. Therefore, when the insertion and deletion of elements are infrequent, and there is more emphasis on order and search efficiency, choosing a map is judicious.
### 4.2 Applicable Scenarios for unordered_map
#### 4.2.1 Need for Fast Lookup, Insertion, and Deletion Operations
unordered_map is implemented based on hash tables, offering fast lookup, insertion, and deletion operations. In scenarios involving frequent insertion, deletion, and search operations, unordered_map outperforms map. For example, when dealing with large data sets, using unordered_map can yield better performance.
#### 4.2.2 No Particular Requirement for Data Storage Order
Unlike map, unordered_map does not require the maintenance of element storage order. It relies on the hash function to compute the hash value of keys for rapid data access. It is suitable for scenarios where the storage order is not important, but efficient search capabilities are necessary.
### Comparison Table: map vs. unordered_map
| Feature | map | unordered_map |
|------------------------|-----------------------------------------|------------------------------------------|
| Internal Implementation | Red-Black Tree | Hash Table |
| Orderliness | Ordered | Unordered |
| Insertion/Deletion Performance | Slower | Faster |
| Search Performance | Faster | Fast |
| Applicable Scenarios | Scenarios requiring ordered storage and search | Scenarios with a focus on efficient insertion and search where storage order is not a concern |
### Decision Flowchart: Choosing Between map and unordered_map
```mermaid
graph LR
A[Determine Requirement Scenario] -->|Ordered Data Storage Requirement| B(map Applicable Scenario)
A -->|Fast Operation Requirement| C(unordered_map Applicable Scenario)
B --> D(Select map)
C --> E(Select unordered_map)
```
The above analysis focuses on applicable scenarios for using map and unordered_map. By selecting the appropriate container type based on the requirements, the advantages of the containers can be better utilized.
# 5. Examples of Using unordered_map and map
In actual software development, we often need to choose the right container to store and manage data based on the specific situation. In this chapter, we will demonstrate the usage methods of unordered_map and map through concrete examples and compare their applicability in different scenarios.
### 5.1 Example: Counting the Occurrence of Words
Suppose we need to count how many times each word appears in a text segment. We can use an unordered_map to accomplish this task. Here is a C++ example code:
```cpp
#include <iostream>
#include <unordered_map>
#include <string>
int main() {
std::string text = "Hello World Hello";
std::unordered_map<std::string, int> wordCount;
std::string word;
for (int i = 0; i < text.size(); ++i) {
if (text[i] == ' ' || i == text.size() - 1) {
if (i == text.size() - 1) {
word.push_back(text[i]);
}
wordCount[word]++;
word = "";
} else {
word.push_back(text[i]);
}
}
for (const auto& pair : wordCount) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
```
In this example, we use an unordered_map to count the occurrences of each word. By iterating over the text and using words as keys and their counts as values, we store them in the unordered_map, and finally, print out the frequency of each word.
### 5.2 Example: Output by Key Sorting
If we need to output key-value pairs from a map in key order, we can use a map to do so. Here is a Python example code:
```python
word_count = {
'Hello': 2,
'World': 1
}
for key in sorted(word_count.keys()):
print(key, ':', word_count[key])
```
In this example, we use a Python map to store words and their occurrences, then sort the map's keys with the sorted function, and output the key-value pairs in the sorted order.
Through these two examples, we can see the flexible application of unordered_map and map in different scenarios, helping us efficiently manage various data-related issues.
### 5.3 Performance Comparison
In the examples above, we can see that unordered_map is suitable for scenarios requiring rapid insertion, search, and deletion, while map is suitable for ordered data storage and output by key sorting. In practical applications, we can choose the appropriate container based on specific requirements to achieve optimal performance and results.
By comparing practical applications and performance tests, we can better understand the applicability of unordered_map and map in different scenarios, providing more choices and inspiration for our software development work.
The above is about the examples of using unordered_map and map and their performance comparison, hoping to help readers better understand and apply these two types of containers. In practical development, choosing the right container based on the requirements is very important. It is hoped that readers can gain insights from the content of this chapter.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ARCGIS分幅图应用案例:探索行业内外的无限可能
# 摘要
ARCGIS分幅图作为地理信息系统(GIS)中的基础工具,对于空间数据的组织和管理起着至关重要的作用。本文首先探讨了ARCGIS分幅图的基本概念及其在地理信息系统中的重要性,然后深入分析了分幅图的理论基础、关键技术以及应用理论。文章详细阐述了分幅图的定义、类型、制作过程、地图投影、坐标系和数据格式转换等问题。在实践操作部分,本文详细介绍了如何使用ARCGIS软件制作分幅图,并
用户体验设计指南:外观与佩戴舒适度的平衡艺术
# 摘要
本论文全面探讨了用户体验设计的关键要素,从外观设计的理论基础和佩戴舒适度的实践方法,到外观与舒适度综合设计的案例研究,最终聚焦于用户体验设计的优化与创新。在外观设计部分,本文强调了视觉感知原理、美学趋势以及设计工具和技术的重要性。随后,论文深入分析了如何通过人体工程学和佩戴测试提升产品的舒适度,并且检验其持久性和耐久性。通过综合设计案例的剖析,论文揭示了设计过程中遇到的挑战与机遇,并展示了成功的
【install4j性能优化秘笈】:提升安装速度与效率的不传之秘

# 摘要
本文全面探讨了install4j安装程序的性能优化,从基础概念到高级技术,涵盖了安装过程的性能瓶颈、优化方法、实践技巧和未来趋势。分析了install4j在安装流程中可能遇到的性能问题,提出了启动速度、资源管理等方面的优化策略,并介绍了代码级与配置级优化技
MBI5253.pdf揭秘:技术细节的权威剖析与实践指南

# 摘要
本文系统地介绍了MBI5253.pdf的技术框架、核心组件以及优化与扩展技术。首先,概述了MBI5253.pdf的技术特点,随后深入解析了其硬件架构、软件架构以及数据管理机制。接着,文章详细探讨了性能调优、系统安全加固和故障诊断处理的实践方法。此外,本文还阐述了集成第三方服务、模块化扩展方案和用户自定义功能实现的策略。最后,通过分析实战应用案例,展示了MBI5253.pdf
【GP代码审查与质量提升】:GP Systems Scripting Language代码审查关键技巧
# 摘要
本文深入探讨了GP代码审查的基础知识、理论框架、实战技巧以及提升策略。通过强调GP代码审查的重要性,本文阐述了审查目标、常见误区,并提出了最佳实践。同时,分析了代码质量的度量标准,探讨了代码复杂度、可读性评估以及代码异味的处理方法。文章还介绍了静态分析工具的应用,动态
揭秘自动化控制系统:从入门到精通的9大实践技巧
# 摘要
自动化控制系统作为现代工业和基础设施中的核心组成部分,对提高生产效率和确保系统稳定运行具有至关重要的作用。本文首先概述了自动化控制系统的构成,包括控制器、传感器、执行器以及接口设备,并介绍了控制理论中的基本概念如开环与闭环控制、系统的稳定性。接着,文章深入探讨了自动化控制算法,如PID控制、预测控制及模糊控制的原理和应用。在设计实践方面,本文详述了自动化控制系统
【环保与效率并重】:爱普生R230废墨清零,绿色维护的新视角
# 摘要
爱普生R230打印机是行业内的经典型号,本文旨在对其废墨清零过程的必要性、环保意义及其对打印效率的影响进行深入探讨。文章首先概述了爱普生R230打印机及其废墨清零的重要性,然后从环保角度分析了废墨清零的定义、目的以及对环境保护的贡献。接着,本文深入探讨了废墨清零的理论基础,提出了具体的实践方法,并分析了废墨清零对打印机效率的具体影响,包括性能提升和维护周期的优化。最后,本文通过实际应用案例展示了废墨清零在企业和家用环境中的应用效果,并对未来的绿色技术和可持续维护策略进行了展望。
# 关键字
爱普生R230;废墨清零;环保;打印机效率;维护周期;绿色技术
参考资源链接:[爱普生R2
【Twig与微服务的协同】:在微服务架构中发挥Twig的最大优势

# 摘要
本文首先介绍了Twig模板引擎和微服务架构的基础知识,探讨了微服务的关键组件及其在部署和监控中的应用。接着,本文深入探讨了Twig在微服务中的应用实践,包括服务端渲染的优势、数据共享机制和在服务编排中的应用。随后,文
【电源管理策略】:提高Quectel-CM模块的能效与续航

# 摘要
随着物联网和移动设备的广泛应用,电源管理策略的重要性日益凸显。本文首先概述了电源管理的基础知识,随后深入探讨了Quectel-CM模块的技术参数、电源管理接口及能效优化实践。通过理论与实践相结合的方法,本文分析了提高能效的策略,并探讨了延长设备续航时间的关键因素和技术方案。通过多个应用场景的案例研
STM32 CAN低功耗模式指南:省电设计与睡眠唤醒的策略
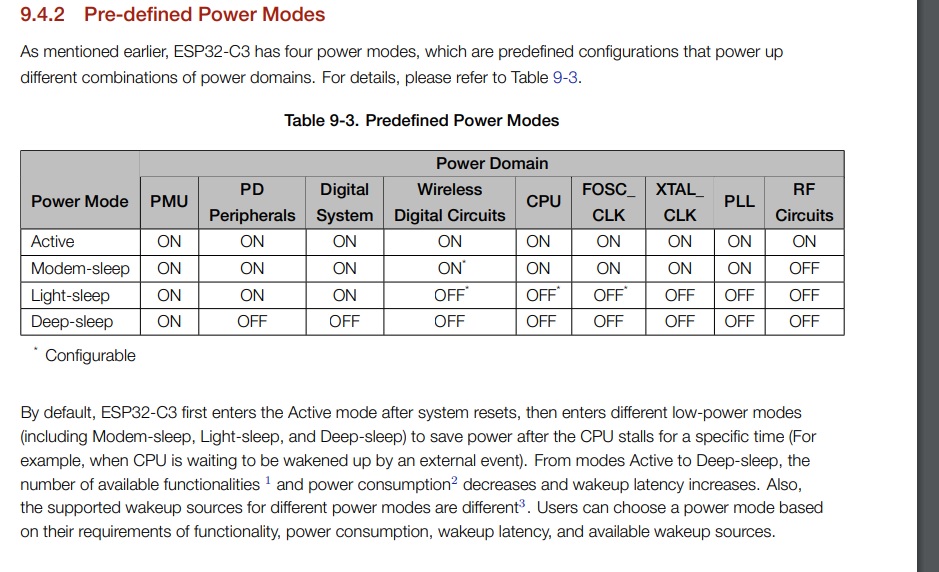
# 摘要
本文旨在全面探讨STM32微控制器在CAN通信中实现低功耗模式的设计与应用。首先,介绍了STM32的基础硬件知识,包括Cortex-M核心架构、时钟系统和电源管理,以及CAN总线技术的原理和优势。随后,详细阐述了低功耗模式的实现方法,包括系统与CAN模块的低功耗配置、睡眠与唤醒机制,以及低功耗模式下的诊断与
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )