Advantages and Applicable Scenarios of unordered_map in Big Data Processing
发布时间: 2024-09-15 18:30:09 阅读量: 25 订阅数: 26 

Data.Science.and.Big.Data.Analytics
# 1. An Overview of Data Structures in Data Processing
Data structures refer to specific methods for organizing and storing data in a computer, ***mon data structures include arrays, linked lists, stacks, and queues. In big data processing, selecting the appropriate data structure is crucial, as it can significantly impact the efficiency and performance of algorithms. For instance, in scenarios requiring rapid lookup, utilizing data structures like hash tables can greatly enhance processing speed. Data structures have a profound effect on the efficiency of algorithms, and exceptional data structure design can provide greater efficiency and performance during the processing of massive datasets.
The choice of data structure should be made based on specific problem requirements, considering factors such as data scale and access patterns. In big data processing, the appropriate choice of data structure can effectively enhance algorithm efficiency, offering better support and optimization for the data processing workflow.
# 2. Introduction to unordered_map and Its Characteristics
2.1 Brief Introduction to unordered_map
unordered_map is an associative container in C++ STL that provides rapid lookup capabilities based on hash tables. Unlike traditional maps, unordered_map does not store elements in a specific order but instead calculates the storage location of elements directly using a hash function. This feature makes unordered_map highly efficient in operations such as lookup, insertion, and deletion.
#### 2.1.1 Differences Between unordered_map and map
unordered_map and map are both associative containers, but they have an important difference: map is an ordered container implemented based on red-black trees, where elements are stored in order according to their key values. In contrast, unordered_map is an unordered container based on hash tables, with element storage positions determined by hash functions. Therefore, map is used in scenarios requiring order, while unordered_map is favored in situations where lookup efficiency is more critical.
#### 2.1.2 Internal Implementation of unordered_map
unordered_map uses a hash table to store data internally, which consists of several buckets. Each bucket holds a linked list or a red-black tree. When inserting an element, the hash value is first calculated based on the element's key, and then the element is located in the corresponding bucket. The element is then inserted into the linked list or red-black tree within the bucket. During lookup, the element is found by locating the corresponding bucket through the hash value and searching within the bucket, achieving an average time complexity of O(1) for lookup.
2.2 Advantages of unordered_map
unordered_map has a clear advantage in most scenarios, primarily in the efficiency of operations such as lookup, insertion, and deletion.
#### 2.2.1 Lookup with O(1) Time Complexity
Thanks to the characteristics of hash tables, unordered_map can achieve O(1) time complexity for element lookup, which is crucial for rapid retrieval in large-scale data processing. Regardless of the data scale, unordered_map maintains a nearly constant lookup efficiency.
#### 2.2.2 Efficiency in Insertion and Deletion Operations
In terms of insertion and deletion of elements, unordered_map is also highly efficient. To insert an element, it is only necessary to calculate its storage position using the hash function and insert it into the corresponding bucket; to delete an element, it can be quickly located and removed. This efficiency makes unordered_map an indispensable tool for processing large-scale data.
In summary, as an associative container implemented based on hash tables, unordered_map has significant advantages in big data processing, especially suitable for scenarios requiring efficient lookup, insertion, and deletion operations.
# 3. Applications of unordered_map in

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CMOS集成电路设计实战解码】:从基础到高级的习题详解,理论与实践的完美融合
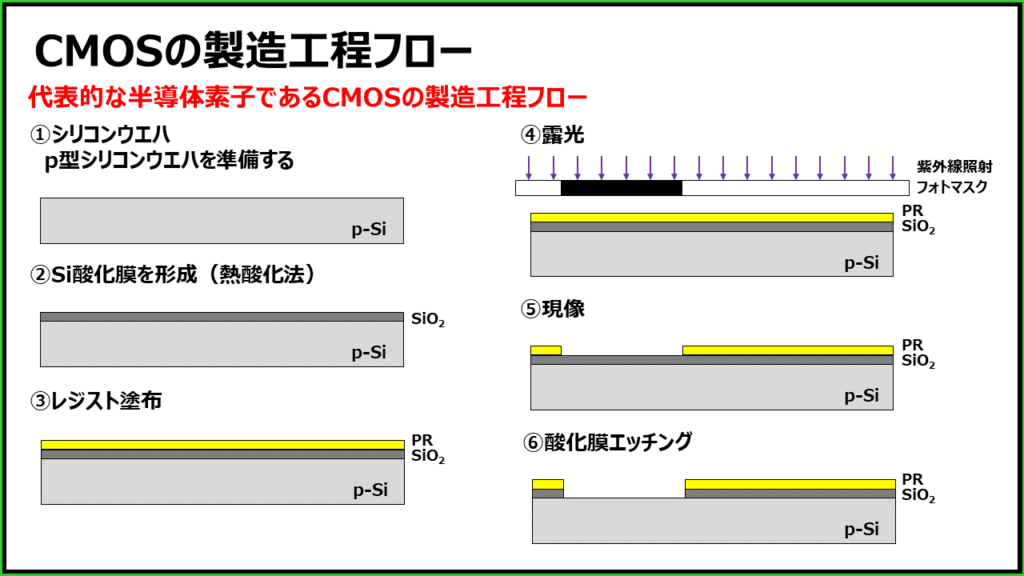
# 摘要
CMOS集成电路设计是现代电子系统中不可或缺的一环,本文全面概述了CMOS集成电路设计的关键理论和实践操作。首先,介绍了CMOS技术的基础理论,包括晶体管工作机制、逻辑门设计基础、制造流程和仿真分析。接着,深入探讨了CMOS集成电路的设计实践,涵盖了反相器与逻辑门设计、放大器与模拟电路设计,以及时序电路设计。此外,本文还
CCS高效项目管理:掌握生成和维护LIB文件的黄金步骤

# 摘要
本文深入探讨了CCS项目管理和LIB文件的综合应用,涵盖了项目设置、文件生成、维护优化以及实践应用的各个方面。文中首先介绍了CCS项目的创建与配置、编译器和链接器的设置,然后详细阐述了LIB文件的生成原理、版本控制和依赖管理。第三章重点讨论了LIB文件的代码维护、性能优化和自动化构建。第四章通过案例分析了LIB文件在多项目共享、嵌入式系统应用以及国际化与本地化处理中的实际应
【深入剖析Visual C++ 2010 x86运行库】:架构组件精讲

# 摘要
Visual C++ 2010 x86运行库是支持开发的关键组件,涵盖运行库架构核心组件、高级特性与实现,以及优化与调试等多个方面。本文首先对运行库的基本结构、核心组件的功能划分及其交互机制进行概述。接着,深入探讨运行时类型信息(RTTI)与异常处理的工作原理和优化策略,以及标准C++内存管理接口和内存分配与释放策略。本文还阐述了运行库的并发与多线程支持、模板与泛型编程支持,
从零开始掌握ACD_ChemSketch:功能全面深入解读
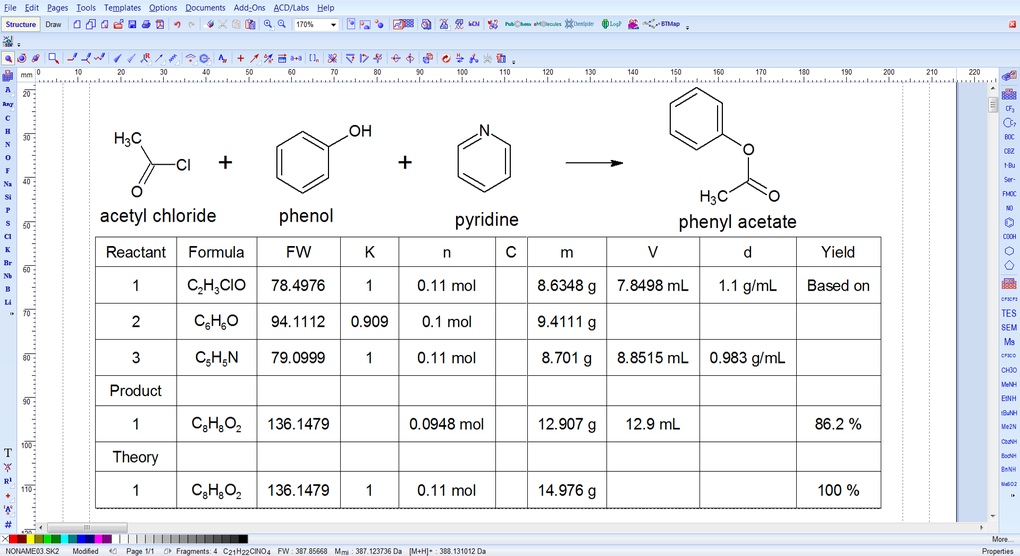
# 摘要
ACD_ChemSketch是一款广泛应用于化学领域的绘图软件,本文概述了其基础和高级功能,并探讨了在科学研究中的应用。通过介绍界面布局、基础绘图工具、文件管理以及协作功能,本文为用户提供了掌握软件操作的基础知识。进阶部分着重讲述了结构优化、立体化学分析、高
蓝牙5.4新特性实战指南:工业4.0的无线革新

# 摘要
蓝牙技术是工业4.0不可或缺的组成部分,它通过蓝牙5.4标准实现了新的通信特性和安全机制。本文详细概述了蓝牙5.4的理论基础,包括其新增功能、技术规格,以及与前代技术的对比分析。此外,探讨了蓝牙5.4在工业环境中网络拓扑和设备角色的应用,并对安全机制进行了评估。本文还分析了蓝牙5.4技术的实际部署,包
【Linux二进制文件执行错误深度剖析】:一次性解决执行权限、依赖、环境配置问题(全面检查必备指南)
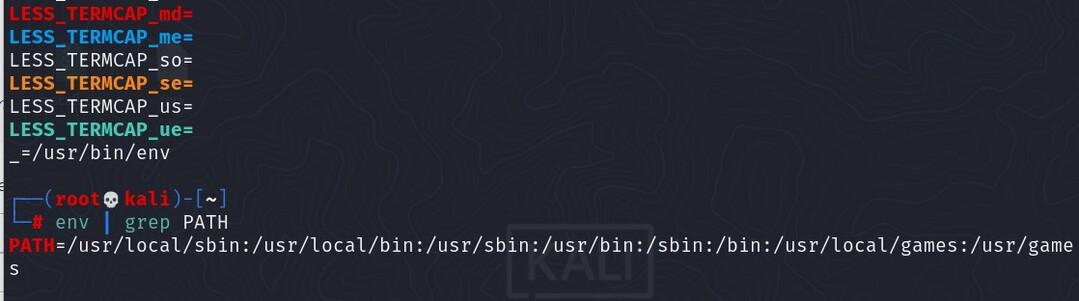
# 摘要
本文详细探讨了二进制文件执行过程中遇到的常见错误,并提出了一系列理论与实践上的解决策略。首先,针对执行权限问题,文章从权限基础理论出发,分析了权限设置不当所导致的错误,并探讨了修复权限的工具和方法。接着,文章讨论了依赖问题,包括依赖管理基础、缺失错误分析以及修复实践,并对比了动态与静态依赖。环境配置问题作为另一主要焦点,涵盖了
差分输入ADC滤波器设计要点:实现高效信号处理
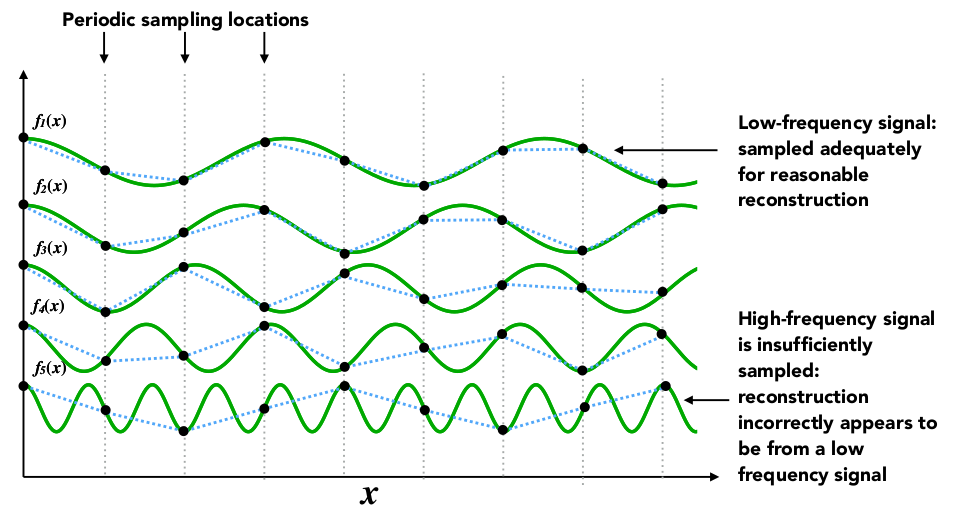
# 摘要
本论文详细介绍了差分输入模数转换器(ADC)滤波器的设计与实践应用。首先概述了差分输入ADC滤波器的理论基础,包括差分信号处理原理、ADC的工作原理及其类型,以及滤波器设计的基本理论。随后,本研究深入探讨了滤波器设计的实践过程,从确定设计规格、选择元器件到电路图绘制、仿真、PCB布局,以及性能测试与验证的方法。最后,论文分析了提高差分输入ADC滤波器性能的优化策略,包括提升精
【HPE Smart Storage性能提升指南】:20个技巧,优化存储效率

# 摘要
本文深入探讨了HPE Smart Storage在性能管理方面的方法与策略。从基础性能优化技巧入手,涵盖了磁盘配置、系统参数调优以及常规维护和监控等方面,进而探讨高级性能提升策略,如缓存管理、数据管理优化和负载平衡。在自动化和虚拟化环境下,本文分析了如何利用精简配置、快照技术以及集成监控解决方案来进一步提升存储性能,并在最后章节中讨论了灾难恢复与备份策略的设计与实施。通过案
【毫米波雷达性能提升】:信号处理算法优化实战指南
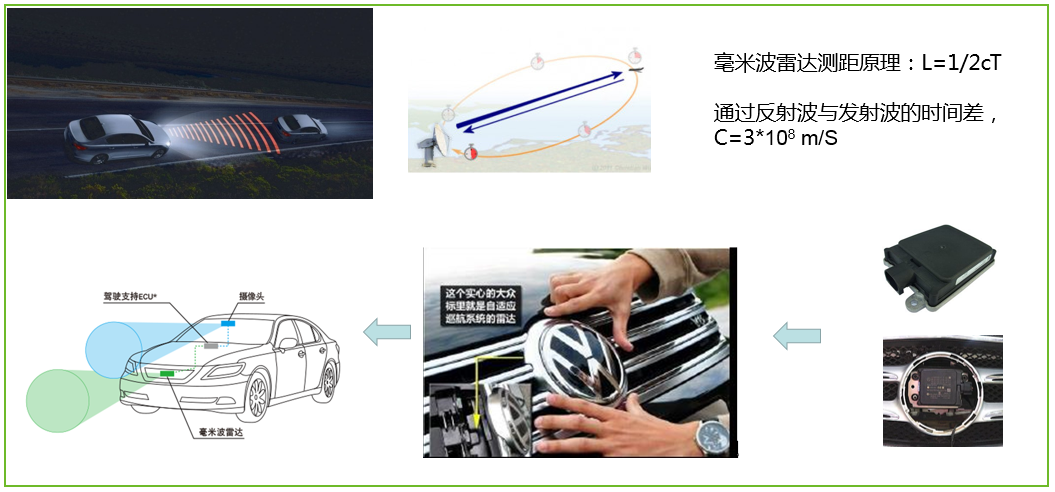
# 摘要
毫米波雷达信号处理是一个涉及复杂数学理论和先进技术的领域,对于提高雷达系统的性能至关重要。本文首先概述了毫米波雷达信号处理的基本理论,包括傅里叶变换和信号特性分析,然后深入探讨了信号处理中的关键技术和算法优化策略。通过案例分析,评估了现有算法性能,并介绍了信号处理软件实践和代码优化技巧。文章还探讨了雷达系统的集成、测试及性能评估方法,并展望了未来毫米波雷达性能提升的技术趋
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )