unordered_map Size and Capacity Operations Analysis
发布时间: 2024-09-15 18:21:28 阅读量: 20 订阅数: 26 

C++11 unordered_map与map(插入,遍历,Find)效率对比。
# 1.1 Understanding unordered_map
In the C++ STL, `unordered_map` is an associative container that utilizes a hash table as its underlying data structure. The hash table maps key-value pairs to buckets using a hash function, facilitating rapid lookups, insertions, and deletions. `unordered_map` is suitable for scenarios that require quick access to key-value pairs, such as storing unique keys with their corresponding values. It offers constant time complexity for search, insertion, and deletion operations, providing fast performance. Using `unordered_map` allows for the quick定位 of elements without the need for traversing the entire container in a specific order. This is particularly important for large-scale data storage and retrieval, ensuring that programs maintain high efficiency when dealing with vast amounts of data.
One of the characteristics of `unordered_map` is that its elements are stored in an unordered manner, and the order of the key-value pairs depends on the outcomes of the hash function. Therefore, if the order of elements is a requirement, other ordered containers should be chosen for data storage.
# 2. Construction and Initialization of unordered_map
The construction and initialization of `unordered_map` is the first step in using this data structure, and an appropriate construction method can enhance the efficiency and readability of the program.
#### 2.1 Creating an unordered_map Object
The creation of an unordered associative container can be achieved using either the default constructor or parameterized constructors.
##### 2.1.1 Default Constructor
The default constructor will create an empty `unordered_map` object, as shown in the example code below:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<int, std::string> myMap;
return 0;
}
```
##### 2.1.2 Parameterized Constructor
The parameterized constructor accepts an initial size and optional hash function and key equality function, for instance:
```cpp
std::unordered_map<int, std::string> myMap(10); // Initial size is 10
```
#### 2.2 Initializing an unordered_map
An `unordered_map` can be initialized using an initializer list `{}`, the `insert` method, or the `emplace` method.
##### 2.2.1 Using an Initializer List
An `unordered_map` can be initialized with key-value pairs using an initializer list, as shown in the example code below:
```cpp
std::unordered_map<int, std::string> myMap = {{1, "One"}, {2, "Two"}, {3, "Three"}};
```
##### 2.2.2 Usage of the insert Method
The `insert` method can be used to add elements to an `unordered_map`, as demonstrated in the example code below:
```cpp
myMap.insert({4, "Four"});
```
##### 2.2.3 Usage of the emplace Method
The `emplace` method can construct key-value pairs directly from its parameters and insert them into the `unordered_map`, as shown in the example code below:
```cpp
myMap.emplace(5, "Five");
```
When constructing and initializing an `unordered_map`, choosing the appropriate construction method can help improve program efficiency and readability, laying a foundation for subsequent operations.
# 3. Element Access in unordered_map
`unordered_map` is an associative container in the C++ STL that offers fast lookup, insertion, and deletion operations. When using an `unordered_map`, it's essential to understand how to access and modify its elements. This chapter will introduce the operations for accessing and modifying elements in an `unordered_map`.
#### 3.1 Accessing Elements
In an `unordered_map`, elements can be accessed by their keys. There are two common methods for acces

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
理解SN29500-2010:IT专业人员的标准入门手册

# 摘要
SN29500-2010标准作为行业规范,对其核心内容和历史背景进行了概述,同时解析了关键条款,如术语定义、管理体系要求及信息安全技术要求等。本文还探讨了如何在实际工作中应用该标准,包括推广策略、员工培训、监督合规性检查,以及应对标准变化和更新的策略。文章进一步分析了SN29500-2010带来的机遇和挑战,如竞争优势、技术与资源
红外遥控编码:20年经验大佬揭秘家电控制秘籍
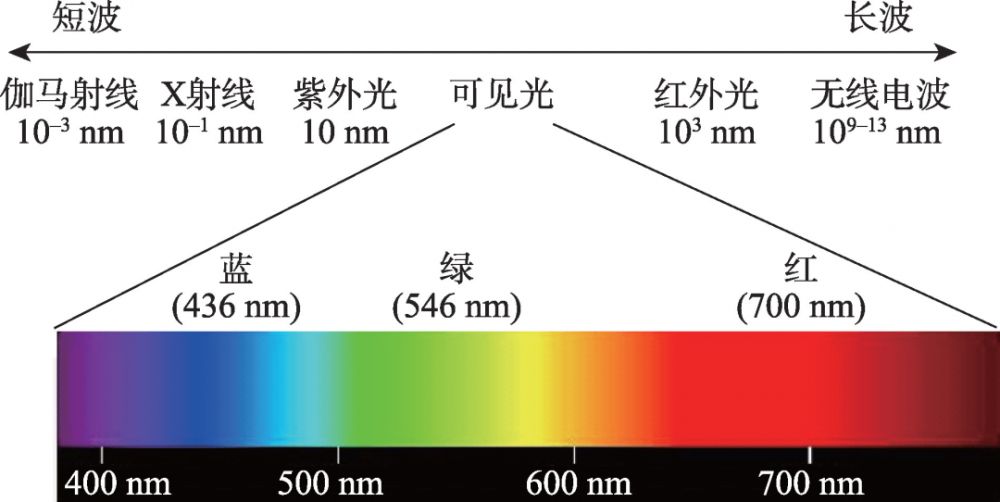
# 摘要
红外遥控技术作为无线通信的重要组成部分,在家电控制领域占有重要地位。本文从红外遥控技术概述开始,详细探讨了红外编码的基础理论,包括红外通信的原理、信号编码方式、信号捕获与解码。接着,本文深入分析了红外编码器与解码器的硬件实现,以及在实际编程实践中的应用。最后,本文针对红外遥控在家电控制中的应用进行了案例研究,并展望了红外遥控技术的未来趋势与创新方向,特别是在智能家居集成和技术创新方面。文章旨在为读者提
【信号完整性必备】:7系列FPGA SelectIO资源实战与故障排除
# 摘要
随着数字电路设计复杂度的提升,FPGA(现场可编程门阵列)已成为实现高速信号处理和接口扩展的重要平台。本文对7系列FPGA的SelectIO资源进行了深入探讨,涵盖了其架构、特性、配置方法以及在实际应用中的表现。通过对SelectIO资源的硬件组成、电气标准和参数配置的分析,本文揭示了其在高速信号传输和接口扩展中的关键作用。同时,本文还讨论了信号完整性
C# AES加密:向量化优化与性能提升指南
# 摘要
本文深入探讨了C#中的AES加密技术,从基础概念到实现细节,再到性能挑战及优化技术。首先,概述了AES加密的原理和数学基础,包括其工作模式和关键的加密步骤。接着,分析了性能评估的标准、工具,以及常见的性能瓶颈,着重讨论了向量化优化技术及其在AES加密中的应用。此外,本文提供了一份实践指南,包括选择合适的加密库、性能优化案例以及在安全性与性能之间寻找平衡点的策略。最后,展望了AES加密技术的未来趋势,包括新兴加密算法的演进和性能优化的新思路。本研究为C#开发者在实现高效且安全的AES加密提供了理论基础和实践指导。
# 关键字
C#;AES加密;对称加密;性能优化;向量化;SIMD指令
RESTful API设计深度解析:Web后台开发的最佳实践

# 摘要
本文全面探讨了RESTful API的设计原则、实践方法、安全机制以及测试与监控策略。首先,介绍了RESTful API设计的基础知识,阐述了核心原则、资源表述、无状态通信和媒体类型的选择。其次,通过资源路径设计、HTTP方法映射到CRUD操作以及状态码的应用,分析了RESTful API设计的具体实践。
【Buck电路布局绝招】:PCB设计的黄金法则
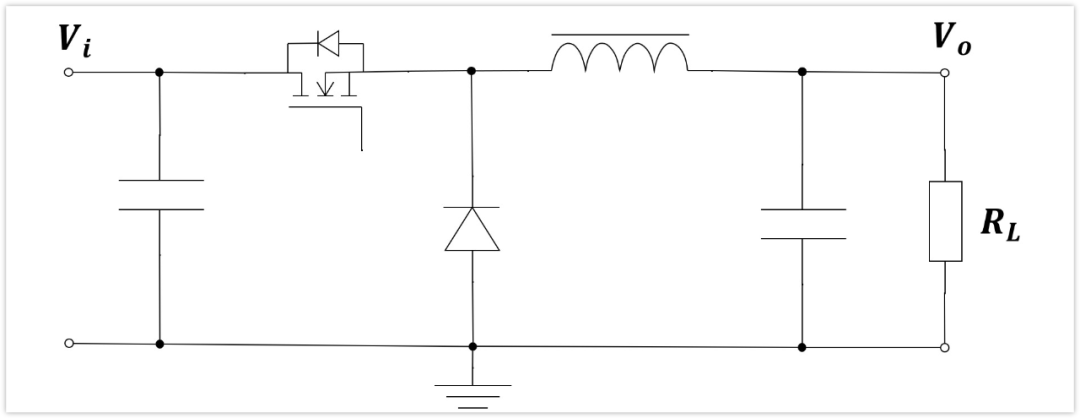
# 摘要
Buck转换器是一种广泛应用于电源管理领域的直流-直流转换器,它以高效和低成本著称。本文首先阐述了Buck转换器的工作原理和优势,然后详细分析了Buck电路布局的理论基础,包括关键参数、性能指标、元件选择、电源平面设计等。在实践技巧方面,本文提供了一系列提高电路布局效率和准确性的方法,并通过案例分析展示了低噪声、高效率以及小体积高功率密度设计的实现。最后,本文展望了Buck电
揭秘苹果iap2协议:高效集成与应用的终极指南
# 摘要
本文系统介绍了IAP2协议的基础知识、集成流程以及在iOS平台上的具体实现。首先,阐述了IAP2协议的核心概念和环境配置要点,包括安装、配置以及与iOS系统的兼容性问题。然后,详细解读了IAP2协议的核心功能,如数据交换模式和认证授权机制,并通过实例演示了其在iOS应用开发和数据分析中的应用技巧。此外,文章还探讨了IAP2协议在安全、云计算等高级领域的应用原理和案例,以及性能优化的方法和未来发展的方向。最后,通过大
ATP仿真案例分析:故障相电压波形A的调试、优化与实战应用
# 摘要
本文对ATP仿真软件及其在故障相电压波形A模拟中的应用进行了全面介绍。首先概述了ATP仿真软件的发展背景与故障相电压波形A的理论基础。接着,详细解析了模拟流程,包括参数设定、步骤解析及结果分析方法。本文还深入探讨了调试技巧,包括ATP仿真环境配置和常见问题的解决策略。在此基础上,提出了优化策略,强调参数优化方法和提升模拟结果精确性的重要性。最后,通过电力系统的实战应用案例,本文展示了故障分析、预防与控制策略的实际效果,并通过案例研究提炼出有价值的经验与建议。
# 关键字
ATP仿真软件;故障相电压波形;模拟流程;参数优化;故障预防;案例研究
参考资源链接:[ATP-EMTP电磁暂
【流式架构全面解析】:掌握Kafka从原理到实践的15个关键点

# 摘要
流式架构作为处理大数据的关键技术之一,近年来受到了广泛关注。本文首先介绍了流式架构的概念,并深入解析了Apache Kafka作为流式架构核心组件的引入背景和基础知识。文章深入探讨了Kafka的架构原理、消息模型、集群管理和高级特性,以及其在实践中的应用案例,包括高可用集群的实现和与大数据生态以及微
【SIM卡故障速查速修秘籍】:10分钟内解决无法识别问题

# 摘要
本文旨在为读者提供一份全面的SIM卡故障速查速修指导。首先介绍了SIM卡的工作原理及其故障类型,然后详细阐述了故障诊断的基本步骤和实践技巧,包括使用软件工具和硬件检查方法。本文还探讨了常规和高级修复策略,以及预防措施和维护建议,以减少SIM卡故障的发生。通过案例分析,文章详细说明了典型故障的解决过程。最后,展望了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )