Insertion and Deletion Techniques for Elements in an unordered_map
发布时间: 2024-09-15 18:17:38 阅读量: 18 订阅数: 22 
# 1. Introduction to unordered_map
The `unordered_map` is an associative container in the C++ Standard Template Library (STL) that offers fast lookup, insertion, and deletion of elements. Unlike a `map`, the elements in an `unordered_map` are not ordered by a specific sequence but are stored based on the values returned by a hash function, thus making the search for elements highly efficient.
Why choose to use `unordered_map`? Because in most cases, `unordered_map` is faster than `map`. When you need to quickly find elements without caring about the order of elements, `unordered_map` is a great choice. Additionally, the time complexity of `unordered_map` is O(1), whereas that of `map` is O(log n), making `unordered_map` more efficient for processing large amounts of data.
# 2. Basic Operations of unordered_map
The `unordered_map` is one of the associative containers provided by the C++ STL, offering rapid lookup operations and efficient performance when inserting, deleting, and accessing elements. Below, we will introduce the initialization, insertion of elements, and accessing elements of an `unordered_map`.
#### Initialization of unordered_map
Before using an `unordered_map`, it must be initialized. Initialization can be done in the following way to create an empty `unordered_map`:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> myMap;
return 0;
}
```
The above example code shows how to initialize an empty `unordered_map` that stores keys as strings and values as integers. Next, we will insert some elements into this `unordered_map`.
#### Inserting Elements
The `insert()` method can be used to add elements to an `unordered_map`. For example:
```cpp
int main() {
std::unordered_map<std::string, int> myMap;
// Insert a single element
myMap.insert(std::make_pair("apple", 5));
// Insert multiple elements at once
myMap.insert({{"banana", 3}, {"cherry", 7}});
return 0;
}
```
In the code above, we first insert an element with the key "apple" and a value of 5, and then we insert two key-value pairs at once. Next, let's see how to access elements in an `unordered_map`.
#### Accessing Elements
Elements in an `unordered_map` can be conveniently accessed using the `[]` operator. Example code is shown below:
```cpp
int main() {
std::unordered_map<std::string, int> myMap;
myMap.insert(std::make_pair("apple", 5));
// Access the element
int quantity = myMap["apple"];
std::cout << "Quantity of apples: " << quantity << std::endl;
return 0;
}
```
In this example, we accessed the value corresponding to the key "apple" in the `unordered_map` and output it to the console. Now that we have learned how to initialize, insert elements, and access elements, we will delve deeper into how to delete elements from an `unordered_map`.
# 3. Deleting Elements in an unordered_map
When using an `unordered_map`, we often need to perform deletion operations on elements. These operations include deleting a single element, deleting multiple elements in bulk, and clearing an entire `unordered_map`. Through the following content, we will delve into the implementation methods and considerations for these deletion operations.
#### Deleting a Single Element
The `erase` function can be used to delete a single element from an `unordered_map`. This function takes one parameter, the key of the element to be deleted. Before deletion, we need to perform a search operation to ensure that the element exists in the `unordered_map`. Here is a simple example code:
```cpp
// Delete the element with key key
if (mymap.find(key) != mymap.end()) {
mymap.erase(key);
}
```
#### Deleting Multiple Elements
For bulk deletion operations, we can combine a loop with the `erase` function to achieve this. During the traversal of the `unordered_map`, we can use conditional statements to determine whether to delete the current element. Below is an example demonstrating how to delete elements with values less than 10:
```cpp
for (auto it = mymap.begin(); it != mymap.end();) {
if (it->second < 10) {
it = mymap.erase(it);
} else {
++it;
}
}
```
#### Clearing an unordered_map
To completely clear an `unordered_map`, we can use the `clear` function. Calling this function will remove all elements from the `unordered_map` and reset the number of buckets to 0. Here is a simple example:
```cpp
mymap.clear();
```
With the `erase` and `clear` functions, we can conveniently delete elements from an `unordered_map`, whether it's a single or bulk deletion. When performing these operations, we need to ensure that the element exists to avoid unexpected situations. For scenarios that require frequent deletion or clearing of an `unordered_map`, the appropriate use of these operation functions can enhance the efficiency of the code.
# 4. Searching and Traversing Elements in an unordered_map
Searching and traversing elements in an `unordered_map` are very common operations. Through searching and traversing, we can retrieve the data stored in an `unordered_map` for further processing and analysis.
#### 4.1 Using the find Function to Search for Elements
In an `unordered_map`, the `find` function can be used to search for specific elements. The `find` function takes a key as a parameter, and if the key exists in the `unordered_map`, it returns an iterator pointing to the key-value pair; if the key does not exist, it returns the `end()` iterator of the `unordered_map`.
The following example code demonstrates how to use the `find` function to search for elements in an `unordered_map`:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> myMap = {{"apple", 2}, {"banana", 3}, {"cherry", 4}};
auto it = myMap.find("banana");
if (it != myMap.end()) {
std::cout << "Key 'banana' found. Value is: " << it->second << std::endl;
} else {
std::cout << "Key 'banana' not found." << std::endl;
}
return 0;
}
```
By running the above code, we can obtain the output result, which shows that the value corresponding to the key `'banana'` is `3`.
#### 4.2 Traversing All Elements of an unordered_map
Traversing all elements in an `unordered_map` is a common operation, and there are usually multiple ways to achieve this. A simple and straightforward method is to use a range-based for loop to traverse each key-value pair in the `unordered_map`.
The following example code shows how to use a range-based for loop to traverse all elements of an `unordered_map`:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> myMap = {{"apple", 2}, {"banana", 3}, {"cherry", 4}};
for (const auto& pair : myMap) {
std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;
}
return 0;
}
```
With the above code, we can sequentially output all the key-value pairs in the `unordered_map`.
#### 4.3 Traversing with Iterators
In addition to using range-based for loops, we can also traverse elements in an `unordered_map` using iterators. Iterators provide more flexibility to control the traversal process and implement specific requirements and operations.
The following example code demonstrates how to use iterators to traverse all elements in an `unordered_map`:
```cpp
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, int> myMap = {{"apple", 2}, {"banana", 3}, {"cherry", 4}};
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;
}
return 0;
}
```
With the above code, we can sequentially access all key-value pairs in the `unordered_map` using iterators.
The above content covers the searching and traversing of elements in an `unordered_map`. Searching and traversing are important parts of operating on an `unordered_map`. Mastering these methods can improve the efficiency of using `unordered_map`.
# 5. Performance Optimization of unordered_map
The `unordered_map` is a commonly used data structure, but when dealing with large-scale data, we need to consider how to optimize its performance. This chapter will introduce how to further optimize the performance of `unordered_map`, including underlying implementation, optimization of hash functions, and adjustment of the number of buckets.
1. **Understanding the Underlying Implementation of unordered_map**
In the C++ standard library, `unordered_map` is implemented using a hash table, and the advantage of using a hash table is that the time complexity for lookup, insertion, and deletion operations is O(1). The underlying structure of an `unordered_map` is typically composed of an array, where each element is called a "bucket". When hash collisions occur (i.e., multiple keys are mapped to the same bucket), `unordered_map` uses data structures such as linked lists or red-black trees to store these key-value pairs.
2. **Optimizing the Hash Function of unordered_map**
The choice of the hash function is crucial for the performance of an `unordered_map`. A good hash function should distribute elements evenly across different buckets to reduce the occurrence of hash collisions. If the default hash function is not suitable for a specific type of key, a custom hash function can be defined to improve performance.
Below is an example of a custom hash function (for string types):
```cpp
struct MyHash {
size_t operator()(const std::string& str) const {
size_t hash = 0;
for (char c : str) {
hash = hash * 31 + c;
}
return hash;
}
};
```
3. **Increasing the Number of Buckets to Enhance Performance**
An `unordered_map` uses buckets to store key-value pairs, and the number of buckets can be specified through the second parameter of the constructor, with the default value being 8. Increasing the number of buckets can reduce hash collisions, thereby improving the performance of the `unordered_map`. However, too many buckets can also lead to additional memory consumption, so it is necessary to carefully choose the number of buckets based on the actual situation.
```mermaid
graph LR
A[Original Bucket Count] --> B{Does Performance Meet Requirements?}
B -- Yes --> C[Performance Satisfactory]
B -- No --> D[Increase Bucket Count]
D --> E{Is Memory Consumption Acceptable?}
E -- Yes --> F[Optimization Complete]
E -- No --> G[Appropriately Decrease Bucket Count]
G --> F
```
By using these methods, we can optimize the performance of `unordered_map`, making it more suitable for handling large-scale data and improving the efficiency and speed of the program. In actual development, choose the appropriate optimization strategy based on the scale of the data and operation requirements to achieve the best performance.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
学习率对RNN训练的特殊考虑:循环网络的优化策略

# 1. 循环神经网络(RNN)基础
## 循环神经网络简介
循环神经网络(RNN)是深度学习领域中处理序列数据的模型之一。由于其内部循环结
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
Epochs调优的自动化方法
# 1. Epochs在机器学习中的重要性
机器学习是一门通过算法来让计算机系统从数据中学习并进行预测和决策的科学。在这一过程中,模型训练是核心步骤之一,而Epochs(迭代周期)是决定模型训练效率和效果的关键参数。理解Epochs的重要性,对于开发高效、准确的机器学习模型至关重要。
在后续章节中,我们将深入探讨Epochs的概念、如何选择合适值以及影响调优的因素,以及如何通过自动化方法和工具来优化Epochs的设置,从而
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
【批量大小与存储引擎】:不同数据库引擎下的优化考量

# 1. 数据库批量操作的理论基础
数据库是现代信息系统的核心组件,而批量操作作为提升数据库性能的重要手段,对于IT专业人员来说是不可或缺的技能。理解批量操作的理论基础,有助于我们更好地掌握其实践应用,并优化性能。
## 1.1 批量操作的定义和重要性
批量操作是指在数据库管理中,一次性执行多个数据操作命
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
【损失函数与随机梯度下降】:探索学习率对损失函数的影响,实现高效模型训练

# 1. 损失函数与随机梯度下降基础
在机器学习中,损失函数和随机梯度下降(SGD)是核心概念,它们共同决定着模型的训练过程和效果。本
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
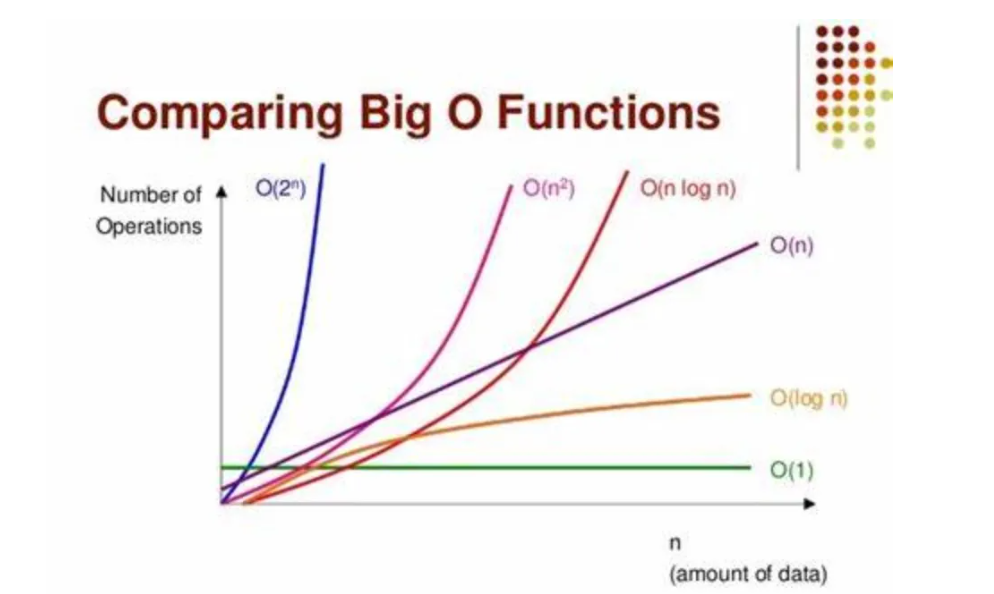
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
激活函数理论与实践:从入门到高阶应用的全面教程

# 1. 激活函数的基本概念
在神经网络中,激活函数扮演了至关重要的角色,它们是赋予网络学习能力的关键元素。本章将介绍激活函数的基础知识,为后续章节中对具体激活函数的探讨和应用打下坚实的基础。
## 1.1 激活函数的定义
激活函数是神经网络中用于决定神经元是否被激活的数学函数。通过激活函数,神经网络可以捕捉到输入数据的非线性特征。在多层网络结构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )