【进阶】Actor-Critic方法的理论基础
发布时间: 2024-06-27 01:39:03 阅读量: 8 订阅数: 25 
# 2.1 强化学习基础
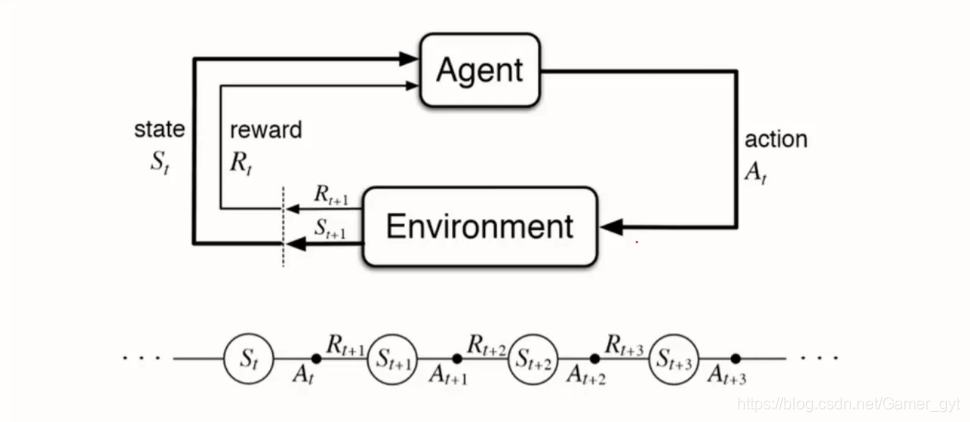
强化学习是一种机器学习范式,它允许代理在与环境交互时学习最佳行为策略。强化学习的三个基本要素是:
- **环境:**代理与之交互的外部世界,它提供状态和奖励。
- **代理:**在环境中采取行动并学习最佳策略的实体。
- **奖励:**代理在采取特定行动后收到的反馈,用于评估行动的优劣。
### 2.1.1 马尔可夫决策过程
马尔可夫决策过程 (MDP) 是强化学习中常用的数学模型。它定义了一个由以下元素组成的环境:
- **状态空间:**代理可以处于的所有可能状态的集合。
- **动作空间:**代理在每个状态下可以采取的所有可能动作的集合。
- **转移概率:**给定当前状态和动作,代理进入下一状态的概率。
- **奖励函数:**代理在每个状态下采取特定动作后收到的奖励。
### 2.1.2 值函数和策略
值函数和策略是强化学习中的两个重要概念:
- **值函数:**衡量从给定状态开始采取最佳策略的长期奖励。
- **策略:**定义代理在每个状态下采取的最佳动作。
# 2. Actor-Critic方法的理论基础
### 2.1 强化学习基础
#### 2.1.1 马尔可夫决策过程
马尔可夫决策过程(MDP)是一个数学框架,用于建模顺序决策问题。它由以下元素组成:
- **状态空间** S:系统可能处于的所有可能状态的集合。
- **动作空间** A:在每个状态下可以采取的所有可能动作的集合。
- **转移概率** P(s'|s, a):从状态 s 执行动作 a 后转移到状态 s' 的概率。
- **奖励函数** R(s, a):在状态 s 执行动作 a 后获得的奖励。
- **折扣因子** γ:未来奖励的折现率(0 ≤ γ ≤ 1)。
#### 2.1.2 值函数和策略
在MDP中,值函数和策略是两个关键概念:
- **值函数** V(s):从状态 s 开始,遵循给定策略 π 采取行动,期望获得的总奖励的折扣和。
- **策略** π(a|s):在状态 s 下选择动作 a 的概率分布。
### 2.2 Actor-Critic方法的原理
Actor-Critic方法是一种无模型的强化学习算法,它同时学习一个策略(Actor网络)和一个值函数(Critic网络)。
#### 2.2.1 Actor网络和Critic网络
- **Actor网络**:一个神经网络,它输出动作概率分布 π(a|s)。
- **Critic网络**:一个神经网络,它估计值函数 V(s) 或动作值函数 Q(s, a)。
#### 2.2.2 策略梯度定理
Actor-Critic方法使用策略梯度定理来更新Actor网络。策略梯度定理指出,对于一个策略 π 和值函数 V,策略梯度为:
```
∇_π J(π) = E[∇_π log π(a|s) * (Q(s, a) - V(s))]
```
其中,J(π) 是策略 π 的目标函数(通常是期望奖励)。
### 2.3 Actor-Critic方法的优势和局限
#### 2.3.1 优势:无模型、数据效率高
- **无模型**:Actor-Critic方法不需要环境模型,因为它直接从经验中学习。
- **数据效率高**:Actor-Critic方法可以从较少的数据中学习,因为它利用了值函数的估计来指导策略的更新。
#### 2.3.2 局限:不稳定、收敛慢
- **不稳定**:Actor-Critic方法可能不稳定,因为Actor网络和Critic网络的更新相互影响。
- **收敛慢**:Actor-Critic方法可能收敛缓慢,特别是对于复杂的任务。
# 3.1 连续动作空间的 Actor-Critic 方法
在连续动作空间中,Actor 网络输出的是连续的动作值,而 Critic 网络输出的是动作价值函数的估计值。常用的连续动作空间 Actor-Critic 方法有:
#### 3.1.1 确定性策略梯度算法(DPG)
DPG 是一种确定性策略梯度算法,即 Actor 网络输出的是确定性的动作值。DPG 算法的更新公式如下:
```python
# Actor 网络更新
actor_loss = -tf.reduce_mean(critic_target(s, actor(s)))
actor_optimizer.minimize(actor_loss, var_list=actor.trainable_variables)
# Critic 网络更新
critic_loss = tf.reduce_mean(tf.square(critic(s, actor(s)) - y))
critic_optimizer.minimize(critic_loss, var_list=critic.trainable_variables)
```
**参数说明:**
* `s`: 状态输入
* `actor`: Actor 网络
* `critic`: Critic 网络
* `critic_target`: 目标 Critic 网络
* `y`: 动作价值函数的目标值
**代码逻辑分析:**
* Actor 网络的更新目标是最大化 Critic 网络对 Actor 网络输出动作的价值估计。
* Critic 网络的更新目标是使 Critic 网络输出的价值估计与真实价值之间的误差最小化。
#### 3.1.2 随机策略梯度算法(SAC)
SAC 是一种随机策略梯度算法,即 Actor 网络输出的是随机的动作值。SAC 算法的更新公式如下:
```python
# Actor 网络更新
actor_loss = -tf.reduce_mean(critic_target(s, actor(s)) - entropy(actor(s)))
actor_optimizer.minimize(actor_loss, var_list=actor.trainable_variables)
# Critic 网络更新
critic_loss = tf.reduce_mean(tf.square(critic(s, actor(s)) - y))
critic_optimizer.minimize(critic_loss, var_list=critic.trainable_variables)
```
**参数说明:**
* `s`: 状态输入
* `actor`: Actor 网络
* `critic`: Critic 网络
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了有关 Python 强化学习的全面文章,涵盖了从基础概念到高级技术的各个方面。专栏标题为“Python 强化学习合集”,旨在为读者提供一个一站式平台,深入了解强化学习的原理和应用。
专栏内容包括:
- 强化学习的基础知识,包括其定义、与其他机器学习方法的区别以及应用领域。
- 强化学习的核心组件,如智能体、环境、状态、奖励和价值函数。
- 奖励设计和价值函数计算等强化学习的关键技术。
通过阅读本专栏,读者将对 Python 强化学习的各个方面获得深入的理解,并能够将这些技术应用于各种实际问题中。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MySQL数据库分库分表:应对数据量激增的有效策略,优化数据库架构,提升系统性能

# 1. MySQL数据库分库分表概述
### 1.1 分库分表的概念
分库分表是将一个大型数据库拆分成多个小的数据库或表,以应对数据量过大或并发访问量过高的情况。分库分表可以提高数据库的性能、可扩展性和容错性。
### 1.2 分库分表的好处
分库分表的主要好处包括:
- **性能提升:**将数据分散到多个数据库或表可以减少单一数据库的负载,从而提高查询和写入性能。
正则表达式替换与PowerShell:提升脚本自动化能力,掌握运维新技能
# 1. 正则表达式的基础**
正则表达式(Regex)是一种强大的工具,用于在文本中匹配、搜索和替换模式。它由一系列字符和元字符组成,这些字符和元字符定义了要匹配的模式。正则表达式可以用来验证输入、解析数据、提取信息和执行文本处理任务。
正则表达式语法基于元字符,这些元字符具有特殊含义。例如,`.` 匹配任何字符,`*` 匹配前一个字符的零次或多次出现,`+` 匹配前一个字符的一
STM32 系统设计:原理、架构与应用详解
# 1. STM32 系统概述**
STM32 是一款基于 ARM Cortex-M 内核的微控制器系列,由意法半导体(STMicroelectronics)开发。它以其高性能、低功耗和广泛的应用而闻名,广泛用于嵌入式系统中。
STM32 系统由一个或多个 ARM Cortex-M 内核、存储器、外设和一个片上系统(SoC)组成。它提供各种外设,包括定时器、ADC、UART、SPI
STM32单片机编程软件无线通信技术应用:连接世界,实现远程控制

# 1. STM32单片机编程基础**
STM32单片机是意法半导体公司推出的高性能微控制器,广泛应用于工业控制、消费电子、医
STM32单片机开发板与物联网的融合:开启智能物联时代,打造万物互联的未来
# 1. STM32单片机开发板概述**
STM32单片机开发板是一种基于ARM Cortex-M系列内核的微控制器开发平台。它集成了各种外围设备和接口,为嵌入式系统开发提供了强大的硬件基础。
STM32单片机开发板具有以下特点:
- 高性能:基于ARM Cortex-M系列内核,提供高计算能力和低功耗。
- 丰富的外设:集成各种外设,如定时器、UART、SPI、I2C等,满足多种应用需求。
- 灵活的扩展性:通过扩展
STM32单片机无线通信编程:连接无线世界的桥梁,拓展嵌入式应用

# 1. STM32单片机无线通信概述
STM32单片机广泛应用于各种嵌入式系统中,无线通信能力是其重要的特性之一。本章将概述STM32单片机的无线通信功能,包括其原理、分类、应用和硬件架构。
## 1.1 无线通信的原理和特点
无线通信是指在没有物理连接的情况下,通过无线电波或其他电磁波在设备之间传输数据的技术。其主要特点包
MATLAB文件操作实战指南:高效管理文件和数据,告别文件混乱
# 1. MATLAB文件操作基础
MATLAB提供了强大的文件操作功能,允许用户轻松地读取、写入、管理和操作文件。本章将介绍MATLAB文件操作的基础知识,
线性回归在工业4.0中的应用:智能制造与预测性维护,提升生产效率

# 1. 线性回归概述
线性回归是一种统计建模技术,用于确定一个或多个自变量与一个因变量之间的线性关系。它广泛应用于工业 4.
:瑞利分布在供应链管理中的意义:预测需求波动,优化库存管理
# 1. 瑞利分布的基本理论
瑞利分布是一种连续概率分布,它描述了非负随机变量的行为。其概率密度函数 (PDF) 为:
```
f(x) = (x / σ^2) * exp(-x^2 / 2σ^2)
```
其中,x 是随机变量,σ 是尺度参数。瑞利分布的累积分布函数 (CDF) 为:
```
F(x) = 1 - exp(-x^2 / 2σ^2)
```
瑞利分布的形状参数仅为
多项式分解的教学创新:突破传统方法,点燃数学热情

# 1. 多项式分解的传统方法
多项式分解是代数中的基本操作,用于将复杂的多项式分解为更简单的因式。传统的多项式分解方法包括:
- **分解因式定理:**该定理指出,如果多项式 f(x) 在 x = a 处有根,则 (x - a) 是 f(x) 的因式。
- **Horner法:**该方法是一种逐步分解多项式的方法,通过反复将多项式除以 (x - a) 来确定根并分解多项式。
- **
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )