【基础】深度学习框架TensorFlow入门与实践
发布时间: 2024-06-25 03:14:20 阅读量: 66 订阅数: 125 

Tensorflow深度学习入门与实战
# 1. TensorFlow基础**
TensorFlow是一个开源机器学习库,用于创建和训练神经网络模型。它由Google Brain团队开发,并广泛用于各种机器学习任务,包括图像分类、自然语言处理和强化学习。
TensorFlow的核心概念是计算图,它表示模型的结构和数据流。图中的节点表示操作,例如矩阵乘法或激活函数,而边表示数据流。通过构建计算图,用户可以定义模型的结构和行为。
TensorFlow提供了广泛的工具和功能,包括:
* **变量和数据类型:**定义和管理模型中的变量,并支持各种数据类型。
* **流程控制:**使用条件语句和循环语句控制模型的执行流。
* **调试和优化:**提供工具和技术来调试模型,并优化其性能。
# 2. TensorFlow编程技巧
### 2.1 TensorFlow变量和数据类型
#### 2.1.1 变量定义和赋值
TensorFlow中的变量是可变的张量,用于存储和更新模型中的参数。要定义一个变量,可以使用`tf.Variable()`函数,它接受一个初始值和可选的数据类型作为参数。例如:
```python
import tensorflow as tf
# 定义一个浮点型变量
x = tf.Variable(3.0, dtype=tf.float32)
# 定义一个整型变量
y = tf.Variable(10, dtype=tf.int32)
```
变量可以被赋值,就像普通张量一样。例如:
```python
# 赋值给x变量
x.assign(5.0)
# 赋值给y变量
y.assign_add(5) # 等效于 y += 5
```
#### 2.1.2 数据类型和转换
TensorFlow支持多种数据类型,包括浮点型、整型和布尔型。每个数据类型都有自己的范围和精度。以下表格列出了TensorFlow支持的主要数据类型:
| 数据类型 | 范围 | 精度 |
|---|---|---|
| `tf.float32` | -3.4028235e+38 到 3.4028235e+38 | 7位有效数字 |
| `tf.float64` | -1.7976931348623157e+308 到 1.7976931348623157e+308 | 15位有效数字 |
| `tf.int32` | -2^31 到 2^31-1 | 无 |
| `tf.int64` | -2^63 到 2^63-1 | 无 |
| `tf.bool` | True 或 False | 无 |
可以通过`tf.cast()`函数将张量转换为不同的数据类型。例如:
```python
# 将x变量转换为int32类型
x_int = tf.cast(x, tf.int32)
```
### 2.2 TensorFlow流程控制
#### 2.2.1 条件语句
TensorFlow支持使用`tf.cond()`函数实现条件语句。该函数接受三个参数:一个布尔条件、一个真分支函数和一个假分支函数。例如:
```python
# 定义一个布尔条件
condition = tf.greater(x, 0)
# 定义真分支函数
true_fn = lambda: tf.add(x, 1)
# 定义假分支函数
false_fn = lambda: tf.subtract(x, 1)
# 使用tf.cond()函数实现条件语句
result = tf.cond(condition, true_fn, false_fn)
```
#### 2.2.2 循环语句
TensorFlow支持使用`tf.while_loop()`函数实现循环语句。该函数接受三个参数:一个循环条件、一个循环体函数和一个循环变量。例如:
```python
# 定义一个循环变量
i = tf.constant(0)
# 定义循环条件
condition = lambda i: tf.less(i,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了全面的 Python 人工智能知识,从基础概念到高级技术。它涵盖了广泛的主题,包括机器学习算法、监督和无监督学习、线性回归、逻辑回归、决策树、支持向量机、聚类算法、朴素贝叶斯分类器、主成分分析、正则化方法、特征工程、交叉验证、模型评估指标、偏差与方差、集成学习、特征选择、超参数调优、异常检测、强化学习、时间序列分析、文本分类、情感分析、图像处理、语音识别、推荐系统、神经网络、深度学习、深度强化学习、自然语言处理、目标检测、图像分割、自监督学习、对抗训练、风险敏感学习、模型蒸馏、无监督学习、多模态学习、自适应学习等。此外,专栏还提供了大量的实战演练,涵盖从数据清洗到模型训练的完整机器学习项目、聚类算法、分类算法、图像分类器、文本情感分析、图像风格转换、交通流量预测、人脸识别、电影推荐、智能游戏玩家、股票价格预测、交通信号识别等实际应用场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KEBA机器人高级攻略】:揭秘行业专家的进阶技巧

# 摘要
本论文对KEBA机器人进行全面的概述与分析,从基础知识到操作系统深入探讨,特别关注其启动、配置、任务管理和网络连接的细节。深入讨论了KEBA机器人的编程进阶技能,包括高级语言特性、路径规划及控制算法,以及机器人视觉与传感器的集成。通过实际案例分析,本文详细阐述了KEBA机器人在自动化生产线、高精度组装以及与人类协作方面的应用和优化。最后,探讨了KEBA机器人集成
【基于IRIG 106-19的遥测数据采集】:最佳实践揭秘
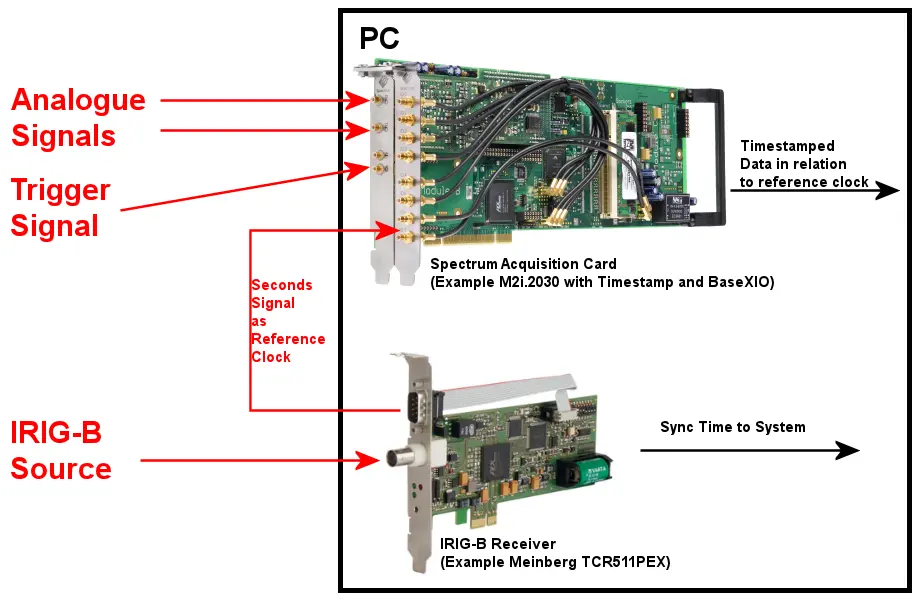
# 摘要
本文系统地介绍了IRIG 106-19标准及其在遥测数据采集领域的应用。首先概述了IRIG 106-19标准的核心内容,并探讨了遥测系统的组成与功能。其次,深入分析了该标准下数据格式与编码,以及采样频率与数据精度的关系。随后,文章详细阐述了遥测数据采集系统的设计与实现,包括硬件选型、软件框架以及系统优化策略,特别是实时性与可靠
【提升设计的艺术】:如何运用状态图和活动图优化软件界面
# 摘要
本文系统地探讨了状态图和活动图在软件界面设计中的应用及其理论基础。首先介绍了状态图与活动图的基本概念和组成元素,随后深入分析了在用户界面设计中绘制有效状态图和活动图的实践技巧。文中还探讨了设计原则,并通过案例分析展示了如何将这些图表有效地应用于界面设计。文章进一步讨论了状态图与活动图的互补性和结合使用,以及如何将理论知识转化为实践中的设计过程。最后,展望了面向未来的软
台达触摸屏宏编程故障不再难:5大常见问题及解决策略

# 摘要
台达触摸屏宏编程是一种为特定自动化应用定制界面和控制逻辑的有效技术。本文从基础概念开始介绍,详细阐述了台达触摸屏宏编程语言的特点、环境设置、基本命令及结构。通过分析常见故障类型和诊断方法,本文深入探讨了故障产生的根源,包括语法和逻辑错误、资源限制等。针对这
构建高效RM69330工作流:集成、测试与安全性的终极指南

# 摘要
本论文详细介绍了RM69330工作流的集成策略、测试方法论以及安全性强化,并展望了其高级应用和未来发展趋势。首先概述了RM69330工作流的基础理论与实践,并探讨了与现有系统的兼容性。接着,深入分析了数据集成的挑战、自动化工作流设计原则以及测试的规划与实施。文章重点阐述了工作流安全性设计原则、安全威胁的预防与应对措施,以及持续监控与审计的重要性。通过案例研究,展示了RM
Easylast3D_3.0速成课:5分钟掌握建模秘籍

# 摘要
Easylast3D_3.0是业界领先的三维建模软件,本文提供了该软件的全面概览和高级建模技巧。首先介绍了软件界面布局、基本操作和建模工具,然后深入探讨了材质应用、曲面建模以及动画制作等高级功能。通过实际案例演练,展示了Easylast3D_3.0在产品建模、角色创建和场景构建方面的应用。此外,本文还讨
【信号完整性分析速成课】:Cadence SigXplorer新手到专家必备指南
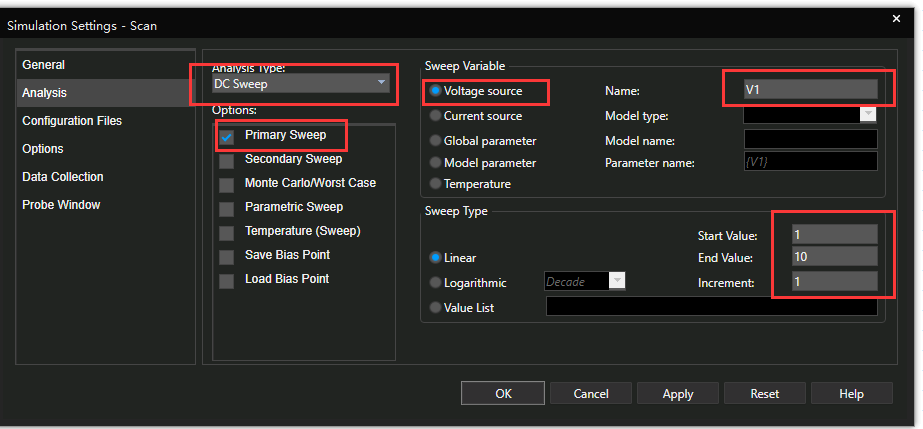
# 摘要
本论文旨在系统性地介绍信号完整性(SI)的基础知识,并提供使用Cadence SigXplorer工具进行信号完整性分析的详细指南。首先,本文对信号完整性的基本概念和理论进行了概述,为读者提供必要的背景知识。随后,重点介绍了Cadence SigXplorer界面布局、操作流程和自定义设置,以及如何优化工作环境以提高工作效率。在实践层面,论文详细解释了信号完整性分析的关键概念,包括信号衰
高速信号处理秘诀:FET1.1与QFP48 MTT接口设计深度剖析
# 摘要
高速信号处理与接口设计在现代电子系统中起着至关重要的作用,特别是在数据采集、工业自动化等领域。本文首先概述了高速信号处理与接口设计的基本概念,随后深入探讨了FET1.1接口和QFP48 MTT接口的技术细节,包括它们的原理、硬件设计要点、软件驱动实现等。接着,分析了两种接口的协同设计,包括理论基础、
【MATLAB M_map符号系统】:数据点创造性表达的5种方法

# 摘要
本文详细介绍了M_map符号系统的基本概念、安装步骤、符号和映射机制、自定义与优化方法、数据点创造性表达技巧以及实践案例分析。通过系统地阐述M_map的坐标系统、个性化符号库的创建、符号视觉效果和性能的优化,本文旨在提供一种有效的方法来增强地图数据的可视化表现力。同时,文章还探讨了M_map在科学数据可视化、商业分析及教育领域的应用,并对其进阶技巧和未来的发展趋势提出了预测和建议。
物流监控智能化:Proton-WMS设备与传感器集成解决方案
# 摘要
物流监控智能化是现代化物流管理的关键组成部分,有助于提高运营效率、减少错误以及提升供应链的透明度。本文概述了Proton-WMS系统的架构与功能,包括核心模块划分和关键组件的作用与互动,以及其在数据采集、自动化流程控制和实时监控告警系统方面的实际应用。此外,文章探讨了设备与传感器集成技术的原理、兼容性考量以及解决过程中的问题。通过分析实施案例,本文揭示了Proton-WMS集成的关键成功要素,并讨论了未来技术发展趋势和系统升级规划,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )