【Advanced】Signal Network Coding and Decoding in MATLAB
发布时间: 2024-09-14 06:37:07 阅读量: 30 订阅数: 71 
# 1. Introduction to Network Coding of Signals
Signal network coding is an innovative technology that breaks through traditional network transmission methods. By encoding and decoding signals within the network, it enhances the network's throughput and reliability. In signal network coding, information is no longer transmitted as independent packets but is instead encoded into network flows and routed and forwarded within the network. This method effectively utilizes network resources and reduces the likelihood of network congestion.
# 2. Theoretical Foundations of Network Coding
### 2.1 Basic Principles of Network Coding
The fundamental principle of network coding is to transform the traditional packet-based forwarding model into an information-based forwarding model. In traditional networks, routers merely forward received data packets without any processing. However, in network coding, routers can encode received data packets and send the encoded data packets.
For instance, consider a simple network with two source nodes and one destination node. Source nodes A and B send data packets x and y, respectively. In a traditional network, routers R1 and R2 would only forward the received data packets, as illustrated in the graph below:
```mermaid
graph LR
A[Source A] --> R1
B[Source B] --> R1
R1 --> R2
R2 --> Destination
```
In network coding, however, router R1 can encode the received data packets x and y and send the encoded data packet z. The destination node can then decode packet z to recover the original data packets x and y, as shown in the graph below:
```mermaid
graph LR
A[Source A] --> R1
B[Source B] --> R1
R1 --> R2
R2 --> Destination
R1[Encode(x, y)] --> z
Destination[Decode(z)] --> x, y
```
### 2.2 Mathematical Model of Linear Network Coding
Linear network coding is a specialized network coding technique that employs linear algebra to encode data packets. The mathematical model of linear network coding can be represented as:
```
y = Hx
```
Where:
* y is the encoded data packet
* H is the encoding matrix
* x is the original data packet
The encoding matrix H is an m x n matrix, where m is the number of encoded data packets, and n is the number of original data packets.
For example, consider a simple network with two source nodes and one destination node. Source node A and B send data packets x and y, respectively. The encoding matrix H of linear network coding can be represented as:
```
H = [1 0]
[0 1]
```
The encoded data packet z can be represented as:
```
z = Hx = [1 0] [x] = x
```
After receiving data packet z, the destination node can decode it and recover the original data packets x and y, as illustrated in the graph below:
```mermaid
graph LR
A[Source A] --> R1
B[Source B] --> R1
R1 --> R2
R2 --> Destination
R1[Encode(x, y)] --> z
Destination[Decode(z)] --> x, y
```
### 2.3 Performance Analysis of Network Coding
The performance analysis of network coding mainly focuses on throughput, delay, and reliability.
**Throughput**
Network coding can increase network throughput because it allows multiple data packets to be transmitted simultaneously. In traditional networks, if a data packet is lost, the entire transmission process must be restarted. In contrast, with network coding, even if a data packet is lost, the destination node can still recover the original data packets, thus improving network throughput.
**Delay**
Network coding can reduce network delay because it decreases the number of data packet transmissions. In traditional networks, a data packet must pass through multiple routers to reach the destination node. However, with network coding, data packets can pass through fewer routers, thereby reducing network delay.
**Reliability**
Network coding can enhance network reliability because it allows data packets to be transmitted via different paths. In traditional networks, if a router fail

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python降级实战秘籍】:精通版本切换的10大步骤与技巧
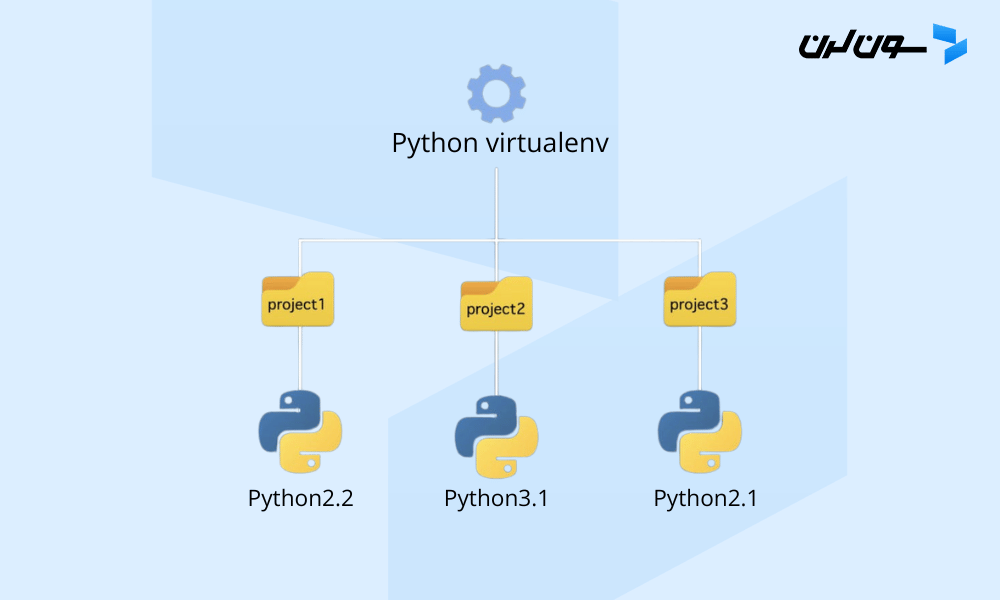
# 摘要
本文针对Python版本管理的需求与实践进行了全面探讨。首先介绍了版本管理的必要性与基本概念,然后详细阐述了版本切换的准备工作,包括理解命名规则、安装和配置管理工具以及环境变量的设置。进一步,本文提供了一个详细的步骤指南,指导用户如何执行Python版本的切换、降级操作,并提供实战技巧和潜在问题的解决方案。最后,文章展望了版本管理的进阶应用和降级技术的未来,讨论了新兴工具的发展趋势以及降级技术面临的挑战和创新方
C++指针解密:彻底理解并精通指针操作的终极指南
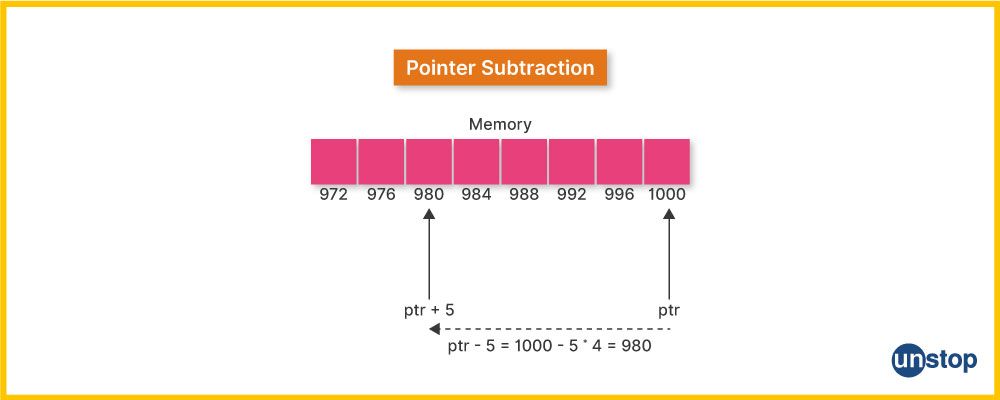
# 摘要
指针作为编程中一种核心概念,贯穿于数据结构和算法的实现。本文系统地介绍了指针的基础知识、与数组、字符串、函数以及类对象的关系,并探讨了指针在动态内存管理、高级技术以及实际应用中的关键角色。同时,本文还涉及了指针在并发编程和编译器优化中的应用,以及智能指针等现代替代品的发展。通过分析指针的多种用途和潜在问题,本文旨
CANoe J1939协议全攻略:车载网络的基石与实践入门

# 摘要
本文系统地介绍并分析了车载网络中广泛采用的J1939协议,重点阐述了其通信机制、数据管理以及与CAN网络的关系。通过深入解读J1939的消息格式、传输类型、参数组编号、数据长度编码及其在CANoe环境下的集成与通信测试,本文为读者提供了全面理解J1939协议的基础知识。此外,文章还讨论了J1
BES2300-L新手指南:7步快速掌握芯片使用技巧

# 摘要
BES2300-L芯片作为本研究的焦点,首先对其硬件连接和初始化流程进行了详细介绍,包括硬件组件准
数字电路设计者的福音:JK触发器与Multisim的终极融合
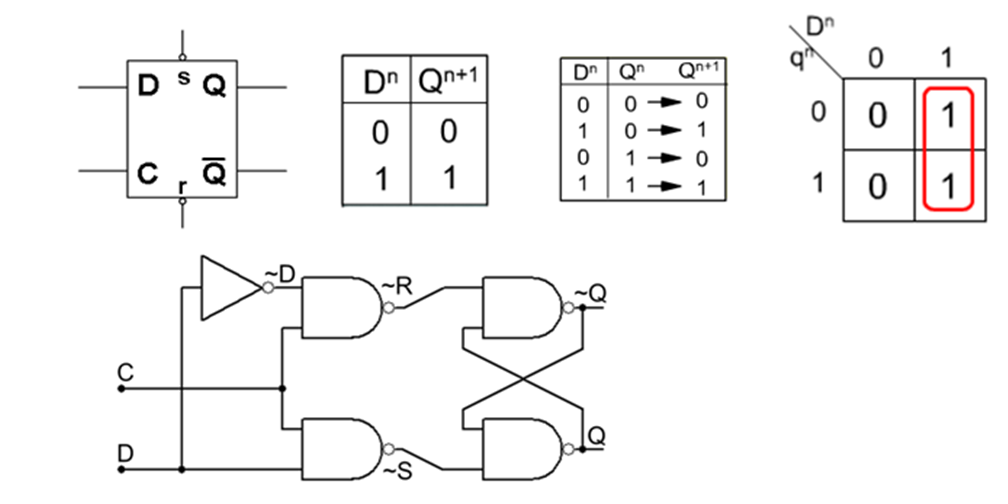
# 摘要
本文首先介绍了数字逻辑与JK触发器的基础知识,并深入探讨了JK触发器的工作原理、类型与特性,以及其在数字电路中的应用,如计数器和顺序逻辑电路设计。随后,文章转向使用Multisim仿真软件进行JK触发器设计与测试的入门知识。在此基础上,作者详细讲解了JK触发器的基本设计实践,包括电路元件的选择与搭建,以及多功能JK触发器设计的逻辑分析和功能验证。最后,文章提供了
企业级自动化调度:实现高可用与容错机制(专家秘籍)

# 摘要
企业级自动化调度系统是现代企业IT基础设施中的核心组成部分,它能够有效提升任务执行效率和业务流程的自动化水平。本文首先介绍了自动化调度的基础概念,包括其理论框架和策略算法,随后深入探讨了高可用性设计原理,涵盖多层架构、负载均衡技术和数据复制策略。第三章着重论述了容错机制的理论基础和实现步骤,包括故障检测、自动恢复以及FMEA分析。第四章则具体说明了自动化调度系统的设计与实践,包括平台选型、
【全面揭秘】:富士施乐DocuCentre SC2022安装流程(一步一步,轻松搞定)

# 摘要
本文全面介绍富士施乐DocuCentre SC2022的安装流程,从前期准备工作到硬件组件安装,再到软件安装与配置,最后是维护保养与故障排除。重点阐述了硬件需求、环境布局、软件套件安装、网络连接、功能测试和日常维护建议。通过详细步骤说明,旨在为用户提供一个标准化的安装指南,确保设备能够顺利运行并达到最佳性能,同时强调预防措施和故障处理的重要性,以减少设备故障率和延长使用寿命。
XJC-CF3600F保养专家

# 摘要
本文综述了XJC-CF3600F设备的概况、维护保养理论与实践,以及未来展望。首先介绍设备的工作原理和核心技术,然后详细讨论了设备的维护保养理论,包括其重要性和磨损老化规律。接着,文章转入操作实践,涵盖了日常检查、定期保养、专项维护,以及故障诊断与应急响应的技巧和流程。案例分析部分探讨了成功保养的案例和经验教训,并分析了新技术在案例中的应用及其对未来保养策略的
生产线应用案例:OpenProtocol-MTF6000的实践智慧

# 摘要
本文详细介绍了OpenProtocol-MTF6000协议的特点、数据交换机制以及安全性分析,并对实际部署、系统集成与测试进行了深入探讨。文中还分析了OpenProtocol-MTF6000在工业自动化生产线、智能物流管理和远程监控与维护中的应用案例,展示了其在多种场景下的解决方案与实施步骤。最后,本文对OpenProtocol-MTF6000未来的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )