【Basic】Speech Signal Recognition in MATLAB: Implementation of Speech Recognition Based on DTW and HMM
发布时间: 2024-09-14 06:05:02 阅读量: 67 订阅数: 72 

dtw.rar_DTW ALGORITHM_DTW using matlab_HMM_hmm matlab_voice reco
# 2.1 DTW Algorithm Principle
Dynamic Time Warping (DTW) is a time alignment algorithm used for sequences of different lengths. In speech recognition, it is employed to match input speech signals with pre-stored speech templates. The core idea of the DTW algorithm is to measure the similarity between two sequences by constructing a distance matrix and to find the optimal matching path using a dynamic programming algorithm.
**Calculation of the Distance Matrix:**
The DTW algorithm first computes the distance matrix between two sequences. Each element in the distance matrix represents the distance between corresponding elements in the two sequences. The distance metric can vary according to the specific application context, with common metrics including Euclidean distance, Manhattan distance, and cosine distance.
**Dynamic Programming Algorithm:**
After computing the distance matrix, the DTW algorithm uses a dynamic programming algorithm to find the optimal matching path. The algorithm starts from the top-left corner of the distance matrix and sequentially calculates the cumulative distance for each element. The cumulative distance represents the minimum distance from the start of the sequence to that element.
**Optimal Matching Path:**
With the dynamic programming algorithm, the DTW algorithm can find the path with the minimum cumulative distance from the start to the end of the sequence. This path represents the optimal match between the two sequences and can be used to align them.
# 2. Dynamic Time Warping (DTW) in Speech Recognition
### 2.1 DTW Algorithm Principle
Dynamic Time Warping (DTW) is an algorithm used for comparing sequences of different lengths, allowing sequences to be non-linearly aligned on the time axis. In speech recognition, the DTW algorithm is used to compare input speech signals with pre-stored speech templates to identify the content of the input speech.
The basic principle of the DTW algorithm is as follows:
1. **Create a distance matrix:** Calculate the distance between each element in the input sequence and the template sequence to form a distance matrix.
2. **Cumulative distance:** Sequentially accumulate the distance for each element starting from the top-left corner of the distance matrix, forming a cumulative distance matrix.
3. **Find the optimal path:** Starting from the bottom-right corner of the cumulative distance matrix, backtrack to the top-left corner, selecting the path with the smallest cumulative distance.
4. **Compute the DTW distance:** The cumulative distance of the optimal path is the DTW distance.
### 2.2 Implementation of the DTW Algorithm in Speech Recognition
In speech recognition, the steps to implement the DTW algorithm are as follows:
1. **Preprocess the speech signal:** Extract features from the speech signal, such as Mel-frequency cepstral coefficients (MFCC).
2. **Create speech templates:** Preprocess and store known speech samples as speech templates.
3. **Compute the DTW distance:** Calculate the DTW distance between the input speech signal and the speech template.
4. **Recognize speech:** Select the speech template with the smallest DTW distance as the recognition result.
**Code Block:**
```python
import numpy as np
def dtw(x, y):
"""
Calculate the DTW distance between two sequences.
Parameters:
x: Input sequence
y: Template sequence
Returns:
DTW distance
"""
# Create distance matrix
D = np.zeros((len(x), len(y)))
for i in range(len(x)):
for j in range(len(y)):
D[i, j] = np.linalg.norm(x[i] - y[j])
# Accumulate distance
for i in range(1, len(x)):
for j in range(1, len(y)):
D[i, j] += min(D[i-1, j], D[i, j-1], D[i-1, j-1])
# Find optimal path
path = []
i, j = len(x) - 1, len(y) - 1
while i >= 0 and j >= 0:
path.append((i, j))
if D[i-1, j] == min(D[i-1, j], D[i, j-1], D[i-1, j-1]):
i -= 1
elif D[i, j-1] == min(D[i-1, j], D[i, j-1], D[i-1, j-1]):
j -= 1
else:
i -= 1
j -= 1
# Calculate DTW distance
dtw_distance = D[len(x) - 1, len(y) - 1]
return dtw_distance
```
**Logical Analysis:**
This code implements the DTW algorithm to calculate the DTW distance between two sequences.
1. The `create_distance_matrix()` function creates a distance matrix where each element represents the distance between corresponding elements in the input sequence and the template sequence.
2. The `accumulate_distance()` function accumulates the elements in the distance matrix to form a cumulative distance matrix.
3. The `find_optimal_path()` function backtracks the cumulative distance matrix to find the path with the smallest DTW distance.
4. The `calculate_dtw_distance()` function returns the DTW distance.
**Parameter Description:*

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
性能优化秘方:提升现金管理系统与银行接口效率的关键

# 摘要
现金管理系统与银行接口的高效互动对于确保金融机构运营的顺畅至关重要。本文首先阐述了现金管理系统与银行接口的重要性,随后深入分析了性能优化的理论基础及其在现金管理系统架构中的应用,探讨了性能瓶颈的识
【光辐射测量设备】:专家推荐IT领域的最佳测量工具

# 摘要
光辐射测量设备在现代科技发展中扮演着重要角色,涉及从理论基础到实践应用的广泛领域。本文首先介绍了光辐射测量设备的原理与分类,并探讨了测量设备的理论基础,包括光辐射的基本概念和测量参数,以及传感器的工作原理和测量范围。随后,本文详细阐述了光辐射测量设备的实践应用,涵盖操作流程、数据分析、维护与校验等方面。在光辐射测量的实际应用领域中,本文选取了IT领域中的光纤通信、光电设备质量控
BMP文件格式深度解析:全面掌握像素处理与文件结构(权威指南)
# 摘要
BMP(位图)文件格式作为计算机图形领域的基础格式之一,广泛应用于图像存储和交换。本文全面概述了BMP文件格式的结构特点,深入分析了文件头和信息头的组成元素及其对图像数据的定义。此外,本研究详细探讨了像素数据的存储方式、图像色彩管理和高级特性,如位图信息头扩展和嵌入式文件处理。文章还通过实例展示了BMP图像处理实践,包括读写、转换、优化技术。最后,文章分析了BMP格式在现代应用中的挑战与机遇,展望了其未来发展趋势,特别是在新兴技术影响下和图形处理软件中的应用前景。
# 关键字
BMP文件格式;文件头结构;信息头分析;像素数据处理;色彩管理;图像转换优化;现代应用挑战
参考资源链接
3D Mine性能监控:实时追踪转子位置角,性能维护的秘诀

# 摘要
3D Mine性能监控是一项关键的技术,对于确保矿产行业的高效率和安全运营至关重要。本文首先概述了3D Mine系统的重要性以及性能监控的基本原理和方法。接着,深入探讨了转子位置角的实时追踪技术,包括理论基础、实时追踪系统的构建及实时数据处理和分析方法。第三章着重讨论了性能衰退的早期识别与维护策略的制定与实施,并提出了维护效果的评估与
【云端编码新机遇】:智能编码在云平台的应用与挑战

# 摘要
云端编码作为一种新兴的软件开发模式,正迅速成为行业发展的趋势。它在智能编码理论基础上,通过云平台的架构和编码环境优势,提升了开发效率,优化了成本和资源。本文分析了云端编码的兴起与发展,探
《Mathematica多核并行计算揭秘》:原理与案例深度剖析
# 摘要
本论文全面探讨了Mathematica在多核并行计算领域的应用与实践,从理论基础到实际编程技巧进行了深入分析。首先概述了并行计算的基本概念和优势,随后详细介绍了Mathematica的并行计算框架,包括并行任务的创建与管理、数据结构、内存管理和优化。论文还深入讨论了并行计算在数值分析、图像处理等实际问题
【编程实践】:JavaScript文件上传功能的绝对路径获取技术总结与剖析
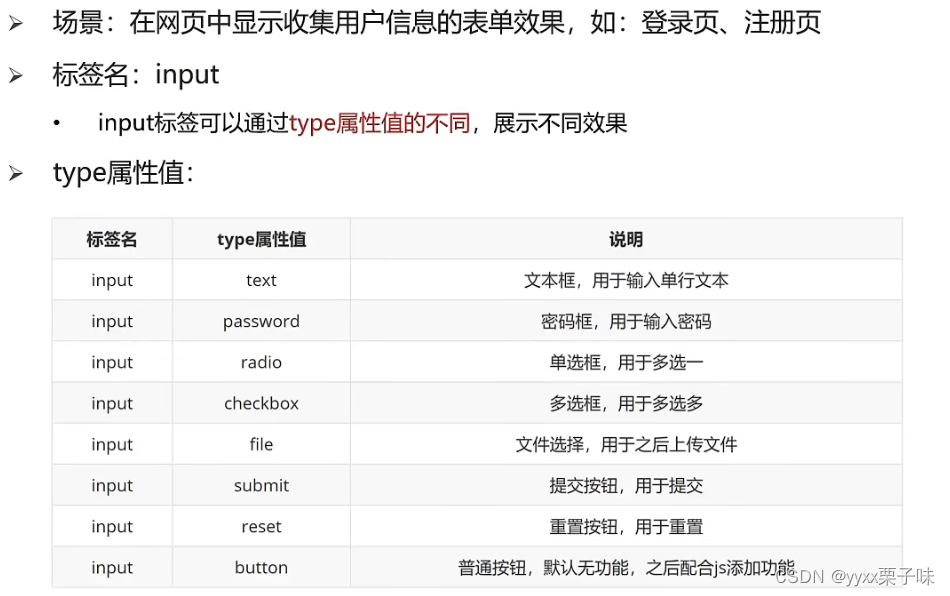
# 摘要
本文全面探讨了JavaScript文件上传功能的设计与实现,从基础理论、安全性、性能优化到安全性与兼容性解决方案进行了深入研究。通过分析HTTP协议、HTML5文件API以及前端事件处理技术,本文详细阐述了文件上传的技术原理和前端技术要求。同时,文章提供了获取绝对路径的实用技巧,解释了多文件处理、拖放API的使用方法,以及性能优化策略。为了应对不同浏览器的兼容性问题和提升
【负载均衡实战】:在ecology9.0架构中实现高效消息推送
# 摘要
本文系统介绍了负载均衡的基础概念及ecology9.0架构的特点。深入解析了负载均衡的理论基础,包括定义、分类、工作机制,以及消息推送机制和性能指标。文章详细阐述了如何在ecology9.0中设计和实施负载均衡策略,并通过配置优化提高消息推送效率。案例分析部分提供了负载均衡在ecology9.0中应用的背景、实施过程及成功案例。最
openTCS 5.9 API 使用指南:编程控制物流系统的终极指南

# 摘要
本文对openTCS 5.9 API进行了全面的介绍与解析,旨在帮助开发者深入理解其核心概念、架构以及如何在实际项目中进行应用。首先,概述了ope
ISPSoft控制逻辑检查清单:确保台达PLC逻辑正确性的5大步骤

# 摘要
本文综述了ISPSoft控制逻辑的基础知识、编写与验证方法、以及在工业PLC应用中的重要性。首先介绍了ISPSoft控制逻辑的基本概念和构成,然后详细探讨了在工业场景下PLC应用的逻辑特点和要求。随后,文中深入分析了编写和验证ISPSoft控制逻辑的具体步骤、测试方法和逻辑正确性的检查点,包括响应时间优化、逻辑健壮性分析和兼容性验证
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )