【基础】MATLAB中的奇异值分解(SVD)及应用
发布时间: 2024-05-22 12:20:32 阅读量: 255 订阅数: 246 

SVD算法的MATLAB实现代码
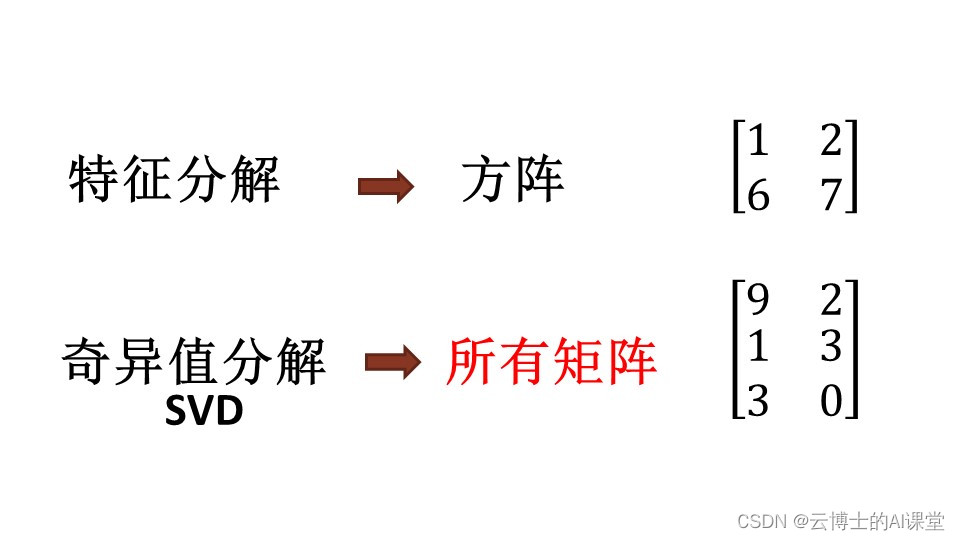
# 1. 奇异值分解(SVD)的理论基础**
奇异值分解(SVD)是一种强大的线性代数技术,用于将矩阵分解为三个矩阵的乘积:一个正交矩阵 U、一个对角矩阵 Σ 和另一个正交矩阵 V。
```python
import numpy as np
# 矩阵 A
A = np.array([[1, 2], [3, 4]])
# 奇异值分解
U, Sigma, Vh = np.linalg.svd(A, full_matrices=False)
```
在 SVD 中,Σ 对角矩阵包含矩阵 A 的奇异值,即 A 的特征值的平方根。U 和 V 是正交矩阵,包含 A 的左奇异向量和右奇异向量。
# 2. SVD在图像处理中的应用
### 2.1 图像降噪
#### 2.1.1 SVD原理在图像降噪中的应用
奇异值分解(SVD)是一种强大的数学工具,广泛应用于图像处理领域,其中一个重要的应用就是图像降噪。图像降噪的目的是去除图像中的噪声,提高图像质量。SVD可以有效地将图像分解为一组奇异值和奇异向量,从而分离出图像中的噪声成分。
具体来说,SVD将图像矩阵分解为三个矩阵的乘积:
```
A = U * Σ * V^T
```
其中:
- `A` 是原始图像矩阵
- `U` 是左奇异向量矩阵
- `Σ` 是奇异值矩阵,对角线上包含图像的奇异值
- `V^T` 是右奇异向量矩阵的转置
图像中的噪声通常集中在奇异值较小的奇异向量中。因此,通过截断奇异值,可以有效地去除噪声。
#### 2.1.2 降噪算法的实现
基于SVD的图像降噪算法可以如下实现:
```python
import numpy as np
from scipy.linalg import svd
# 读取图像
image = cv2.imread('noisy_image.jpg')
# 将图像转换为灰度图
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行SVD分解
U, Sigma, Vh = svd(gray_image, full_matrices=False)
# 截断奇异值
k = 100 # 截断奇异值的数量
Sigma_trunc = Sigma[:k, :k]
# 重构图像
denoised_image = np.dot(U, np.dot(Sigma_trunc, Vh))
# 显示降噪后的图像
cv2.imshow('Denoised Image', denoised_image)
cv2.waitKey(0)
```
**参数说明:**
- `k`:截断奇异值的数量,值越大,降噪效果越好,但图像细节损失也越大。
**代码逻辑分析:**
1. 读取图像并转换为灰度图。
2. 对灰度图进行SVD分解,得到奇异值矩阵 `Sigma`。
3. 截断奇异值,保留前 `k` 个奇异值。
4. 使用截断后的奇异值重构图像。
5. 显示降噪后的图像。
### 2.2 图像压缩
#### 2.2.1 SVD原理在图像压缩中的应用
SVD还可以用于图像压缩。图像压缩的目的是在保持图像质量的同时减小图像文件的大小。SVD可以将图像分解为一组奇异值和奇异向量,其中奇异值代表图像中最重要的信息。通过截断奇异值,可以有效地减少图像文件的大小。
#### 2.2.2 压缩算法的实现
基于SVD的图像压缩算法可以如下实现:
```python
import numpy as np
from scipy.linalg import svd
# 读取图像
image = cv2.imread('original_image.jpg')
# 将图像转换为灰度图
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行SVD分解
U, Sigma, Vh = svd(gray_image, full_matrices=False)
# 截断奇异值
k = 50 # 截断奇异值的数量
Sigma_trunc = Sigma[:k, :k]
# 重构图像
compressed_image = np.dot(U, np.dot(Sigma_trunc, Vh))
# 计算压缩率
compression_ratio = 100 * (1 - compressed_image.size / image.size)
# 保存压缩后的图像
cv2.imwrite('compressed_image.jpg', compressed_image)
print(f'压缩率:{compression_ratio:.2f}%')
```
**参数说明:**
- `k`:截断奇异值的数量,值越小,压缩率越高,但图像质量损失也越大。
**代码逻辑分析:**
1. 读取图像并转换为灰度图。
2. 对灰度图进行SVD分解,得到奇异值矩阵 `Sigma`。
3. 截断奇异值,保留前 `k` 个奇异值。
4. 使用截断后的奇异值重构图像。
5. 计算压缩率。
6. 保存压缩后的图像。
# 3. SVD在机器学习中的应用
### 3.1 降维
**3.1.1 SVD原理在降维中的应用**
奇异值分解(SVD)是一种强大的降维技术,它可以将高维数据投影到低维空间中,同时保留原始数据中最重要的信息。在机器学习中,降维经常用于:
- 减少特征数量,提高模型的可解释性和训练效率
- 提取数据中的潜在模式和结构
- 去除冗余和噪声,提高模型的泛化能力
SVD将一个矩阵分解为三个矩阵的乘积:
```
A = UΣV^T
```
其中:
- **A** 是原始矩阵
- **U** 是左奇异向量矩阵
- **Σ** 是奇异值对角矩阵
- **V** 是右奇异向量矩阵
奇异值对角矩阵中的奇异值表示了原始矩阵中各个特征向量的方差。通过保留最大的奇异值和对应的奇异向量,我们可以将数据投影到一个低维空间中,该空间保留了原始数据中最重要的方差。
### 3.1.2 降维算法的实现
使用SVD进行降维的算法如下:
1. 计算原始矩阵A的奇异值分解:
```python
U, Σ, V = np.linalg.svd(A)
```
2. 选择要保留的奇异值个数k:
```python
k = 10 # 保留最大的10个奇异值
```
3. 构造降维后的矩阵:
```python
A_reduced = U[:, :k] @ Σ[:k, :k] @ V[:k, :]
```
### 3.2 聚类
**3.2.1 SVD原理在聚类中的应用**
聚类是一种将数据点分组为相似组的技术。SVD可以通过以下方式用于聚类:
- 将数据投影到低维空间中,突出数据中的相似性和差异性
- 使用低维投影作为聚类算法的输入,提高聚类效率和准确性
### 3.2.2 聚类算法的实现
使用SVD进行聚类的算法如下:
1. 计算原始矩阵A的奇异值分解:
```python
U, Σ, V = np.linalg.svd(A)
```
2. 选择要保留的奇异值个数k:
```python
k = 10 # 保留最大的10个奇异值
```
3. 构造降维后的矩阵:
```python
A_reduced = U[:, :k] @ Σ[:k, :k] @ V[:k, :]
```
4. 使用聚类算法对降维后的矩阵进行聚类:
```python
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(A_reduced)
```
5. 根据聚类结果对原始数据进行分组:
```python
cluster_labels = kmeans.labels_
```
# 4. SVD在自然语言处理中的应用
### 4.1 文本相似度计算
#### 4.1.1 SVD原理在文本相似度计算中的应用
奇异值分解(SVD)在文本相似度计算中发挥着至关重要的作用。SVD将文本表示为一个矩阵,其中行表示文档,列表示单词。通过分解此矩阵,我们可以获得文档之间的相似性度量。
SVD将文本矩阵分解为三个矩阵:U、Σ和V。U矩阵包含文档的左奇异向量,Σ矩阵包含奇异值,V矩阵包含单词的右奇异向量。奇异值表示矩阵中每个奇异向量的重要性。
文本之间的相似性可以通过计算其奇异值分解的余弦相似性来衡量。余弦相似性是两个向量的点积与其范数的乘积之比。对于两个文档A和B,其余弦相似性为:
```
cos(θ) = (A · B) / (||A|| ||B||)
```
其中,A · B是A和B的点积,||A||和||B||分别是A和B的范数。
#### 4.1.2 相似度计算算法的实现
使用SVD计算文本相似度的算法如下:
1. **构建文本矩阵:**将文本表示为一个矩阵,其中行表示文档,列表示单词。
2. **计算SVD:**对文本矩阵进行奇异值分解,得到U、Σ和V矩阵。
3. **计算奇异值:**从Σ矩阵中提取奇异值。
4. **计算余弦相似性:**对于每个文档对,计算其奇异值分解的余弦相似性。
### 4.2 文本分类
#### 4.2.1 SVD原理在文本分类中的应用
SVD还可用于文本分类。文本分类的任务是将文本分配到预定义的类别中。SVD通过将文本表示为低维向量来实现这一目标。
通过对文本矩阵进行SVD,我们可以获得一个低秩近似矩阵,其中包含最重要的奇异向量。这个低秩近似矩阵可以用来表示文本的语义信息。
#### 4.2.2 分类算法的实现
使用SVD进行文本分类的算法如下:
1. **构建文本矩阵:**将文本表示为一个矩阵,其中行表示文档,列表示单词。
2. **计算SVD:**对文本矩阵进行奇异值分解,得到U、Σ和V矩阵。
3. **提取低秩近似矩阵:**从U和Σ矩阵中提取低秩近似矩阵。
4. **使用分类器:**使用分类器(如支持向量机或逻辑回归)对低秩近似矩阵进行训练。
5. **分类新文本:**将新文本表示为低秩近似矩阵,并使用训练好的分类器对其进行分类。
# 5.1 SVD在推荐系统中的应用
### 5.1.1 SVD原理在推荐系统中的应用
奇异值分解(SVD)在推荐系统中扮演着至关重要的角色,因为它可以将用户-物品交互矩阵分解为三个矩阵:用户矩阵、奇异值矩阵和物品矩阵。
* **用户矩阵:**表示每个用户对每个物品的喜好程度。
* **奇异值矩阵:**包含奇异值,表示用户和物品之间的相似性。
* **物品矩阵:**表示每个物品的特征。
通过对用户-物品交互矩阵进行SVD分解,我们可以获得用户的潜在特征和物品的潜在特征,从而可以对用户进行聚类,并根据用户的喜好为他们推荐物品。
### 5.1.2 推荐算法的实现
基于SVD的推荐算法通常遵循以下步骤:
1. **数据准备:**收集用户-物品交互数据,并将其转换为用户-物品矩阵。
2. **SVD分解:**对用户-物品矩阵进行SVD分解,得到用户矩阵、奇异值矩阵和物品矩阵。
3. **用户聚类:**根据用户矩阵对用户进行聚类,将具有相似喜好的用户分组。
4. **物品推荐:**对于每个用户,根据其所属的簇和物品矩阵,为其推荐与簇内其他用户喜好相似的物品。
```python
import numpy as np
from sklearn.decomposition import TruncatedSVD
# 加载用户-物品交互数据
data = np.loadtxt('user_item_interactions.csv', delimiter=',')
# 创建用户-物品矩阵
user_item_matrix = data.reshape((data.shape[0], -1))
# 进行SVD分解
svd = TruncatedSVD(n_components=10)
svd.fit(user_item_matrix)
# 获取用户矩阵、奇异值矩阵和物品矩阵
user_matrix = svd.components_
singular_values = svd.singular_values_
item_matrix = svd.transform(user_item_matrix)
# 对用户进行聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5)
kmeans.fit(user_matrix)
# 为每个用户推荐物品
for user_id in range(user_item_matrix.shape[0]):
cluster_id = kmeans.labels_[user_id]
similar_users = np.where(kmeans.labels_ == cluster_id)[0]
recommended_items = item_matrix[similar_users, :].mean(axis=0)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MATLAB智能算法合集专栏汇集了涵盖基础和进阶领域的MATLAB算法指南。该专栏涵盖了广泛的主题,从奇异值分解和积分求解等基础概念,到机器学习中的高级算法,如支持向量机、卷积神经网络和遗传算法。专栏还深入探讨了数值微分、偏微分方程求解、随机过程分析和图论算法等高级数值技术。此外,该专栏还提供了实战演练,展示了MATLAB在天气模式分析、流行病建模和推荐算法等实际应用中的应用。通过提供详细的解释、示例代码和仿真结果,该专栏旨在帮助读者掌握MATLAB的强大功能,并将其应用于各种科学、工程和数据科学领域。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Hyper-V安全秘籍:如何安全地禁用 Credential Guard与Device Guard
# 摘要
本文对Hyper-V虚拟化平台中的安全机制进行了综述,深入探讨了 Credential Guard 和 Device Guard 的工作原理与实施策略,并分析了在特定条件下禁用这些安全特性可能带来的必要性及风险。文章详细阐述了禁用 Credential Guard 和 Devi
【微机系统中断处理详解】:期末复习与实际应用案例
# 摘要
微机系统中断处理是计算机科学中的核心概念,涉及程序执行流程的高效管理与系统资源的优化配置。本文首先介绍了中断处理的基本理论,包括中断的定义、分类、优先级以及中断向量表和中断服务程序(ISR)的作用。随后,文章聚焦于中断服务程序的编写与调试技巧,探讨了中断优先级配置的实战方法,以及中断处理性能的评估与优化。此外,本文详细讨论了中断处理技术在多核CPU
RTL8370N数据传输优化秘籍:实现端到端的流畅通信

# 摘要
本论文详细介绍了RTL8370N芯片在数据传输中的应用,阐述了其基本理论和实践技巧。首先,概述了RTL8370N的数据传输基础和理论基础,包括数据传输的定义、速率测量方法、优化理论、拥塞控制原理以及网络架构等关键概念。接着,文章深入探讨了在RTL8370N数据传输过程中实用的流量控制、差错控制技术,以及实时性能优化方法。进一步地,本论文分析了无线传输、数据压缩加密技术以及多媒体数据
缓存冲突解决攻略:浏览器控制策略与更新秘籍

# 摘要
缓存是提高Web性能的关键技术之一,但其管理不当容易引发缓存冲突,影响用户体验和系统性能。本文首先探讨了缓存冲突的原理及其影响,随后分析了浏览器缓存控制策略,包括缓存的存储机制、HTTP头部控制、以及浏览器缓存控制实践。第三章提出了解决缓存冲突的技术方法,如缓存命名、版本管理、缓存清理与优化工具,以及缓存冲突的监控与报警。第四章介绍
【Aurora同步与异步传输深度对比】:揭秘性能优劣的关键因素
# 摘要
本文对Aurora数据同步机制进行了全面的探讨,详细介绍了同步与异步传输的技术原理及其特点。首先,概述了Aurora数据同步的基础概念和数据一致性要求,随后深入分析了同步传输的实时数据复制和事务日志同步策略,以及异步传输的消息队列技术与批量处理策略。进一步地,对比了同步与异步传输的性能差异,包括数据一致性和系统复杂度等方面,并探讨了在不同应用场景下的适用性。最后,提出了一系列优化传输性能的策略,
【Ubuntu18.04下的Qt应用部署】:解决插件问题的6个实战技巧
# 摘要
本文针对Ubuntu 18.04系统下Qt应用的开发、配置和部署进行了详细探讨。首先介绍了Ubuntu与Qt应用开发的基础知识,随后深入解析Qt插件系统的重要性及其在应用中的作用。文章重点讨论了在Ubuntu环境下如何配置Qt应用的运行环境,并对静态与动态链接的不同场景和选择进行了比较分析。实操章节提供
【指令译码器与指令集架构】:相互影响下的优化秘籍
# 摘要
指令译码器作为现代处理器架构中的关键组成部分,对于执行效率和硬件资源的优化起着至关重要的作用。本文首先介绍了指令
【编码器校准技巧】:3个关键步骤确保多摩川编码器精确校准

# 摘要
本文旨在深入探讨多摩川编码器的校准过程及其实践应用,从基础知识的铺垫到校准技巧的进阶分析,再到实践中案例的分享,形成了完整的编码器校准知识体系。文章首先阐述了校准准备的重要性,包括选择合适的工具和设备以及建立理想的校准环境。随后详细介绍了校准过程中编码器的初始设置、动态测试以及校准结果验证的具体步骤。通过对编
【项目管理视角】如何通过CH341T模块实现硬件集成的优化流程
# 摘要
CH341T模块作为一种常用的硬件接口芯片,其在硬件集成中的作用至关重要,涉及到硬件集成优化的理论基础、技术规格、项目管理及实际应用分析。本文全面探讨了CH341T模块在数据采集系统和通信接口扩展中的应用,同时详细剖析了硬件集成中的兼容性问题、故障排查和性能优化等挑战。在项目管理方面,本文研究了计划制定、进度控制、质量管理与成本控制等实践策略。此外,通过案例研究,展示了CH341T模块如何在特定硬件集成项目中发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )