【Fundamentals】Singular Value Decomposition (SVD) in MATLAB and Its Applications
发布时间: 2024-09-13 22:39:23 阅读量: 20 订阅数: 38 
# Singular Value Decomposition (SVD) in MATLAB and its Applications
## 1. Theoretical Foundation of Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD) is a powerful linear algebra technique used to factorize a matrix into the product of three matrices: an orthogonal matrix U, a diagonal matrix Σ, and another orthogonal matrix V.
```python
import numpy as np
# Matrix A
A = np.array([[1, 2], [3, 4]])
# Singular Value Decomposition
U, Sigma, Vh = np.linalg.svd(A, full_matrices=False)
```
In SVD, the Σ diagonal matrix contains the singular values of matrix A, which are the square roots of the eigenvalues of A. Matrices U and V are orthogonal and contain the left and right singular vectors of A, respectively.
## 2. Applications of SVD in Image Processing
### 2.1 Image Denoising
#### 2.1.1 Application of SVD Principle in Image Denoising
Singular Value Decomposition (SVD) is a potent mathematical tool extensively used in image processing, notably for image denoising. The goal of image denoising is to eliminate noise from images to improve their quality. SVD can effectively decompose an image into a set of singular values and singular vectors, thereby isolating the noisy components of the image.
Specifically, SVD decomposes the image matrix into the product of three matrices:
```
A = U * Σ * V^T
```
Where:
- `A` is the original image matrix
- `U` is the matrix of left singular vectors
- `Σ` is the singular value matrix, with the image's singular values along the diagonal
- `V^T` is the transpose of the matrix of right singular vectors
Noise in an image typically resides in the singular vectors corresponding to smaller singular values. Therefore, noise can be effectively removed by truncating the smaller singular values.
#### 2.1.2 Implementation of Denoising Algorithm
The SVD-based image denoising algorithm can be implemented as follows:
```python
import numpy as np
from scipy.linalg import svd
# Read the image
image = cv2.imread('noisy_image.jpg')
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Perform SVD decomposition
U, Sigma, Vh = svd(gray_image, full_matrices=False)
# Truncate the singular values
k = 100 # Number of singular values to truncate
Sigma_trunc = Sigma[:k, :k]
# Reconstruct the image
denoised_image = np.dot(U, np.dot(Sigma_trunc, Vh))
# Display the denoised image
cv2.imshow('Denoised Image', denoised_image)
cv2.waitKey(0)
```
**Parameter Explanation:**
- `k`: The number of singular values to truncate. The higher the value, the better the denoising effect, but the more image details are lost.
**Code Logic Analysis:**
1. Read the image and convert it to grayscale.
2. Perform SVD decomposition on the grayscale image to obtain the singular value matrix `Sigma`.
3. Truncate the singular values, retaining only the first `k` singular values.
4. Reconstruct the image using the truncated singular values.
5. Display the denoised image.
### 2.2 Image Compression
#### 2.2.1 Application of SVD Principle in Image Compression
SVD can also be used for image compression, the goal of which is to reduce the size of the image file while maintaining image quality. SVD decomposes the image into a set of singular values and singular vectors, where the singular values represent the most important information in the image. By truncating the singular values, the image file size can be effectively reduced.
#### 2.2.2 Implementation of Compression Algorithm
The SVD-based image compression algorithm can be implemented as follows:
```python
import numpy as np
from scipy.linalg import svd
# Read the image
image = cv2.imread('original_image.jpg')
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Perform SVD decomposition
U, Sigma, Vh = svd(gray_image, full_matrices=False)
# Truncate the singular values
k = 50 # Number of singular values to truncate
Sigma_trunc = Sigma[:k, :k]
# Reconstruct the image
compressed_image = np.dot(U, np.dot(Sigma_trunc, Vh))
# Calculate the compression ratio
compression_ratio = 100 * (1 - compressed_image.size / image.size)
# Save the compressed image
cv2.imwrite('compressed_image.jpg', compressed_image)
print(f'Compression ratio: {compression_ratio:.2f}%')
```
**Parameter Explanation:**
- `k`: The number of singular values to truncate. The smaller the value, the higher the compression ratio, but the more image quality is lost.
**Code Logic Analysis:**
1. Read the image and convert it to grayscale.
2. Perform SVD decomposition on the grayscale image to obtain the singular value matrix `Sigma`.
3. Truncate the singular values, retaining only the first `k` values.
4. Reconstruct the image using the truncated singular values.
5. Calculate the compression ratio.
6. Save the compressed image.
## 3. Applications of SVD in Machine Learning
### 3.1 Dimensionality Reduction
#### 3.1.1 Application of SVD Principle in Dimensionality Reduction
Singular Value Decomposition (SVD) is a powerful technique for dimensionality reduction that can project high-dimensional data onto a lower-dimensional space while preserving the most important information from the original data. In machine learning, dimensionality reduction is often used for:
- Reducing the number of features to enhance model interpretability and training efficiency
- Extracting latent patterns and structures from the data
- Removing redundancy and noise to improve the model's generalization ability
SVD decomposes a matrix into the product of three matrices:
```
A = UΣV^T
```
Where:
- **A** is the original matrix
- **U** is the matrix of left singular vectors
- **Σ** is the diagonal matrix of singular values
- **V** is the matrix of right singular vectors
The singular values in the diagonal matrix represent the variance of the original matrix's feature vectors. By retaining the largest singular values and their corresponding singular vectors, we can project the data onto a lower-dimensional space that preserves the most important variances of the original data.
#### 3.1.2 Implementation of Dimensionality Reduction Algorithm
The algorithm for dimensionality reduction using SVD is as follows:
1. Calculate the Singular Value Decomposition of the original matrix A:
```python
U, Σ, V = np.linalg.svd(A)
```
2. Choose the number of singular values to retain, k:
```python
k = 10 # Retain the top 10 singular values
```
3. Construct the reduced matrix:
```python
A_reduced = U[:, :k] @ Σ[:k, :k] @ V[:k, :]
```
### 3.2 Clustering
#### 3.2.1 Application of SVD Principle in Clustering
Clustering is a technique for grouping data points into similar clusters. SVD can be used for clustering in the following ways:
- Projecting data into a low-dimensional space that highlights similarities and differences in the data
- Using the low-dimensional projection as input for clustering algorithms to improve clustering efficiency and accuracy
#### 3.2.2 Implementation of Clustering Algorithm
The algorithm for clustering using SVD is as follows:
1. Calculate the Singular Value Decomposition of the original matrix A:
```python
U, Σ, V = np.linalg.svd(A)
```
2. Choose the number of singular values to retain, k:
```python
k = 10 # Retain the top 10 singular values
```
3. Construct the reduced matrix:
```python
A_reduced = U[:, :k] @ Σ[:k, :k] @ V[:k, :]
```
4. Use a clustering algorithm to cluster the reduced matrix:
```python
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(A_reduced)
```
5. Group the original data based on the clustering results:
```python
cluster_labels = kmeans.labels_
```
## 4. Applications of SVD in Natural Language Processing
### 4.1 Text Similarity Calculation
#### 4.1.1 Application of SVD Principle in Text Similarity Calculation
Singular Value Decomposition (SVD) plays a crucial role in calculating text similarity. SVD represents text as a matrix where rows indicate documents, and columns indicate words. By decomposing this matrix, we can obtain measures of similarity between documents.
SVD breaks down the text matrix into three matrices: U, Σ, and V. The U matrix contains the left singular vectors of documents, the Σ matrix contains the singular values, and the V matrix contains the right singular vectors of words. The singular values indicate the importance of each singular vector in the matrix.
The similarity between texts can be measured by calculating the cosine similarity of their Singular Value Decompositions. Cosine similarity is the ratio of the dot product of two vectors to the product of their norms. For two documents A and B, the cosine similarity is:
```
cos(θ) = (A · B) / (||A|| ||B||)
```
Where A · B is the dot product of A and B, and ||A|| and ||B|| are the norms of A and B, respectively.
#### 4.1.2 Implementation of Similarity Calculation Algorithm
The algorithm for using SVD to calculate text similarity is as follows:
1. **Construct the text matrix:** Represent text as a matrix where rows indicate documents and columns indicate words.
2. **Calculate SVD:** Perform Singular Value Decomposition on the text matrix to obtain U, Σ, and V matrices.
3. **Extract singular values:** Extract singular values from the Σ matrix.
4. **Calculate cosine similarity:** Compute the cosine similarity for each pair of documents using their Singular Value Decompositions.
### 4.2 Text Classification
#### 4.2.1 Application of SVD Principle in Text Classification
SVD can also be used for text classification, a task that involves assigning text to predefined categories. SVD accomplishes this by representing text as low-dimensional vectors.
By performing SVD on the text matrix, we can obtain a low-rank approximation matrix that contains the most important singular vectors. This low-rank approximation matrix can be used to represent the semantic information of text.
#### 4.2.2 Implementation of Classification Algorithm
The algorithm for text classification using SVD is as follows:
1. **Construct the text matrix:** Represent text as a matrix where rows indicate documents and columns indicate words.
2. **Calculate SVD:** Perform Singular Value Decomposition on the text matrix to obtain U, Σ, and V matrices.
3. **Extract the low-rank approximation matrix:** Extract the low-rank approximation matrix from the U and Σ matrices.
4. **Use a classifier:** Train a classifier (such as Support Vector Machine or Logistic Regression) on the low-rank approximation matrix.
5. **Classify new text:** Represent new text as a low-rank approximation matrix and classify it using the trained classifier.
## 5.1 Applications of SVD in Recommendation Systems
### 5.1.1 Application of SVD Principle in Recommendation Systems
Singular Value Decomposition (SVD) plays a vital role in recommendation systems as it can factorize the user-item interaction matrix into three matrices: the user matrix, the singular value matrix, and the item matrix.
***User matrix:** Represents each user's preference for each item.
***Singular value matrix:** Contains singular values that represent the similarity between users and items.
***Item matrix:** Represents the characteristics of each item.
By performing SVD on the user-item interaction matrix, we can obtain the latent features of users and items, allowing us to cluster users and recommend items to them based on their preferences.
### 5.1.2 Implementation of Recommendation Algorithm
The SVD-based recommendation algorithm typically follows these steps:
1. **Data Preparation:** Collect user-item interaction data and convert it into a user-item matrix.
2. **SVD Decomposition:** Perform SVD on the user-item matrix to obtain the user matrix, singular value matrix, and item matrix.
3. **User Clustering:** Cluster users based on the user matrix, grouping users with similar preferences.
4. **Item Recommendation:** For each user, recommend items based on the user's cluster and the item matrix, focusing on items similar to those preferred by others in the cluster.
```python
import numpy as np
from sklearn.decomposition import TruncatedSVD
# Load user-item interaction data
data = np.loadtxt('user_item_interactions.csv', delimiter=',')
# Create a user-item matrix
user_item_matrix = data.reshape((data.shape[0], -1))
# Perform SVD decomposition
svd = TruncatedSVD(n_components=10)
svd.fit(user_item_matrix)
# Obtain the user matrix, singular value matrix, and item matrix
user_matrix = ***ponents_
singular_values = svd.singular_values_
item_matrix = svd.transform(user_item_matrix)
# Cluster users
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5)
kmeans.fit(user_matrix)
# Recommend items for each user
for user_id in range(user_item_matrix.shape[0]):
cluster_id = kmeans.labels_[user_id]
similar_users = np.where(kmeans.labels_ == cluster_id)[0]
recommended_items = item_matrix[similar_users, :].mean(axis=0)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
数据不平衡到平衡:7种实用技巧优化你的机器学习训练集

# 1. 数据不平衡的问题概述
在机器学习和数据分析的实践中,数据不平衡是一个常见的问题,它指的是数据集中不同类别的样本数量相差悬殊。这种不平衡会直接影响模型训练的效果,导致模型对数量较多的类别过分敏感,而对数量较少的类别预测能力低下。在极端情况下,模型可能完全忽略掉少数类,只对多数类进行预测,这在许多应用领域,如医疗诊断、欺诈检测等场景中,后果可能是灾难性的。因此,理解和处理
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
自然语言处理中的独热编码:应用技巧与优化方法
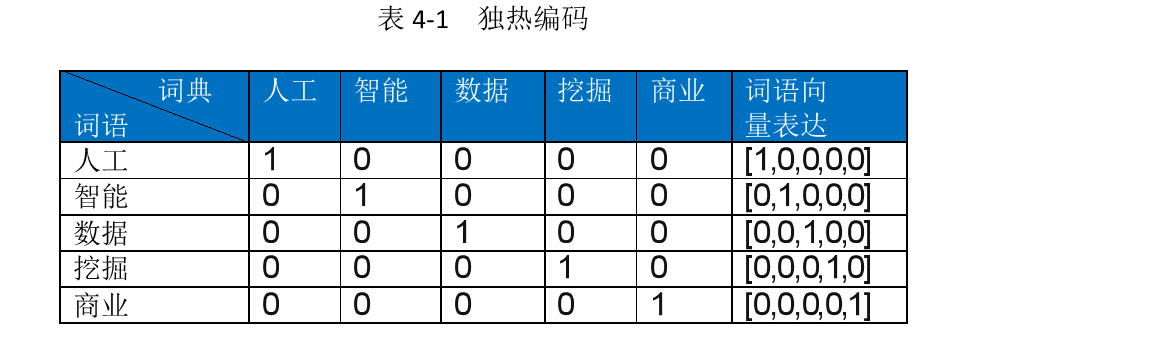
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )