【Advanced】Principal Component Regression (PCR) in MATLAB
发布时间: 2024-09-13 23:31:43 阅读量: 32 订阅数: 55 

Statistical evaluation of the tissue specified specific absorption rate using principal component regression
# [Advanced] Principal Component Regression (PCR) in MATLAB
## 1. Introduction to Principal Component Regression (PCR)
Principal Component Regression (PCR) is a multivariate statistical method that combines Principal Component Analysis (PCA) with regression analysis to handle high-dimensional datasets. It simplifies the data structure by projecting the original data onto a low-dimensional space of principal components while retaining information relevant to the response variables. PCR is widely applied in various fields, including spectral data analysis, bioinformatics data analysis, and chemometrics data analysis.
## 2. Theoretical Foundation of PCR
### 2.1 Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a dimensionality reduction technique that aims to project high-dimensional data onto a lower-dimensional space while retaining the maximum variance of the data. It is achieved through the following steps:
- **Covariance Matrix Computation:** Calculate the covariance matrix of the original data matrix, which contains the covariances between all variables.
- **Eigenvalue and Eigenvector Solution:** Perform eigen-decomposition on the covariance matrix to obtain a set of eigenvalues and corresponding eigenvectors.
- **Principal Component Extraction:** The eigenvalues represent the variance explained by each principal component, while the eigenvectors represent the directions of these components in the original data. By selecting the first k eigenvectors with the largest eigenvalues, the first k principal components are obtained.
### 2.2 Regression Analysis
Regression analysis is a statistical modeling technique used to predict the relationship between one or more dependent variables (response variables) and one or more independent variables (explanatory variables). The most common regression model is linear regression, with the equation:
```
y = b0 + b1x1 + b2x2 + ... + bnxn + ε
```
Where:
- y is the dependent variable
- x1, x2, ..., xn are independent variables
- b0 is the intercept
- b1, b2, ..., bn are regression coefficients
- ε is the error term
### 2.3 Mathematical Principles of PCR
PCR combines PCA with regression analysis through the following steps:
- **Principal Component Extraction:** Use PCA to extract principal components from the original data.
- **Regression Model Establishment:** Use the principal components as independent variables to establish a regression model to predict the dependent variable.
The mathematical principles of PCR are as follows:
```
y = b0 + b1PC1 + b2PC2 + ... + bnpCPn + ε
```
Where:
- y is the dependent variable
- PC1, PC2, ..., PCn are principal components
- b0 is the intercept
- b1, b2, ..., bn are regression coefficients
- ε is the error term
In this way, PCR can reduce high-dimensional data to a low-dimensional space while retaining information relevant to the dependent variable, thereby improving the predictive accuracy of the regression model.
## 3. Implementation of PCR in MATLAB
### 3.1 Data Preprocessing
Before performing PCR analysis, data preprocessing is necessary to ensure data quality and the accuracy of analysis results. Data preprocessing steps include:
- **Handling Missing Values:** The presence of missing values can affect analysis results. For missing values, the following methods can be applied:
- Delete samples or features containing missing values
- Fill missing values using interpolation or mean value methods
- **Handling Outliers:** Outliers can also affect analysis results. For outliers, the following methods can be applied:
- Delete outliers
- Transform outliers (e.g., logarithmic transformation)
- **Standardization or Normalization:** Standardization or norm***mon standardization methods include:
- Mean normalization: Subtract the mean of each feature and divide by its standard deviation
- Min-max normalization: Scale each feature to a range of [0, 1]
- **Feature Selection:** Feature selection can remove irrelevant or redundant features, ***mon feature selection methods include:
- Filter methods: Select features based on statistical information (e.g., variance, correlation) of features
- Wrapper methods: Select features iteratively to optimize model performance
- Embedded methods: Perform feature selection during model training
### 3.2 Principal Compone

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入解析WinPcap:网络数据包捕获机制与优化技巧
# 摘要
WinPcap作为一个广泛使用的网络数据包捕获库,为网络应用开发提供了强大的工具集。本文首先介绍了WinPcap的基本概念和安装配置方法,然后深入探讨了网络数据包捕获的基础知识,包括数据链路层与网络层解析,以及过滤器的原理与应用。接着,文章针对高级数据处理,阐述了数据包动态捕获、分析、统计和协议分析的方法,并提供了错误处理与调试的技巧。在实践章节
【MySQL性能优化】:从新手到专家的10大调整指南

# 摘要
本文详细探讨了MySQL数据库性能优化的各个方面,从基础架构到高级技术应用。首先介绍MySQL的性能优化理论基础,涵盖存储引擎、查询缓存、连接管理等关键组件,以及索引和SQL查询的优化策略。接着,文章转向性能监控和分析,讨论了性能监控工具、性能
【通信原理与2ASK系统的融合】:理论应用与实践案例分析

# 摘要
本论文首先对通信原理进行了概述,并详细探讨了2ASK(Amplitude Shift Keying)系统的理论基础,包括2ASK调制技术原理、性能分析、带宽需求以及硬件和软件实现。接着,通过多个应用场景,如无线通信、光通信和数字广播系统,分析了2ASK技术的实际应用和案例。文章还展望了通信系统技术的最新进展,探讨了2ASK技术的改进、创新及与其他技
【DeltaV OPC服务器深度优化】:数据流与同步的极致操控

# 摘要
本文系统性地介绍了DeltaV OPC服务器的基础知识、性能调优、高级功能实现以及未来发展趋势。首先,概述了DeltaV OPC服务器的基本概念和数据流同步机制。其次,深入探讨了性能调优的实践,包括系统配置和网络环境的影响,以及基于案例的性能提升分析。此外,本文还阐述了DeltaV OPC服务器在多
Jpivot大数据攻略:处理海量数据的12个策略
# 摘要
随着大数据时代的到来,Jpivot大数据处理的效率与质量成为企业和研究机构关注的焦点。本文概述了大数据处理的整体流程,从数据采集与预处理的策略制定,到海量数据的存储与管理,再到利用分布式计算框架进行数据分析与挖掘,最后通过数据可视化与报告展现结果并注重数据安全与隐私保护。通过对Jpivot大数据处理各阶段关键技术的
Altium Designer新手必读:函数使用全攻略
# 摘要
Altium Designer是一款广泛使用的电子设计自动化软件,其强大的函数功能是提高设计效率和实现设计自动化的关键。本文旨在对Altium Designer中的函数概念、类型、应用以及高级技巧进行系统性介绍。首先,概述了Altium Designer的基本函数基础,包括函数的定义、作用、常见类型以及内置和自定义函数的使用。随后,深入探讨了高级函数应用技巧,如参数传递、变量作用域、
Qt事件处理机制深入剖析

# 摘要
Qt框架以其跨平台特性和强大的事件处理机制,被广泛应用于GUI开发。本文深入探讨了Qt中的事件处理概念、理论基础以及实践技巧。从事件驱动编程模型到事件机制的理论基础,再到具体的编程实践,本文详细解析了Qt事件处理的各个方面。同时,文章深入分析了信号槽机制与事件之间的协同工作,并探讨了在Qt中实现异步事件处理、性能优化和跨平台兼容性的高级应用。通过对不同场景下的事件处理案例进行分析,本文总结了Qt事
PNOZ继电器应用优化:提高系统安全性能的实用技巧
# 摘要
PNOZ继电器是一种广泛应用于工业安全领域的关键设备,它通过一系列安全功能和特性来确保系统安全。本文详细介绍了PNOZ继电器的应用原理、在系统安全中的作用,以及与其他安全设备的协同工作。文章还探讨了继电器的配置与调试,优化实践,以及在不同行业中应用案例,以实现提升系统响应速度、稳定性和可靠性的目标。最后,本文展望了PNOZ继电器的未来发展趋势,关注新技术的融合和行业规范更新对继电器应
PN532 NFC芯片深度解析:从基础到应用
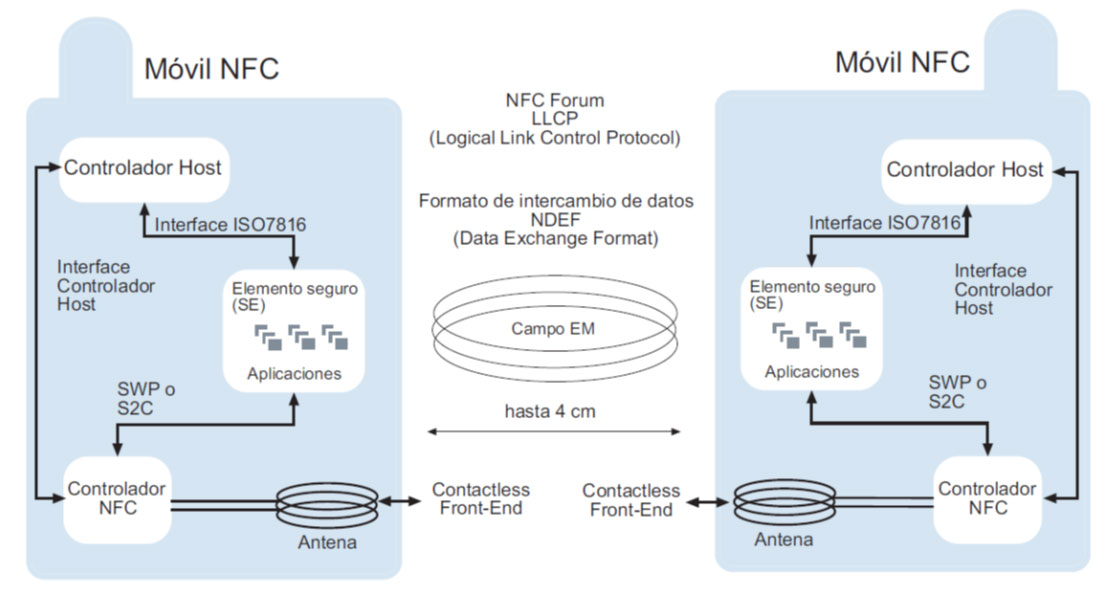
# 摘要
PN532 NFC芯片作为一款广泛应用于短距离无线通信的芯片,支持多种硬件接口和NFC通信协议。本文首先介绍了PN532 NFC芯片的基础特性,然后详细解析了其硬件接口如I2C、SPI、UART和HSU,以及NFC技术标准和通信模式。接着,文章转向编程基础,包括固件安装、配置寄存器和命令集,以及对不同类型NFC卡的读写操作实例。此外,文中还探
【故障诊断与预防】:LAT1173同步失败原因分析及预防策略

# 摘要
本文针对LAT1173同步失败现象进行了全面概述,深入探讨了其同步机制和理论基础,包括工作原理、同步过程中的关键参数以及同步失败模式和成功率影响因素。通过具体案例研究,本文剖析了硬件与软件层面导致同步失败的原因,并提出了一系列针对性的预防策略和故障处理措施。研究重点在于硬件维护升级和软件配置管理的最佳实践,旨在减少同步失败的风险,确保系统的稳定性和可靠性。
# 关键字
同步失败;理论分析;案例研究;故障预防;硬件维护;软件管理
参考资源链接:[STM3
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )