【Practical Exercise】Time Series Forecasting for Individual Household Power Prediction - ARIMA, xgboost, RNN
发布时间: 2024-09-14 00:36:30 阅读量: 21 订阅数: 38 
# Practical Exercise: Time Series Forecasting for Individual Household Power Prediction - ARIMA, xgboost, RNN
## 1. Introduction to Time Series Forecasting**
Time series forecasting is a technique for predicting future values based on time dependencies in historical data. It is widely used in various fields, including economics, finance, energy, and healthcare. Time series forecasting models aim to capture patterns and trends within the data and use this information to predict future values.
## 2. Time Series Forecasting Methods
Time series forecasting methods are statistical techniques that utilize historical data to predict future trends or values. In time series forecasting, there are many different methods available, each with its advantages and disadvantages. This chapter will introduce three widely used time series forecasting methods: ARIMA model, XGBoost model, and RNN model.
### 2.1 ARIMA Model
#### 2.1.1 Model Principle and Parameter Estimation
The ARIMA (AutoRegressive Integrated Moving Average) model is a classical method for time series forecasting, which predicts future values by identifying patterns and trends in the data. The ARIMA model consists of three parameters:
***p:** The order of the autoregressive part, indicating the linear relationship between the predicted value and the past p values.
***d:** The degree of differencing, meaning how many times the data needs to be differenced to remove non-stationarity.
***q:** The order of the moving average part, indicating the linear relationship between the predicted value and the past q error terms.
The parameters of the ARIMA model can be estimated using the Maximum Likelihood Estimation (MLE) method. The MLE method finds the optimal parameter values by minimizing the prediction error.
#### 2.1.2 Model Diagnostics and Improvement
Once the parameters of the ARIMA model have been estimated, various diagnostic checks can be used to assess the goodness of fit of the model. These checks include:
***Residual Analysis:** Checking if the residuals (the difference between predicted and actual values) are randomly distributed without patterns or trends.
***Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF):** Display patterns of autocorrelation and partial autocorrelation in the data, helping to determine the values of p and q.
***Information Criteria:** Such as Akaike's Information Criterion (AIC) and Bayesian Information Criterion (BIC), used to compare the goodness of fit between different ARIMA models.
If model diagnostics indicate a poor fit, the model can be improved by:
***Adjusting p, d, q parameters:** Trying different combinations of parameters to find the best fit.
***Introducing external variables:** Adding related external variables (such as weather or economic indicators) to the model.
***Using Seasonal ARIMA Model:** If the data shows seasonal patterns, a Seasonal ARIMA model can be used to capture these patterns.
### 2.2 XGBoost Model
#### 2.2.1 Model Principle and Hyperparameter Tuning
The XGBoost (eXtreme Gradient Boosting) model is a machine learning algorithm based on decision trees, which predicts future values by constructing a series of decision trees. The XGBoost model uses gradient boosting techniques, meaning it constructs a new decision tree in each iteration based on the errors of the previous iteration.
The XGBoost model has many hyperparameters, including:
***Learning Rate:** Controls the step size of each iteration.
***Depth of Trees:** Controls the complexity of the decision trees.
***Regularization Parameters:** To prevent the model from overfitting.
The hyperparameters of the XGBoost model can be tuned using methods such as grid search or Bayesian optimization.
#### 2.2.2 Model Evaluation and Feature Selection
The performance of the XGBoost model can be evaluated using the following metrics:
***Root Mean Squared Error (RMSE):** The average difference between predicted and actual values.
***Mean Absolute Error (MAE):** The average absolute difference between predicted and actual values.
***R-Squared:** A measure of how well the model fits, ranging from 0 to 1, where 1 indicates a perfect fit.
Feature selection is an important step in the XGBoost model, helping to identify the features most relevant to prediction. Feature selection techniques include:
***Filter Methods:** Scoring features based on their statistical information (such as variance or information gain).
***Wrapper Methods:** Iteratively adding or removing features to evaluate combinations of features.
***Embedded Methods:** Automatically performing feature selection duri

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
【线性回归时间序列预测】:掌握步骤与技巧,预测未来不是梦
# 1. 线性回归时间序列预测概述
## 1.1 预测方法简介
线性回归作为统计学中的一种基础而强大的工具,被广泛应用于时间序列预测。它通过分析变量之间的关系来预测未来的数据点。时间序列预测是指利用历史时间点上的数据来预测未来某个时间点上的数据。
## 1.2 时间序列预测的重要性
在金融分析、库存管理、经济预测等领域,时间序列预测的准确性对于制定战略和决策具有重要意义。线性回归方法因其简单性和解释性,成为这一领域中一个不可或缺的工具。
## 1.3 线性回归模型的适用场景
尽管线性回归在处理非线性关系时存在局限,但在许多情况下,线性模型可以提供足够的准确度,并且计算效率高。本章将介绍线
自然语言处理中的独热编码:应用技巧与优化方法
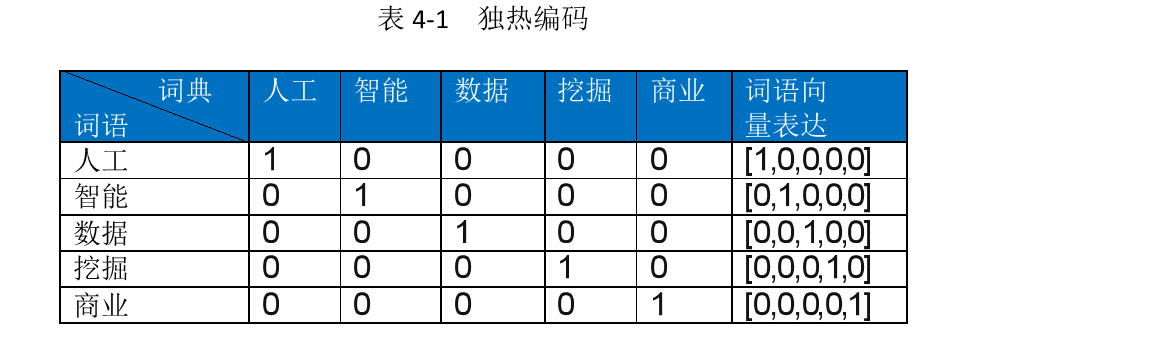
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【交互特征:模型性能的秘密武器】:7大技巧,从数据预处理到模型训练的完整流程

# 1. 数据预处理的必要性和方法
在数据科学的实践中,数据预处理是一个关键步骤,其目的是将原始数据转化为适合分析或建模的格式。数据预处理是必要的,因为现实世界中的数据常常包含不完整的记录、不一致的格式、甚至是噪声和异常值。没有经过适当处理的数据可能会导致模型无法准确学习到数据中的模式,进而影响到模型的预测性能。
数据预处理的方法主要
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )