【Advanced Level】Reinforcement Learning Algorithms: Q-Learning and Policy Gradient Methods in MATLAB
发布时间: 2024-09-14 00:05:25 阅读量: 38 订阅数: 52 
# [Advanced Series] Reinforcement Learning Algorithms: Q-Learning and Policy Gradient Methods in MATLAB
## 1. Basics of Reinforcement Learning**
Reinforcement learning is a paradigm of machine learning that enables agents to learn optimal behavior through interactions with their environment. Unlike supervised learning, reinforcement learning does not require labeled data but instead guides the agent's learning through rewards and penalties.
The core concept of reinforcement learning is the Markov decision process (MDP), which consists of the following elements:
***State (S):** The current state of the agent in the environment.
***Action (A):** The set of actions the agent can take.
***Reward (R):** The reward or penalty the agent receives after performing an action.
***State Transition Probability (P):** The probability of transitioning from one state to another after performing an action.
***Discount Factor (γ):** A factor used to balance immediate rewards with future rewards.
## 2. Q-Learning Algorithm**
### 2.1 Principles and Formulas of Q-Learning
Q-learning is a model-free reinforcement learning algorithm that guides an agent's behavior by learning the state-action value function (Q function). The Q function represents the expected long-term reward for taking a particular action in a given state.
The Q-learning update formula is as follows:
```python
Q(s, a) <- Q(s, a) + α * (r + γ * max_a' Q(s', a') - Q(s, a))
```
Where:
* `s`: Current state
* `a`: Current action
* `r`: Current reward
* `s'`: Next state
* `a'`: Next action
* `α`: Learning rate
* `γ`: Discount factor
### 2.2 Process and Steps of the Q-Learning Algorithm
The process of the Q-learning algorithm is as follows:
1. Initialize the Q function
2. Observe the current state `s`
3. Choose action `a` based on the current Q function
4. Execute action `a` and receive reward `r` and the next state `s'`
5. Update the Q function
6. Repeat steps 2-5 until the termination condition is met
### 2.3 MATLAB Implementation of the Q-Learning Algorithm
The implementation of the Q-learning algorithm in MATLAB is as follows:
```matlab
% Initialize the Q function
Q = zeros(num_states, num_actions);
% Set the learning rate and discount factor
alpha = 0.1;
gamma = 0.9;
% Training loop
for episode = 1:num_episodes
% Initialize state
s = start_state;
% Loop until reaching the terminal state
while ~is_terminal(s)
% Choose action based on the Q function
a = choose_action(s, Q);
% Execute action and receive reward and next state
[s_prime, r] = take_action(s, a);
% Update the Q function
Q(s, a) = Q(s, a) + alpha * (r + gamma * max(Q(s_prime, :)) - Q(s, a));
% Update state
s = s_prime;
end
end
```
*Code Logic Analysis:*
* The `choose_action` function selects an action based on the current Q function.
* The `take_action` function executes the action and receives the reward and next state.
* The `is_terminal` function checks if a state is a terminal state.
* `num_states` and `num_actions` represent the size of the state space and action space respectively.
* The training loop updates the Q function through multiple iterations until the termination condition is met.
## 3. Policy Gradient Methods
### 3.1 Derivation of the Policy Gradient Theorem
**Policy Gradient Theorem** is the foundation of policy gradient methods; it provides a formula for computing policy gradients, which are the gradients of changes in policy parameters with respect to the objective function. The derivation process of the policy gradient theorem is as follows:
**Objective Function:** The objective function in reinforcement learning is typically represented as the expected return:
```
J(θ) = E[R(θ)]
```
Where:
* θ is the policy parameters
* R(θ) is the return under policy θ
**Policy Gradient:** The policy gradient is defined as the gradient of the objective function J(θ) with respect to the policy parameters θ:
```
∇θJ(θ) = E[∇θR(θ)]
```
*Derivation Process:*
1. **Expectation Decomposition:** The expected value E[∇θR(θ)] can be decomposed into the sum of the expected values over all possible states and actions:
```
E[∇θR(θ)] = ∫∇θR(θ) p(s, a | θ) ds da
```
Where:
* p(s, a | θ) is the joint probability of state s and action a under policy θ
2. **Rewrite Joint Probability:** The joint probability p(s, a | θ) can be rewritten as the product of state probability p(s | θ) and action probability p(a | s, θ):
```
p(s, a | θ) = p(s | θ) p(a | s, θ)
```
3. **Substitute Gradient Formula:** Substitute the rewritten joint probability into the policy gradient formula:
```
∇θJ(θ) = ∫∇θR(θ) p(s | θ) p(a | s, θ) ds da
```
4. **Exchange Integral and Gradient:** Since the gradient operator is a linear operator, the integral and gradient can be exchanged:
```
∇θJ(θ) = ∫p(s | θ) ∇θ[R(θ) p(a | s, θ)] ds da
```
5. **Simplify Gradient:** Since R(θ) does not depend on the action a, its gradient is 0. Therefore, the gradient formula can be simplified to:
```
∇θJ(θ) = ∫p(s | θ) ∇θ[p(a | s, θ)] R(θ) ds da
```
*Conclusion:* This is the formula of the policy gradient theorem, which provides a method for computing policy gradients, i.e., the gradient of changes in policy parameters with respect to the objective function.
### 3.2 Variants of Policy Gradient Methods
There are various variants of policy gradient methods, each with its own advantages and disadvantages. Some common variants include:
**REINFORCE Algorithm:** The REINFORCE algorithm is the basic form of policy gradient methods; it directly uses the policy gradient th

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CANoe进阶技巧:深入Fast Data Exchange(FDX)应用】:实战专家揭秘

# 摘要
本文介绍了CANoe与Fast Data Exchange(FDX)的集成和应用,首先概述了FDX的基本原理及其相较于传统数据交换技术的优势。接着,详细探讨了FDX网络配置,包括网络通信的设置、数据流和消息处理。第三章阐述了FDX在CANoe中的高
华硕笔记本散热系统优化指南:维修与故障排除的终极手册

# 摘要
笔记本散热系统是保持设备稳定运行的关键,本文介绍了散热系统的基础知识,包括其工作原理、硬件和软件层面的优化策略。文章深入探讨了华硕笔记本散热系统的故障诊断方法,以及散热部件的实际操作和维修步骤。此外,本文还详细讨论了散热优化软件的应用以及如何通过预防措施和长期维护计划确保散热系统的高效运行。
# 关键字
散热系统;散热原理;优化策略;故障诊断;系统维护;散热软件
参
电子商务物流数据管理:如何打破信息孤岛,实现5步整合策略
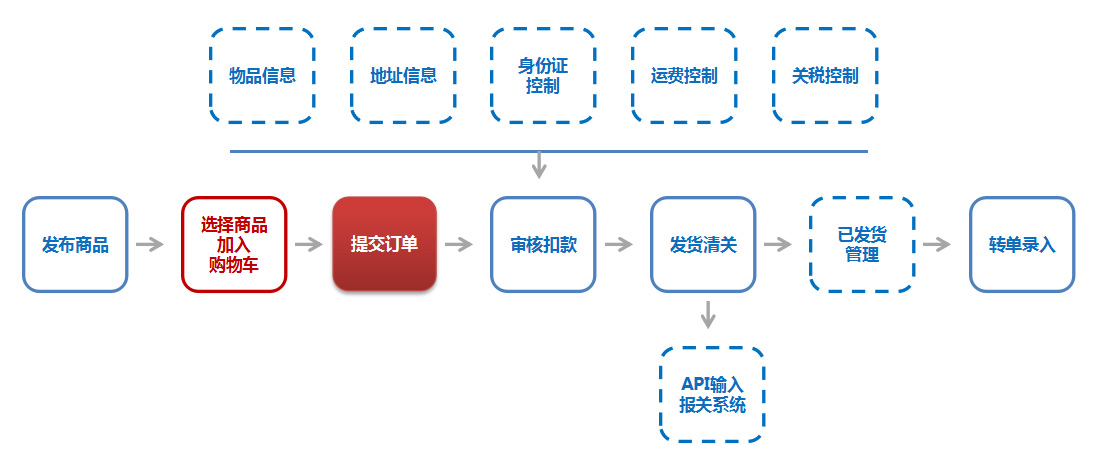
# 摘要
本文全面探讨了电子商务物流数据管理的现状与挑战,强调了信息孤岛对运营效率和客户体验的负面影响,并着重分析了数据整合在物流管理中的重要性。文章提出了一系列数据整合策略,包括识别与评估、标准化与整合、数据质量管理、系统与流程优化以及持续监控与改进,并讨论了技术选型、人员培训与实施路径。通过案例分析,本文进一步阐述了数据整合策略的实际应用和关键成功因素,同时识别了面临的挑战和应对策略。最后,文章展望了数据管理技术的未来发展方向
从蓝图到现实:智慧矿山实施的项目管理之道
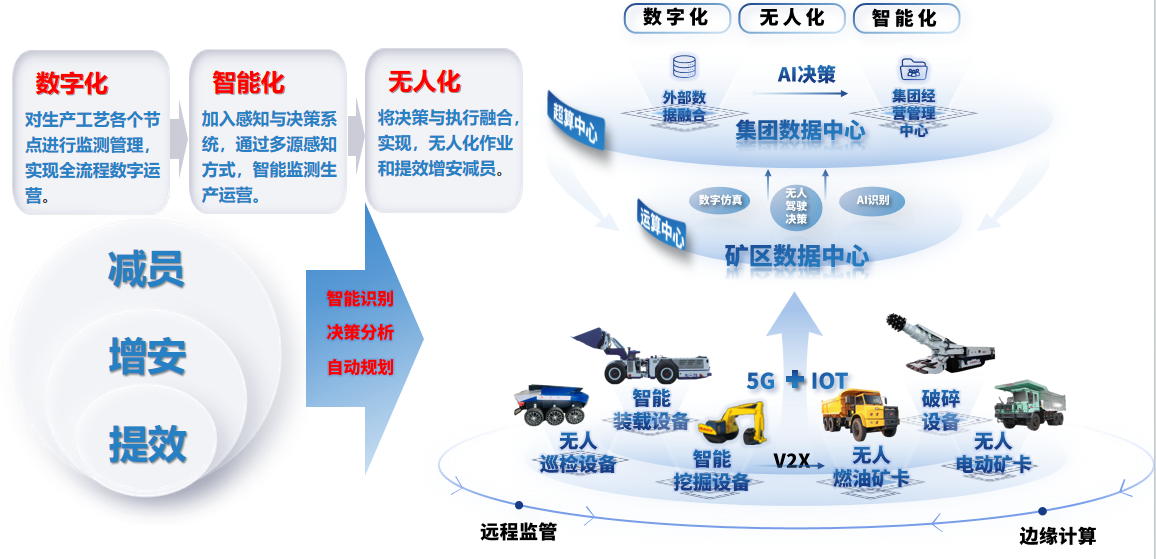
# 摘要
智慧矿山项目是矿业领域现代化转型的重要组成部分,涉及到矿山生产过程中的自动化、信息化和智能化。本文首先概述了智慧矿山项目的基本概念及其需求分析与设计的重要性。随后,详细探讨了智慧矿山项目的关键技术,如大数据、云计算、人工智能和机器学习在数据处理和自动化控制中的应用。文章还对智慧矿山项目管理策略进行了分析,涵盖项目规划、执行、风险管理和质量控制。案例分析部分对成功与失败的智慧矿山项
ROS导航与ORB-SLAM3:稠密地图与定位的融合之道

# 摘要
本文介绍了ROS (Robot Operating System) 导航系统与ORB-SLAM3稠密地图构建的整合。首先概述了ROS导航系统的关键组件与算法流程,以及ORB-SLAM3稠密地图构建的原理和过程。随后,探讨了稠密地图与定位数据的融合策略,并通过应
【VC++高效键盘消息处理】:从入门到精通的5大技巧

# 摘要
本文系统地探讨了VC++环境下键盘消息的处理机制,包括基本概念、消息捕获、消息解析以及优化技巧。通过对消息队列和消息循环的深入分析,阐述了如何高效地捕获和处理不同类型的键盘消息,以及如何实现消息过滤和预处理来提升性能。文中还讨论了键盘消息处理中可能遇到的无响应问题及其解决方案,并
【短信网关数据传输专家】:SGIP V1.3数据封装解封装技巧,一学就会

# 摘要
本文详细介绍了SGIP V1.3协议的概述、数据格式、封装与解封装技巧、在短信网关中的应用以及高级数据处理技巧和案例分析。首先概述了SGIP V1.3的协议特点及其数据结构,接着深入讲解了数据封装和解封装的技巧,包括消息类型、数据包构造和实战演练等。文章还探讨了SGIP V1.3在短信网关中的应用,涵盖了消息流程、数据传输管理、
全差分运算放大器精密匹配技术:克服5大挑战的解决方案
.PNG)
# 摘要
全差分运算放大器技术是模拟电路设计中的关键组成部分,对电路的性能有着显著的影响。本文从理论基础和实际应用两个层面深入探讨了全差分运算放大器匹配技术。首先介绍了匹配技术的重要性、工作原理及面临的挑战,然后详细阐述了实现精密匹配的技术方法、仿真测试及实际应用中的优化策略。进一步地,本文展望了匹配技术的创新应用和跨学科的解决方案,并探讨了匹配技术在物联网等新兴领域的发展趋势。通过案例研究与经验分享,本文为行业领导者提供了实施匹配技术的参考,并对
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )