【Advanced Section】In-depth Study of Neural Networks: Deep Belief Networks and Adaptive Learning Rate Techniques in MATLAB
发布时间: 2024-09-14 00:03:37 阅读量: 28 订阅数: 43 

Domain-Adversarial-Training-of-Neural-Networks:实施神经网络的领域高级训练
# Advanced Learning: In-Depth Study of Neural Networks in MATLAB - Deep Belief Networks and Adaptive Learning Rate Techniques
## 1. Neural Network Fundamentals**
A neural network is a machine learning algorithm inspired by biological neural systems, consisting of interconnected neurons. Neurons receive inputs, process them, and then produce outputs. Neural networks learn to recognize patterns and make predictions from data through training.
A neural network consists of multiple layers, each with several neurons. The input layer receives raw data, and the output layer produces predictions. Hidden layers, situated between the input and output layers, perform more complex computations.
The training process for neural networks involves adjusting the weights that connect neurons. These weights determine the sensitivity of neurons to inputs. Through the backpropagation algorithm, neural networks can learn to optimize weights to minimize prediction errors.
## 2. Deep Belief Networks
### 2.1 Structure and Principles of Deep Belief Networks
#### 2.1.1 Restricted Boltzmann Machines
A Restricted Boltzmann Machine (RBM) is an unsupervised learning model used to learn probability distributions from data. It consists of two layers of neurons: a visible layer and a hidden layer. The visible layer represents the input data, while the hidden layer represents abstract features of the data.
The energy function for an RBM is defined as:
```python
E(v, h) = -b^T v - c^T h - \sum_{i,j} v_i h_j w_{ij}
```
Where:
- v is the activation values of visible layer neurons
- h is the activation values of hidden layer neurons
- b and c are bias terms
- W is the weight matrix
The training goal for an RBM is to minimize the energy function by maximizing the joint probability distribution:
```python
p(v, h) = \frac{1}{Z} e^{-E(v, h)}
```
Where Z is the normalization factor.
#### 2.1.2 Hierarchical Structure of Deep Belief Networks
A Deep Belief Network (DBN) is composed of multiple stacked RBMs. Each RBM's hidden layer serves as the visible layer for the next RBM. This hierarchical structure allows the DBN to learn multi-layered abstract features of the data.
### 2.2 Training Deep Belief Networks
#### 2.2.1 Layer-wise Training
DBN training employs a greedy layer-wise training method. First, the first RBM is trained to learn the probability distribution of the input data. Then, the hidden layer of the first RBM is used as the visible layer for the second RBM and trained, and so on until all RBMs are trained.
#### 2.2.2 Backpropagation Algorithm
After layer-wise training, the entire DBN can be fine-tuned using the backpropagation algorithm. The backpropagation algorithm updates the DBN's weights and biases by computing gradients to minimize the loss function across the entire dataset.
```python
def backpropagation(X, y):
# Forward propagation
a = X
for layer in layers:
z = layer.forward(a)
a = layer.activation(z)
# Calculate the loss function
loss = loss_function(a, y)
# Backward propagation
grad_loss = loss_function.backward()
for layer in reversed(layers):
grad_z = layer.backward(grad_loss)
grad_loss = layer.weight_grad(grad_z)
# Update weights and biases
for layer in layers:
layer.weight -= learning_rate * grad_loss
layer.bias -= learning_rate * grad_loss
```
## 3.1 Principles and Types of Adaptive Learning Rate Techniques
During the training of neural networks, the learning rate is a crucial hyperparameter that dictates the step size for updating network weights. Traditional learning rates are typically fixed values, but a fixed learning rate often fails to achieve optimal results in practice. Adaptive learning rate techniques have emerged to dynamically adjust the learning rate based on gradient information during training, thereby improving training efficiency and generalization performance.
#### 3.1.1 Momentum Method
The momentum method is a classic adaptive learning rate technique that smooths the gradient direction by introducing a momentum term to accelerate convergence. The update formula for the momentum method is as follows:
```python
v_t = β * v_{t-1} + (1 - β) * g_t
w_t = w_{t-1} - α * v_t
```
Where:
- `v_t`: The momentum term, representing the smoothed value of the gradient direction
- `β`: The momentum decay coefficient, typically between 0 and 1
- `g_t`: The current gradient
- `w_t`: The network weights
- `α`: The learning rate
The principle of momentum is such that when the current gradient direction is consistent with the previous gradient direction, the momentum term accumulates, accelerating weight updates; whereas when the gradient direction changes, the momentum term decreases, smoothing weight updates.
#### 3.1.2 RMSProp
RMSProp (Root Mean Square Propagation) is an adaptive learning rate technique that dynamically adjusts the learning rate by computing the root mean square (RMS) of the gradients. The RMSProp update formula is as follows:
```python
s_t = β * s_{t-1} + (1 - β) * g_t^2
w_t = w_{t-1} - α * g_t / sqrt(s_t + ε)
```
Where:
- `s_t`: The gradient RMS
- `β`: The RMSProp decay coefficient, typically between 0 and 1
- `g_t`: The current gradient
- `w_t`: The network weights
- `α`: The learning rate
- `ε`: A smoothing term to prevent division by zero errors
The principle of RMSProp is that when gradients are large, the gradient RMS increases, thereby reducing the learning rate; when gradients are small, the gradient RMS decreases, thereby increasing the learning rate. This dynamic adjustment of the learning rate can prevent instability caused by excessively large learning rates while also accelerating convergence.
## 4. Implementation of Deep Belief Networks in MATLAB
### 4.1 Overview of the MATLAB Neural Network Toolbox
The MATLAB Neural Network Toolbox is a powerful package for developing, training, and deploying neural networks. It offers a variety of neural network types,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【文献综述构建指南】:如何打造有深度的文献框架

# 摘要
文献综述是学术研究中不可或缺的环节,其目的在于全面回顾和分析已有的研究成果,以构建知识体系和指导未来研究方向。本文系统地探讨了文献综述的基本概念、重要性、研究方法、组织结构、撰写技巧以及呈现与可视化技巧。详细介绍了文献搜索策略、筛选与评估标准、整合与分析方法,并深入阐述了撰写前的准备工作、段落构建技
MapSource高级功能探索:效率提升的七大秘密武器

# 摘要
本文对MapSource软件的高级功能进行了全面介绍,详细阐述了数据导入导出的技术细节、地图编辑定制工具的应用、空间分析和路径规划的能力,以及软件自动化和扩展性的实现。在数据管理方面,本文探讨了高效数据批量导入导出的技巧、数据格式转换技术及清洗整合策略。针对地图编辑与定制,本文分析了图层管理和标注技术,以及专题地图创建的应用价值。空间分析和路径规划章节着重介绍了空间关系分析、地形
Profinet通讯协议基础:编码器1500通讯设置指南
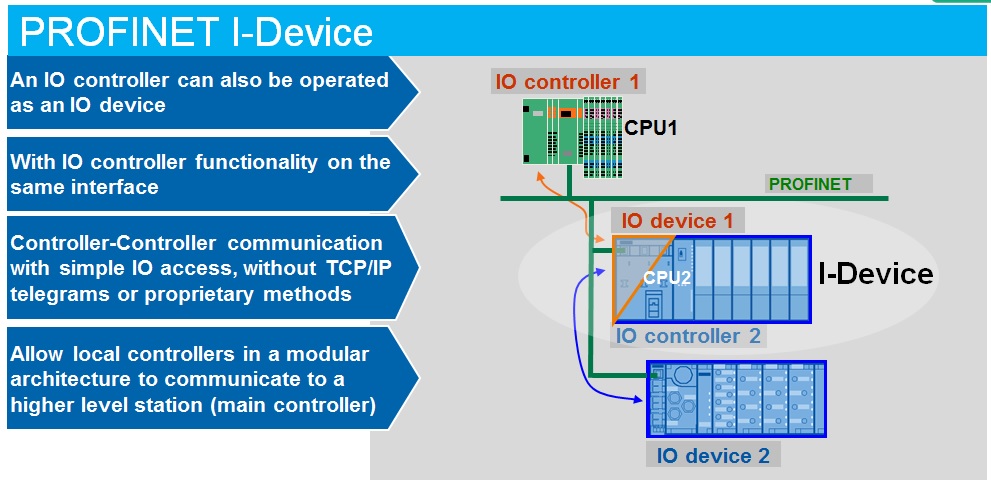
# 摘要
Profinet通讯协议作为工业自动化领域的重要技术,促进了编码器和其它工业设备的集成与通讯。本文首先概述了Profinet通讯协议和编码器的工作原理,随后详细介绍了Profinet的数据交换机制、网络架构部署、通讯参数设置以及安全机制。接着,文章探讨了编码器的集成、配置、通讯案例分析和性能优化。最后,本文展望了Profinet通讯协议的实时通讯优化和工业物联网融合,以及编码
【5个步骤实现Allegro到CAM350的无缝转换】:确保无瑕疵Gerber文件传输

# 摘要
本文详细介绍了从Allegro到CAM350的PCB设计转换流程,首先概述了Allegr
PyCharm高效调试术:三分钟定位代码中的bug

# 摘要
PyCharm作为一种流行的集成开发环境,其强大的调试功能是提高开发效率的关键。本文系统地介绍了PyCharm的调试功能,从基础调试环境的介绍到调试界面布局、断点管理、变量监控以及代码调试技巧等方面进行了详细阐述。通过分析实际代码和多线程程序的调试案例,本文进一步探讨了PyCharm在复杂调试场景下的应用,包括异常处理、远程调试和性能分析。最后,文章深入讨论了自动化测试与调试
【编程高手必备】:整数、S5Time与Time精确转换的终极秘籍

# 摘要
本文深入探讨了整数与时间类型(S5Time和Time)转换的基础知识、理论原理和实际实现技巧。首先介绍了整数、S5Time和Time在计算机系统中的表示方法,阐述了它们之间的数学关系及转换算法。随后,文章进入实践篇,展示了不同编程语言中整数与时间类型的转换实现,并提供了精确转换和时间校准技术的实例。最后,文章探讨了转换过程中的高级计算、优化方法和错误处理策略,并通过案例研究,展示了
【PyQt5布局专家】:网格、边框和水平布局全掌握
# 摘要
PyQt5是一个功能强大的跨平台GUI工具包,本论文全面探讨了PyQt5中界面布局的设计与优化技巧。从基础的网格布局到边框布局,再到水平和垂直布局,本文详细阐述了各种布局的实现方法、高级技巧、设计理念和性能优化策略。通过对不同布局组件如QGridLayout、QHBoxLayout、QVBoxLayout以及QStackedLayout的深入分析,本文提供了响应式界面设计、复杂用户界面创建及调试的实战演练,并最终深入探讨了跨平台布局设计的最佳实践。本论文旨在帮助开发者熟练掌握PyQt5布局管理器的使用,提升界面设计的专业性和用户体验。
# 关键字
PyQt5;界面布局;网格布局;边
【音响定制黄金法则】:专家教你如何调校漫步者R1000TC北美版以获得最佳音质
# 摘要
本论文全面探讨了音响系统的原理、定制基础以及优化技术。首先,概述了音响系统的基本工作原理,为深入理解定制化需求提供了理论基础。接着,对漫步者R1000TC北美版硬件进行了详尽解析,展示了该款音响的硬件组成及特点。进一步地,结合声音校准理论,深入讨论了校准过程中的实践方法和重要参数。在此基础上,探讨了音质调整与优化的技术手段,以达到提高声音表现的目标。最后,介绍了高级调校技巧和个性化定制方法,为用户提供更加个性化的音响体验。本文旨在为音响爱好者和专业人士提供系统性的知识和实用的调校指导。
# 关键字
音响系统原理;硬件解析;声音校准;音质优化;调校技巧;个性化定制
参考资源链接:[
【微服务架构转型】:一步到位,从单体到微服务的完整指南
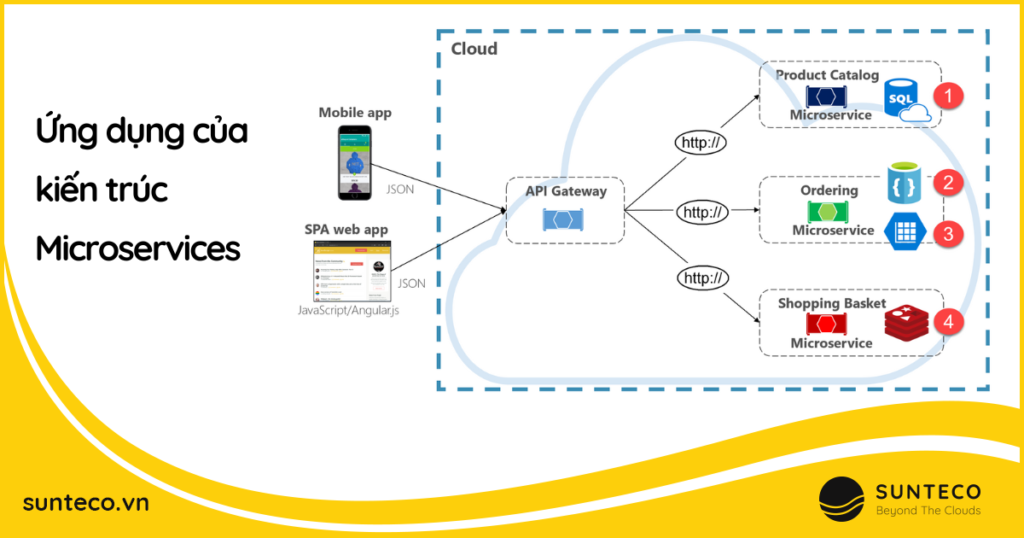
# 摘要
微服务架构是一种现代化的软件开发范式,它强调将应用拆分成一系列小的、独立的服务,这些服务通过轻量级的通信机制协同工作。本文首先介绍了微服务架构的理论基础和设计原则,包括组件设计、通信机制和持续集成与部署。随后,文章分析了实际案例,探讨了从单体架构迁移到微服务架构的策略和数据一致性问题。此
金蝶K3凭证接口权限管理与控制:细致设置提高安全性
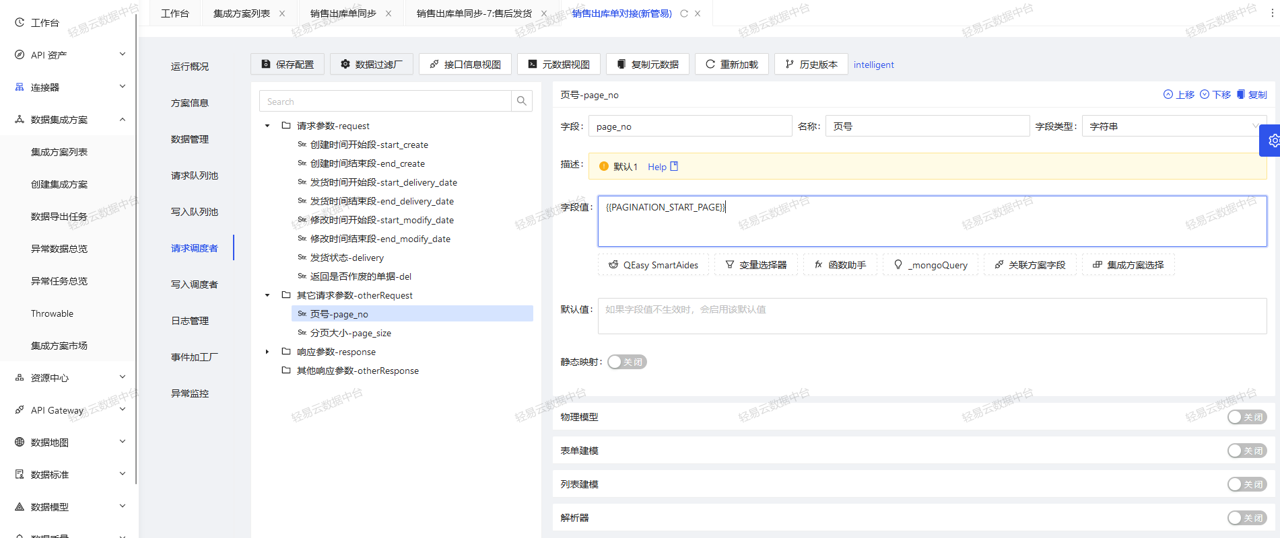
# 摘要
金蝶K3凭证接口权限管理是确保企业财务信息安全的核心组成部分。本文综述了金蝶K3凭证接口权限管理的理论基础和实践操作,详细分析了权限管理的概念及其在系统中的重要性、凭证接口的工作原理以及管理策略和方法。通过探讨权限设置的具体步骤、控制技巧以及审计与监控手段,本文进一步阐述了如何提升金蝶K3凭证接口权限管理的安全性,并识别与分析潜在风险。本文还涉及了技术选型与架构设计、开发配置实践、测试和部署策略,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )